
1. Overview
Spring JPA and Hibernate provide a powerful tool for seamless database communication. However, as clients delegate more control to the frameworks, including query generation, the result might be far from what we expect.
There’s usually confusion about what to use, Lists or Sets with to-many relationships. Often, this confusion is amplified by the fact that Hibernate uses similar names for its bags, lists, and sets but with slightly different meanings behind them.
In most cases, Sets are more suitable for one-to-many or many-to-many relationships. However, they have particular performance implications that we should be aware of.
In this tutorial, we’ll learn the difference between Lists and Sets in the context of entity relationships and review several examples of different complexities. Also, we’ll identify the pros and cons of each approach.
2. Testing
We’ll be using a dedicated library to test the number of requests. Checking the logs isn’t a good solution as it’s not automated and might work only on simple examples. When requests generate tens and hundreds of queries, using logs isn’t efficient enough.
First of all, we need the io.hypersistence. Note that the number in the artifact ID is the Hibernate version:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-utils-hibernate-63</artifactId>
<version>3.7.0</version>
</dependency>
Additionally, we’ll be using the util library for log analysis:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>db-util</artifactId>
<version>1.0.7</version>
</dependency>
We can use these libraries for exploratory tests and cover crucial parts of our application. This way, we ensure that changes in the entity classes don’t create some invisible side effects in the query generation.
We should wrap our data source with the provided utilities to make it work. We can use BeanPostProcessor to do this:
@Component
public class DataSourceWrapper implements BeanPostProcessor {
public Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof DataSource originalDataSource) {
ChainListener listener = new ChainListener();
SLF4JQueryLoggingListener loggingListener = new SLF4JQueryLoggingListener();
loggingListener.setQueryLogEntryCreator(new InlineQueryLogEntryCreator());
listener.addListener(loggingListener);
listener.addListener(new DataSourceQueryCountListener());
return ProxyDataSourceBuilder
.create(originalDataSource)
.name("datasource-proxy")
.listener(listener)
.build();
}
return bean;
}
}
The rest is simple. In our tests, we’ll use SQLStatementCountValidator to validate the number and the type of the queries.
3. Domain
To make the examples more relevant and easier to follow, we’ll be using a model for a social networking website. We’ll have different relationships between groups, users, posts, and comments.
However, we’ll build up the complexity step by step, adding entities to highlight the differences and the performance effect. This is important as simple models with only a few relationships won’t provide a complete picture. At the same time, overly complex ones might overwhelm the information, making it hard to follow.
For these examples, we’ll use only the eager fetch type for to-many relationships. In general, Lists and Sets behave similarly when we use lazy fetch.
In the visuals, we’ll be using Iterable as a to-many field type. This is done only for brevity, so we don’t need to repeat the same visuals for Lists and Sets. We’ll explicitly define a dedicated type in each section and show it in the code.
4. Users and Posts
First of all, let’s consider only the part of our domain. Here, we’ll be taking into account only users and posts:
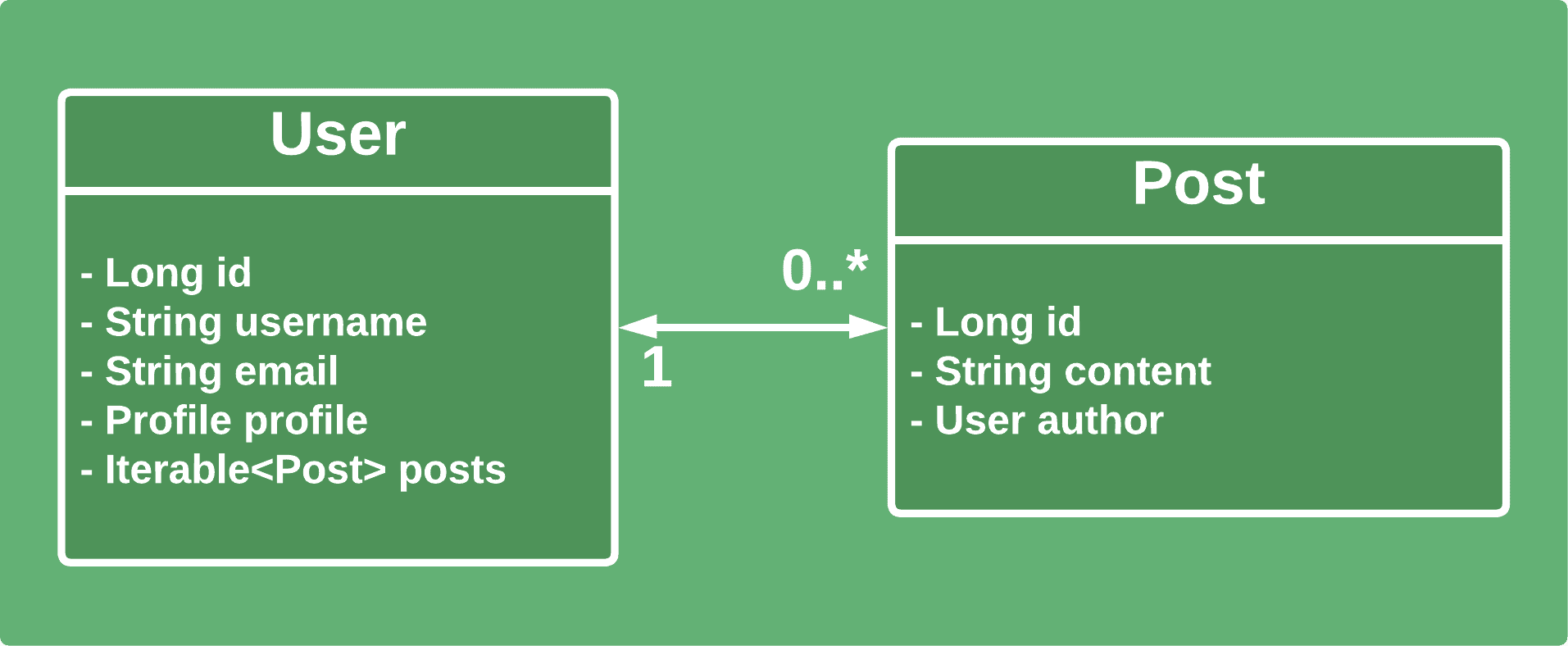
For the first example, we’ll have a simple bidirectional relationship between users and posts. Users can have many posts. At the same time, a post can have only one user as an author.
4.1. Lists and Sets Joins
Let’s check the behavior of the queries when we request only one user. We’ll consider the following two scenarios for Set and List:
@Data
@Entity
public class User {
// Other fields
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
protected List<Post> posts;
}Set-based User looks quite similar:
@Data
@Entity
public class User {
// Other fields
@OneToMany(cascade = CascadeType.ALL, mappedBy = "author", fetch = FetchType.EAGER)
protected Set<Post> posts;
}While fetching a User, Hibernate generates a single query with LEFT JOIN to get all the information in one go. This is true for both cases:
SELECT u.id, u.email, u.username, p.id, p.author_id, p.content
FROM simple_user u
LEFT JOIN post p ON u.id = p.author_id
WHERE u.id = ?While we have only one query, the user’s data will be repeated for each row. This means that we’ll see the ID, email, and username as many times as many posts a particular user has:
| u.id | u.email | u.username | p.id | p.author_id | p.content |
|---|---|---|---|---|---|
| 101 | user101@email.com | user101 | 1 | 101 | “User101 post 1” |
| 101 | user101@email.com | user101 | 2 | 101 | “User101 post 2” |
| 102 | user102@email.com | user102 | 3 | 102 | “User102 post 1” |
| 102 | user102@email.com | user102 | 4 | 102 | “User102 post 2” |
| 103 | user103@email.com | user103 | 5 | 103 | “User103 post 1” |
| 103 | user103@email.com | user103 | 6 | 103 | “User103 post 2” |
If the user table has many columns or posts, this may create a performance problem. We can address this issue by specifying the fetch mode explicitly.
4.2. Lists and Sets N+1
At the same time, while fetching multiple users, we encounter an infamous N+1 problem. This is true for List-based Users:
@Test
void givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
List<User> users = getService().findAll();
assertSelectCount(users.size() + 1);
}
Also, this is true for Set-based Users:
@Test
void givenEagerSetBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
List<User> users = getService().findAll();
assertSelectCount(users.size() + 1);
}
There will be only two kinds of queries. The first one fetches all the users:
SELECT u.id, u.email, u.username
FROM simple_user uAnd N number of subsequent requests to get the posts for each User:
SELECT p.id, p.author_id, p.content
FROM post p
WHERE p.author_id = ?Thus, we don’t have any differences between Lists and Sets for these types of relationships.
5. Groups, Users and Posts
Let’s consider more complex relationships and add groups to our model. They create unidirectional many-to-many relationships with users:
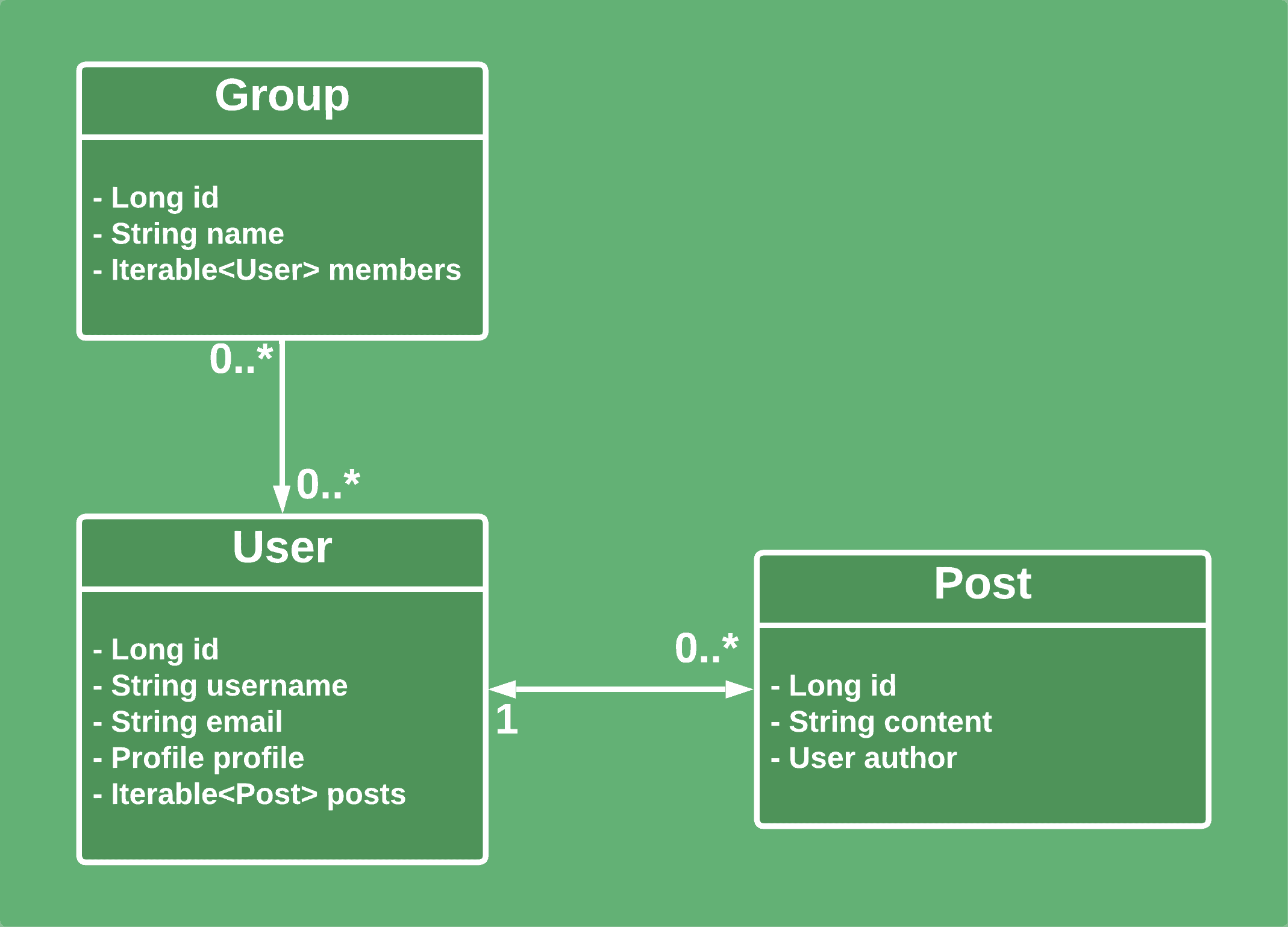
Because the relationships between Users and Posts remain the same, old tests will be valid and produce the same results. Let’s create similar tests for groups.
5.1. Lists and N + 1
We’ll have the following Group class with @ManyToMany relationships:
@Data
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany(fetch = FetchType.EAGER)
private List<User> members;
}
Let’s try to fetch all the groups:
@Test
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusMPlusOneRequests() {
List<Group> groups = groupService.findAll();
Set<User> users = groups.stream().map(Group::getMembers).flatMap(List::stream).collect(Collectors.toSet());
assertSelectCount(groups.size() + users.size() + 1);
}Hibernate will issue additional queries for each group to get the members and for each member to get their posts. Thus, we’ll have three types of queries:
SELECT g.id, g.name
FROM interest_group g
SELECT gm.interest_group_id, u.id, u.email, u.username
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
WHERE gm.interest_group_id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?Overall, we’ll get 1 + N + M number of requests. N is the number of groups, and M is the number of unique users in these groups. Let’s try to fetch a single group:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests(Long groupId) {
Optional<Group> group = groupService.findById(groupId);
assertThat(group).isPresent();
assertSelectCount(1 + group.get().getMembers().size());
}We’ll have a similar situation, but we’ll get all the User data in a single query using LEFT JOIN. Thus, there will be only two types of queries:
SELECT g.id, gm.interest_group_id, u.id, u.email, u.username, g.name
FROM interest_group g
LEFT JOIN (interest_group_members gm JOIN simple_user u ON u.id = gm.members_id)
ON g.id = gm.interest_group_id
WHERE g.id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?Overall, we’ll have N + 1 requests, where N is the number of group members.
5.2 Sets and Cartesian Product
While working with Sets, we’ll see a different picture. Let’s check our Set-based Group class:
@Data
@Entity
public class Group {
@Id
private Long id;
private String name;
@ManyToMany(fetch = FetchType.EAGER)
private Set<User> members;
}
Fetching all the groups will produce a slightly different result from the List-based groups:
@Test
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenIssueNPlusOneRequests() {
List<Group> groups = groupService.findAll();
assertSelectCount(groups.size() + 1);
}Instead of N + M + 1 from the previous example. We’ll have just N + 1 but get more complex queries. We’ll still have a separate query to get all the groups, but Hibernate fetches users and their posts in a single query using two JOINs:
SELECT g.id, g.name
FROM interest_group g
SELECT u.id,
u.username,
u.email,
p.id,
p.author_id,
p.content,
gm.interest_group_id,
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
LEFT JOIN post p ON u.id = p.author_id
WHERE gm.interest_group_id = ?Although we reduced the number of queries, the result set might contain duplicated data due to JOINs and, subsequently, a Cartesian product. We’ll get repeated group information for all the users in the group, and all of that will be repeated for each user post:
| u.id | u.username | u.email | p.id | p.author_id | p.content | gm.interest_group_id |
|---|---|---|---|---|---|---|
| 301 | user301 | user301@email.com | 201 | 301 | “User301’s post 1” | 101 |
| 302 | user302 | user302@email.com | 202 | 302 | “User302’s post 1” | 101 |
| 303 | user303 | user303@email.com | NULL | NULL | NULL | 101 |
| 304 | user304 | user304@email.com | 203 | 304 | “User304’s post 1” | 102 |
| 305 | user305 | user305@email.com | 204 | 305 | “User305’s post 1” | 102 |
| 306 | user306 | user306@email.com | NULL | NULL | NULL | 102 |
| 307 | user307 | user307@email.com | 205 | 307 | “User307’s post 1” | 103 |
| 308 | user308 | user308@email.com | 206 | 308 | “User308’s post 1” | 103 |
| 309 | user309 | user309@email.com | NULL | NULL | NULL | 103 |
After reviewing the previous queries, it’s obvious why fetching a single group would issue a single request:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerSetBasedGroup_whenFetchingAllGroups_thenCreateCartesianProductInOneQuery(Long groupId) {
groupService.findById(groupId);
assertSelectCount(1);
}We’ll use only the second query with JOINs, reducing the number of requests:
SELECT u.id,
u.username,
u.email,
p.id,
p.author_id,
p.content,
gm.interest_group_id,
FROM interest_group_members gm
JOIN simple_user u ON u.id = gm.members_id
LEFT JOIN post p ON u.id = p.author_id
WHERE gm.interest_group_id = ?5.3. Removals using Lists and Sets
Another interesting difference between Sets and Lists is how they remove objects. This only applies to the @ManyToMany relationships. Let’s consider a more straightforward case with Sets first:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenRemoveUser_thenIssueOnlyOneDelete(Long groupId) {
groupService.findById(groupId).ifPresent(group -> {
Set<User> members = group.getMembers();
if (!members.isEmpty()) {
reset();
Set<User> newMembers = members.stream().skip(1).collect(Collectors.toSet());
group.setMembers(newMembers);
groupService.save(group);
assertSelectCount(1);
assertDeleteCount(1);
}
});
}The behavior is quite reasonable, and we just remove the record from the join table. We’ll see in the logs only two queries:
SELECT g.id, g.name,
u.id, u.username, u.email,
p.id, p.author_id, p.content,
m.interest_group_id,
FROM interest_group g
LEFT JOIN (interest_group_members m JOIN simple_user u ON u.id = m.members_id)
ON g.id = m.interest_group_id
LEFT JOIN post p ON u.id = p.author_id
DELETE
FROM interest_group_members
WHERE interest_group_id = ? AND members_id = ?We have an additional selection only because the test methods aren’t transactional, and the original group isn’t stored in our persistence context.
Overall, Sets behave the way we would assume. Now, let’s check the Lists behavior:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedGroup_whenRemoveUser_thenIssueRecreateGroup(Long groupId) {
groupService.findById(groupId).ifPresent(group -> {
List<User> members = group.getMembers();
int originalNumberOfMembers = members.size();
assertSelectCount(ONE + originalNumberOfMembers);
if (!members.isEmpty()) {
reset();
members.remove(0);
groupService.save(group);
assertSelectCount(ONE + originalNumberOfMembers);
assertDeleteCount(ONE);
assertInsertCount(originalNumberOfMembers - ONE);
}
});
}
Here, we have several queries: SELECT, DELETE, and INSERT. The problem is that Hibernate removes the entire group from the join table and recreates it anew. Again, we have the initial select statements due to the lack of persistence context in the test methods:
SELECT u.id, u.email, u.username, g.name,
g.id, gm.interest_group_id,
FROM interest_group g
LEFT JOIN (interest_group_members gm JOIN simple_user u ON u.id = gm.members_id)
ON g.id = gm.interest_group_id
WHERE g.id = ?
SELECT p.author_id, p.id, p.content
FROM post p
WHERE p.author_id = ?
DELETE
FROM interest_group_members
WHERE interest_group_id = ?
INSERT
INTO interest_group_members (interest_group_id, members_id)
VALUES (?, ?)The code will produce one query to get all the group members. N requests to get the posts, where N is the number of members. One request to delete the entire group, and N – 1 requests to add members again. In general, we can think about it as 1 + 2N.
Lists don’t produce a Cartesian product not because of the performance consideration. As Lists allow repeated elements, Hibernate has problems distinguishing Cartesian duplicates and the duplicates in the collections.
This is why it’s recommended to use only Sets with @ManyToMany annotation. Otherwise, we should prepare for the dramatic performance impact.
6. Complete Domain
Now, let’s consider a more realistic domain with many different relationships:
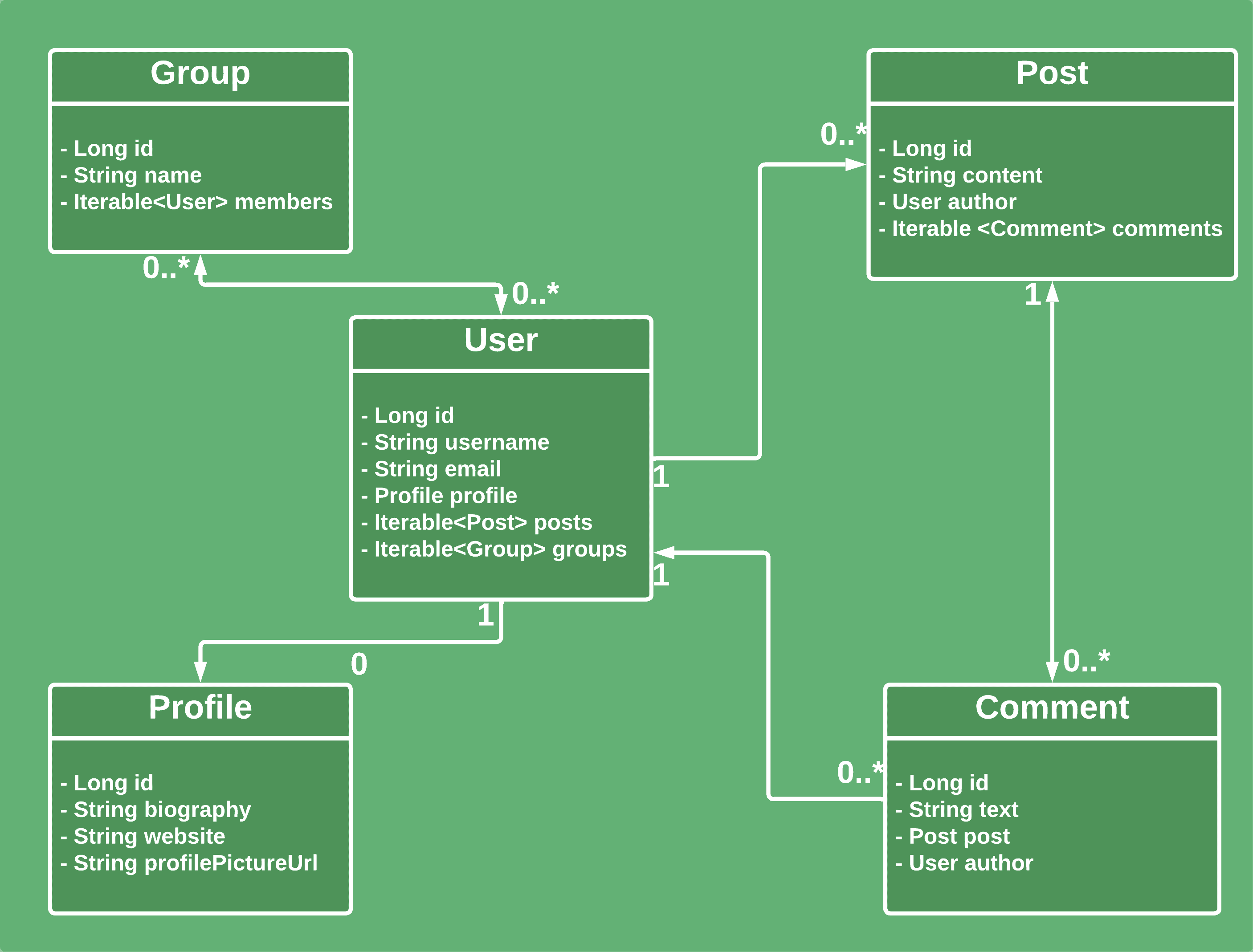
Now, we have quite an interconnected domain model. There are several one-to-many relationships, bidirectional many-to-many relationships, and transitive circular relationships.
6.1. Lists
First, let’s consider the relationships where we use List for all to-many relationships. Let’s try to fetch all the users from the database:
@ParameterizedTest
@MethodSource
void givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests(ToIntFunction<List<User>> function) {
int numberOfRequests = getService().countNumberOfRequestsWithFunction(function);
assertSelectCount(numberOfRequests);
}
static Stream<Arguments> givenEagerListBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequests() {
return Stream.of(
Arguments.of((ToIntFunction<List<User>>) s -> {
int result = 2 * s.size() + 1;
List<Post> posts = s.stream().map(User::getPosts)
.flatMap(List::stream)
.toList();
result += posts.size();
return result;
})
);
}This request would result in many different queries. First, we’ll get all the users’ IDs. Then, separate requests for all the groups and posts for each user. Finally, we’ll fetch the information about each post.
Overall, we’ll issue lots of queries, but at the same time, we won’t have any joins between several to-many relationships. This way, we avoid a Cartesian product and have a lower amount of data returned, as we don’t have duplicates, but we use more requests.
While fetching a single user, we’ll have an interesting situation:
@ParameterizedTest
@ValueSource(longs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10})
void givenEagerListBasedUser_WhenFetchingOneUser_ThenUseDFS(Long id) {
int numberOfRequests = getService()
.getUserByIdWithFunction(id, this::countNumberOfRequests);
assertSelectCount(numberOfRequests);
}
The countNumberOfRequests method is a util method that uses DFS to count the number of entities and calculate the number of requests:
Get all the posts for user #2
The user wrote the following posts: 1,2,3
Check all the commenters for post #1: 3,8,9,10
Get all the posts for user #10: 22
Check all the commenters for post #22: 3,6,7,10
Get all the posts for user #3: 4,5,6
Check all the commenters for post #4: 2,4,9
Get all the posts for user #9: 19,20,21
Check all the commenters for post #19: 3,4,8,9,10
Get all the posts for user #8: 16,17,18
Check all the commenters for post #16:
Check all the commenters for post #17: 2,4,9
Get all the posts for user #4: 7,8,9,10
Check all the commenters for post #7:
Check all the commenters for post #8:
Check all the commenters for post #9: 1,5,6
Get all the posts for user #1:
Get all the posts for user #5: 11,12,13,14
Check all the commenters for post #11: 2,3,8
Check all the commenters for post #12: 10
Check all the commenters for post #13: 4,9,10
Check all the commenters for post #14:
Get all the posts for user #6:
Check all the commenters for post #10: 2,5,6,8
Check all the commenters for post #18: 1,2,3,4,5
Check all the commenters for post #20:
Check all the commenters for post #21: 7
Get all the posts for user #7: 15
Check all the commenters for post #15: 1
Check all the commenters for post #5: 1,2,5,8
Check all the commenters for post #6:
Check all the commenters for post #2:
Check all the commenters for post #3: 1,3,6The result is a transitive closure. For a single user with ID #2, we have to do 42(!) requests to the database. Although the main issue is the eager fetch type, it shows the explosion in the request number if we’re using Lists.
Lazy fetch might produce a similar issue when we trigger the load for most of the internal fields. This might be intentional based on the domain logic. Also, it might be accidental, for example, incorrect overrides for toString(), equals(T), and hashCode() methods.
6.2. Sets
Let’s change all the Lists in our domain model to Sets and make similar tests:
@Test
void givenEagerSetBasedUser_WhenFetchingAllUsers_ThenIssueNPlusOneRequestsWithCartesianProduct() {
List<User> users = getService().findAll();
assertSelectCount(users.size() + 1);
}First, we’ll have fewer requests to get all the users, which should be better overall. However, if we look at the requests, we can see the following:
SELECT profile.id, profile.biography, profile.website, profile.profile_picture_url,
user.id, user.email, user.username,
user_group.members_id,
interest_group.id, interest_group.name,
post.id, post.author_id, post.content,
comment.id, comment.text, comment.post_id,
comment_author.id, comment_author.profile_id, comment_author.username, comment_author.email,
comment_author_group_member.members_id,
comment_author_group.id, comment_author_group.name
FROM profile profile
LEFT JOIN simple_user user
ON profile.id = user.profile_id
LEFT JOIN (interest_group_members user_group
JOIN interest_group interest_group
ON interest_group.id = user_group.groups_id)
ON user.id = user_group.members_id
LEFT JOIN post post ON user.id = post.author_id
LEFT JOIN comment comment ON post.id = comment.post_id
LEFT JOIN simple_user comment_author ON comment_author.id = comment.author_id
LEFT JOIN (interest_group_members comment_author_group_member
JOIN interest_group comment_author_group
ON comment_author_group.id = comment_author_group_member.groups_id)
ON comment_author.id = comment_author_group_member.members_id
WHERE profile.id = ?This query pulls an immense amount of data from the database, and we have one such query for each user. Another thing is that the result set will contain duplicates due to the Cartesian product. Getting a single user would give us a similar result, fewer requests but with massive result sets.
7. Pros and Cons
We used eager fetch in this tutorial to highlight the difference in the default behavior of Lists and Sets. While loading data eagerly might improve the performance and simplify the interaction with the database, it should be used cautiously.
Although eager fetch is usually considered to solve the N+1 problem, it’s not always the case. The behavior depends on multiple factors and the overall structure of the relationships between domain entities.
Sets are preferable to use with too many relationships for several reasons. First, in most cases, the collection that doesn’t allow duplicates reflects the domain model perfectly. We cannot have two identical users in a group, and a user cannot have two identical posts.
Another thing is that Sets are more flexible. While the default fetch mode for Sets is to create a join, we can define it explicitly by using fetch mode.
The delete behavior for many-to-many relationships using Lists produces an overhead. It’s hard to notice the difference on small datasets, but we can experience high latency with lots of data.
To avoid these problems, it’s a good idea to cover the crucial parts of our interaction with the database with tests. It would ensure that some seemingly insignificant change in one part of our domain model won’t introduce huge overhead in generated queries.
8. Conclusion
In most situations, we should use Sets for to-many relationships. This provides us with mode controllable relationships and avoids overheads on deletes.
However, all the changes and ideas about improving the domain model should be profiled and tested. The issues might not expose themselves to small datasets and simplistic entity relationships.
As usual, all the code from this tutorial is available over on GitHub.






