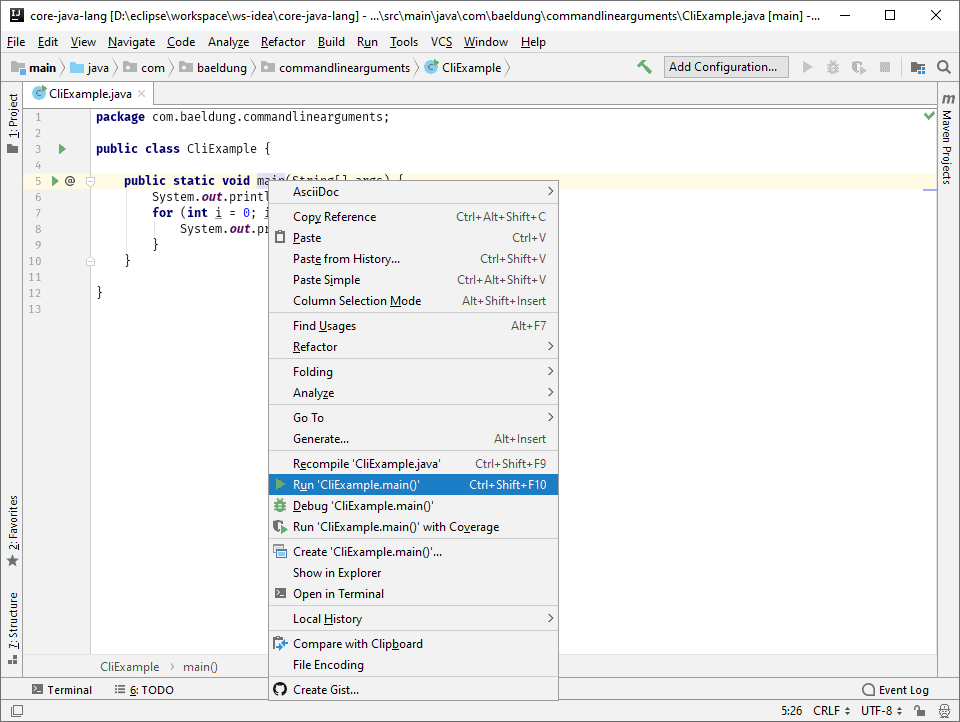
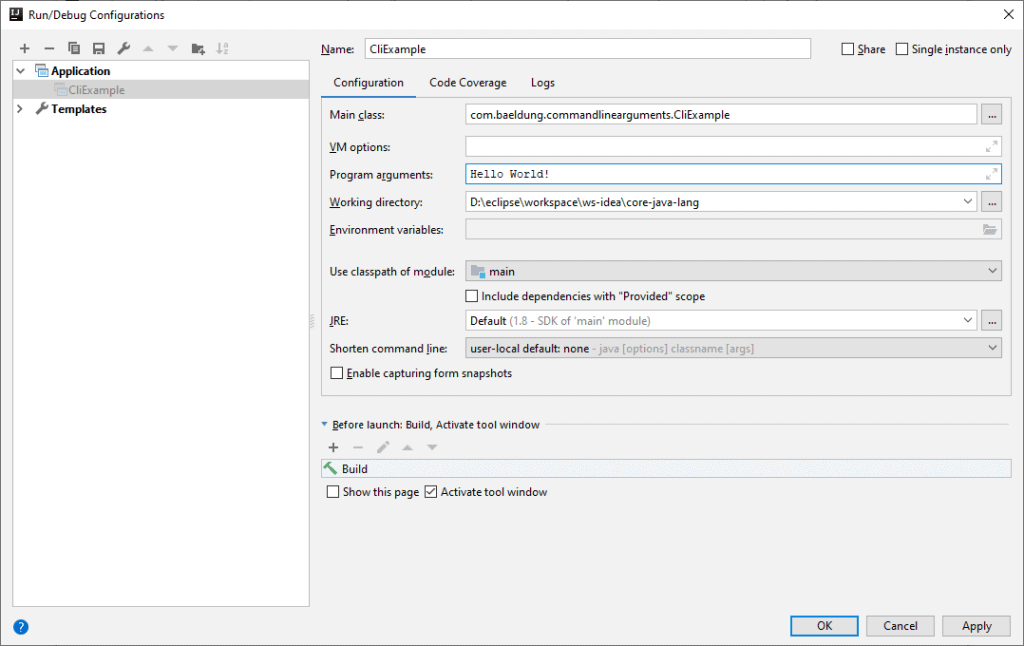
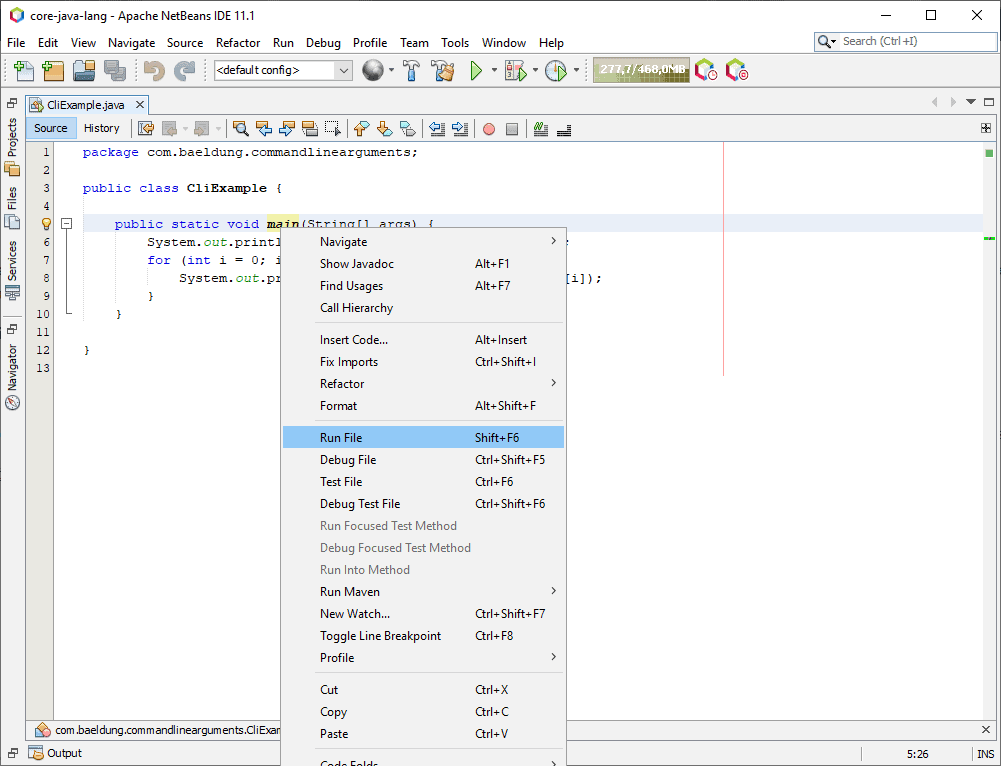
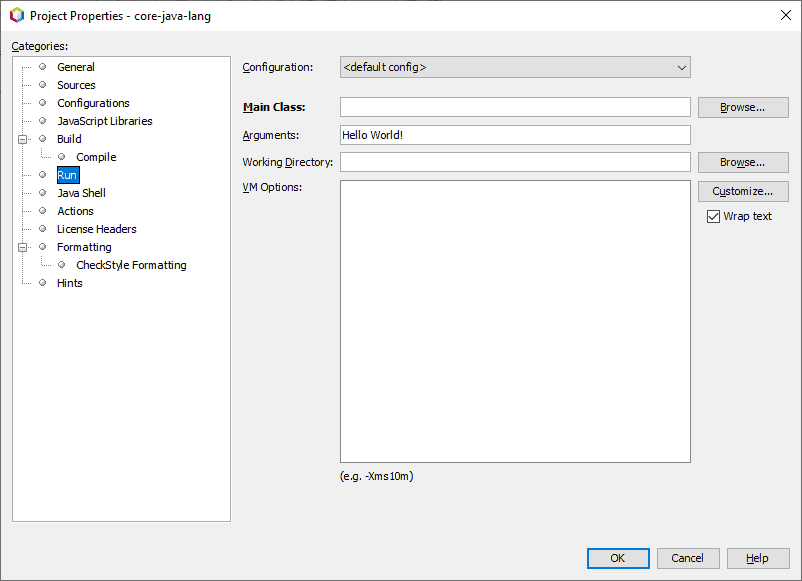
1. Overview
In this tutorial, we'll learn the basic concepts of blockchain technology. We'll also implement a basic application in Java that focuses on the concepts.
Further, we'll discuss some advanced concepts and practical applications of this technology.
2. What is Blockchain?
So, let's first understand what exactly blockchain is…
Well, it traces its origin back to the whitepaper published by Satoshi Nakamoto on Bitcoin, back in 2008.
Blockchain is a decentralized ledger of information. It consists of blocks of data connected through the use of cryptography. It belongs to a network of nodes connected over the public network. We'll understand this better when we attempt to build a basic tutorial later on.
There are some important attributes that we must understand, so let's go through them:
- Tamper-proof: First and foremost, data as part of a block is tamper-proof. Every block is referenced by a cryptographic digest, commonly known as a hash, making the block tamper-proof.
- Decentralized: The entire blockchain is completely decentralized across the network. This means that there is no master node, and every node in the network has the same copy.
- Transparent: Every node participating in the network validates and adds a new block to its chain through consensus with other nodes. Hence, every node has complete visibility of the data.
3. How Does Blockchain Work?
Now, let's understand how blockchain works.
The fundamental units of a blockchain are blocks. A single block can encapsulate several transactions or other valuable data:
![]()
3.1. Mining a Block
We represent a block by a hash value. Generating the hash value of a block is called “mining” the block. Mining a block is typically computationally expensive to do as it serves as the “proof of work”.
The hash of a block typically consists of the following data:
- Primarily, the hash of a block consists of the transactions it encapsulates
- The hash also consists of the timestamp of the block's creation
- It also includes a nonce, an arbitrary number used in cryptography
- Finally, the hash of the current block also includes the hash of the previous block
Multiple nodes in the network can compete to mine the block at the same time. Apart from generating the hash, nodes also have to verify that the transactions being added in the block are legitimate. The first to mine a block wins the race!
3.2. Adding a Block into Blockchain
While mining a block is computationally expensive, verifying that a block is legitimate is relatively much easier. All nodes in the network participate in verifying a newly mined block.
![]()
Thus, a newly mined block is added into the blockchain on the consensus of the nodes.
Now, there are several consensus protocols available which we can use for verification. The nodes in the network use the same protocol to detect malicious branch of the chain. Hence, a malicious branch even if introduced will soon be rejected by the majority of the nodes.
4. Basic Blockchain in Java
Now we've got enough context to start building a basic application in Java.
Our simple example here will illustrate the basic concepts we just saw. A production-grade application entails a lot of considerations which are beyond the scope of this tutorial. We'll, however, touch upon some advanced topics later on.
4.1. Implementing a Block
Firstly, we need to define a simple POJO that will hold the data for our block:
public class Block {
private String hash;
private String previousHash;
private String data;
private long timeStamp;
private int nonce;
public Block(String data, String previousHash, long timeStamp) {
this.data = data;
this.previousHash = previousHash;
this.timeStamp = timeStamp;
this.hash = calculateBlockHash();
}
// standard getters and setters
}
Let's understand what we've packed here:
- Hash of the previous block, an important part to build the chain
- The actual data, any information having value, like a contract
- The timestamp of the creation of this block
- A nonce, which is an arbitrary number used in cryptography
- Finally, the hash of this block, calculated based on other data
4.2. Calculating the Hash
Now, how do we calculate the hash of a block? We've used a method calculateBlockHash but have not seen an implementation yet. Before we implement this method, it's worth spending some time to understand what exactly is a hash.
A hash is an output of something known as a hash function. A hash function maps input data of arbitrary size to output data of fixed size. The hash is quite sensitive to any change in the input data, however small that may be.
Moreover, it's impossible to get the input data back just from its hash. These properties make the hash function quite useful in cryptography.
So, let's see how we can generate the hash of our block in Java:
public String calculateBlockHash() {
String dataToHash = previousHash
+ Long.toString(timeStamp)
+ Integer.toString(nonce)
+ data;
MessageDigest digest = null;
byte[] bytes = null;
try {
digest = MessageDigest.getInstance("SHA-256");
bytes = digest.digest(dataToHash.getBytes(UTF_8));
} catch (NoSuchAlgorithmException | UnsupportedEncodingException ex) {
logger.log(Level.SEVERE, ex.getMessage());
}
StringBuffer buffer = new StringBuffer();
for (byte b : bytes) {
buffer.append(String.format("%02x", b));
}
return buffer.toString();
}
Quite a lot of things happening here, let's understand them in detail:
- First, we concatenate different parts of the block to generate a hash from
- Then, we get an instance of the SHA-256 hash function from MessageDigest
- Then, we generate the hash value of our input data, which is a byte array
- Finally, we transform the byte array into a hex string, a hash is typically represented as a 32-digit hex number
4.3. Have We Mined the Block Yet?
Everything sounds simple and elegant so far, except for the fact that we've not mined the block yet. So what exactly entails mining a block, which has captured the fancy of developers for some time now!
Well, mining a block means solving a computationally complex task for the block. While calculating the hash of a block is somewhat trivial, finding the hash starting with five zeroes is not. Even more complicated would be to find a hash starting with ten zeroes, and we get a general idea.
So, how exactly can we do this? Honestly, the solution is much less fancy! It's with brute force that we attempt to achieve this goal. We make use of nonce here:
public String mineBlock(int prefix) {
String prefixString = new String(new char[prefix]).replace('\0', '0');
while (!hash.substring(0, prefix).equals(prefixString)) {
nonce++;
hash = calculateBlockHash();
}
return hash;
}
Let's see what we trying to do here are:
- We start by defining the prefix we desire to find
- Then we check whether we've found the solution
- If not we increment the nonce and calculate the hash in a loop
- The loop goes on until we hit the jackpot
We're starting with the default value of nonce here and incrementing it by one. But there are more sophisticated strategies to start and increment a nonce in real-world applications. Also, we're not verifying our data here, which is typically an important part.
4.4. Let's Run the Example
Now that we've our block defined along with its functions, we can use this to create a simple blockchain. We'll store this in an ArrayList:
List<Block> blockchain = new ArrayList<>();
int prefix = 4;
String prefixString = new String(new char[prefix]).replace('\0', '0');
Additionally, we've defined a prefix of four, which effectively means that we want our hash to start with four zeroes.
Let's see how can we add a block here:
@Test
public void givenBlockchain_whenNewBlockAdded_thenSuccess() {
Block newBlock = new Block(
"The is a New Block.",
blockchain.get(blockchain.size() - 1).getHash(),
new Date().getTime());
newBlock.mineBlock(prefix);
assertTrue(newBlock.getHash().substring(0, prefix).equals(prefixString));
blockchain.add(newBlock);
}
4.5. Blockchain Verification
How can a node validate that a blockchain is valid? While this can be quite complicated, let's think about a simple version:
@Test
public void givenBlockchain_whenValidated_thenSuccess() {
boolean flag = true;
for (int i = 0; i < blockchain.size(); i++) {
String previousHash = i==0 ? "0" : blockchain.get(i - 1).getHash();
flag = blockchain.get(i).getHash().equals(blockchain.get(i).calculateBlockHash())
&& previousHash.equals(blockchain.get(i).getPreviousHash())
&& blockchain.get(i).getHash().substring(0, prefix).equals(prefixString);
if (!flag) break;
}
assertTrue(flag);
}
So, here we're making three specific checks for every block:
- The stored hash of the current block is actually what it calculates
- The hash of the previous block stored in the current block is the hash of the previous block
- The current block has been mined
5. Some Advanced Concepts
While our basic example brings out the basic concepts of a blockchain, it's certainly not complete. To put this technology into practical use, several other considerations need to be factored in.
While it's not possible to detail all of them, let's go through some of the important ones:
5.1. Transaction Verification
Calculating the hash of a block and finding the desired hash is just one part of mining. A block consists of data, often in the form of multiple transactions. These must be verified before they can be made part of a block and mined.
A typical implementation of blockchain sets a restriction on how much data can be part of a block. It also sets up rules on how a transaction can be verified. Multiple nodes in the network participate in the verification process.
5.2. Alternate Consensus Protocol
We saw that consensus algorithm like “Proof of Work” is used to mine and validate a block. However, this is not the only consensus algorithm available for use.
There are several other consensus algorithms to choose from, like Proof of Stake, Proof of Authority, and Proof of Weight. All of these have their pros and cons. Which one to use depends upon the type of application we intend to design.
5.3. Mining Reward
A blockchain network typically consists of voluntary nodes. Now, why would anyone want to contribute to this complex process and keep it legit and growing?
This is because nodes are rewarded for verifying the transactions and mining a block. These rewards are typically in the form of coin associated with the application. But an application can decide the reward to be anything of value.
5.4. Node Types
A blockchain completely relies on its network to operate. In theory, the network is completely decentralized, and every node is equal. However, in practice, a network consists of multiple types of nodes.
While a full node has a complete list of transactions, a light node only has a partial list. Moreover, not all nodes participate in verification and validation.
5.5. Secure Communication
One of the hallmarks of blockchain technology is its openness and anonymity. But how does it provide security to transactions being carried within? This is based on cryptography and public key infrastructure.
The initiator of a transaction uses their private key to secure it and attach it to the public key of the recipient. Nodes can use the public keys of the participants to verify transactions.
6. Practical Applications of Blockchain
So, blockchain seems to be an exciting technology, but it also must prove useful. This technology has been around for some time now and – needless to say – it has proved to be disruptive in many domains.
Its application in many other areas is being actively pursued. Let's understand the most popular applications:
- Currency: This is by far the oldest and most widely known use of blockchain, thanks to the success of Bitcoin. They provide secure and frictionless money to people across the globe without any central authority or government intervention.
- Identity: Digital identity is fast becoming the norm in the present world. However, this is mired by security issues and tampering. Blockchain is inevitable in revolutionizing this area with completely secure and tamper-proof identities.
- Healthcare: Healthcare industry is loaded with data, mostly handled by central authorities. This decreases transparency, security, and efficiency in handling such data. Blockchain technology can provide a system without any third party to provide much-needed trust.
- Government: This is perhaps an area which is well open to disruption by the blockchain technology. Government is typically at the center of several citizen services which are often laden with inefficiencies and corruption. Blockchain can help establish much better government-citizen relations.
While our basic implementation here is useful to elicit the concepts, it's not practical to develop a product on blockchain from scratch. Thankfully, this space has matured now, and we do have some quite useful tools to start from.
Let's go through some of the popular tools to work within this space:
- Solidity: Solidity is a statically-typed and object-oriented programming language designed for writing smart contracts. It can be used to write smart contracts on various blockchain platforms like Ethereum.
- Remix IDE: Remix is a powerful open-source tool to write smart contracts in Solidity. This enables the user to write smart contracts right from the browser.
- Truffle Suite: Truffle provides a bunch of tools to get a developer up and started in developing distributed apps. This includes Truffle, Ganache, and Drizzle.
- Ethlint/Solium: Solium allows developers to ensure that their smart contracts written on Solidity is free from style and security issues. Solium also helps in fixing these issues.
- Parity: Parity helps in setting up the development environment for smart contract on Etherium. It provides a fast and secure way to interact with the blockchain.
8. Conclusion
To sum up, in this tutorial, we went through the basic concepts of blockchain technology. We understood how a network mine and add a new block in the blockchain. Further, we implemented the basic concepts in Java. We also discussed some of the advanced concepts related to this technology.
Finally, we wrapped up with some practical applications of blockchain and as well as available tools.
As always, the code can be found over on GitHub.
![]()