1. Introduction
Atomikos is a transaction library for Java applications. In this tutorial, we'll understand why and how to use Atomikos.
In the process, we'll also go through the basics of transactions and why we need them.
Then, we'll create a simple application with transactions leveraging different APIs from Atomikos.
2. Understanding the Basics
Before we discuss Atomikos, let's understand what exactly transactions are and a few concepts related to them. Put simply, a transaction is a logical unit of work whose effect is visible outside the transaction either in entirety or not at all.
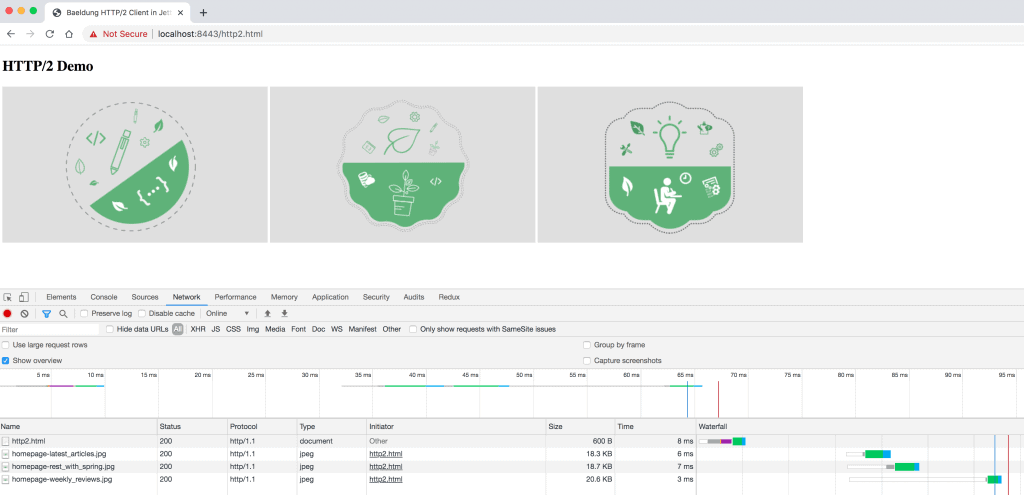
Let's take an example to understand this better. A typical retail application reserves the inventory and then places an order:
![]()
Here, we'd like these two operations to either happen together or not happen at all. We can achieve this by wrapping these operations into a single transaction.
2.1. Local vs. Distributed Transaction
A transaction can involve multiple independent operations. These operations can execute on the same resource or different resources. We refer to the participating components in a transaction like a database as a resource here.
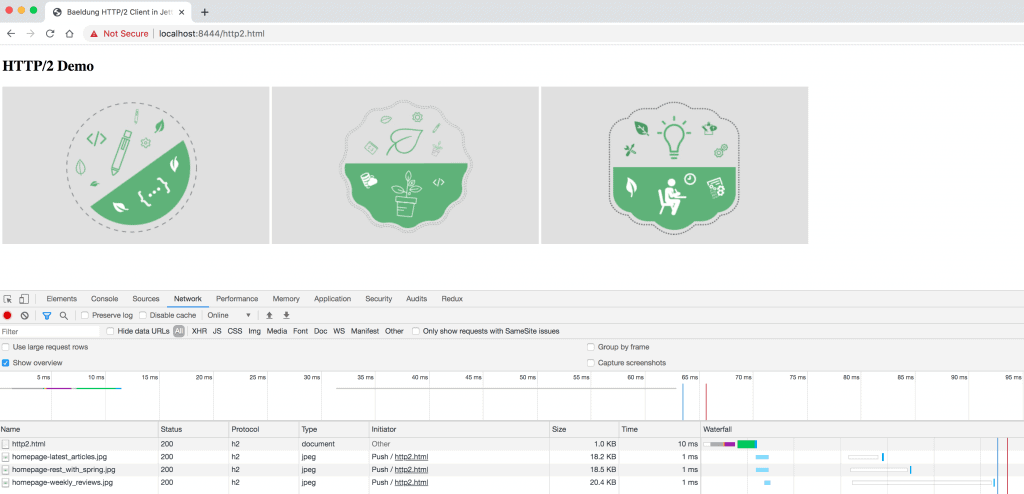
Transactions within a single resource are known local transaction while those spawning across multiple resources are known as the distributed transaction:
![]()
Here, inventory and orders can be two tables in the same database, or they can be two different databases — possibly running on different machines altogether.
2.2. XA Specification and Java Transaction API
XA refers to eXtended Architecture, which is a specification for distributed transaction processing. The goal of XA is to provide atomicity in global transactions involving heterogeneous components.
XA specification provides integrity through a protocol known as a two-phase commit. Two-phase commit is a widely-used distributed algorithm to facilitate the decision to commit or rollback a distributed transaction.
Java Transaction API (JTA) is a Java Enterprise Edition API developed under the Java Community Process. It enables Java applications and application servers to perform distributed transactions across XA resources.
JTA is modeled around XA architecture, leveraging two-phase commit. JTA specifies standard Java interfaces between a transaction manager and the other parties in a distributed transaction.
3. Introduction to Atomikos
Now that we've gone through the basics of transactions, we're ready to learn Atomikos. In this section, we'll understand what exactly Atomikos is and how it relates to concepts like XA and JTA. We'll also understand the architecture of Atomikos and go through its product offerings.
3.1. What Is Atomikos
As we have seen, JTA provides interfaces in Java for building applications with distributed transactions. Now, JTA is just a specification and does not offer any implementation. For us to run an application where we leverage JTA, we need an implementation of JTA. Such an implementation is called a transaction manager.
Typically, the application server provides a default implementation of the transaction manager. For instance, in the case of Enterprise Java Beans (EJB), EJB containers manage transaction behavior without any explicit intervention by application developers. However, in many cases, this may not be ideal, and we may need direct control over the transaction independent of the application server.
Atomikos is a lightweight transaction manager for Java that enables applications using distributed transactions to be self-contained. Essentially, our application doesn't need to rely on a heavyweight component like an application server for transactions. This brings the concept of distributed transactions closer to a cloud-native architecture.
3.2. Atomikos Architecture
Atomikos is built primarily as a JTA transaction manager and, hence, implements XA architecture with a two-phase commit protocol. Let's see a high-level architecture with Atomikos:
![]()
Here, Atomikos is facilitating a two-phase-commit-based transaction spanning across a database and a message queue.
3.3. Atomikos Product Offerings
Atomikos is a distributed transaction manager that offers more features than what JTA/XA mandates. It has an open-source product and a much more comprehensive commercial offering:
- TransactionsEssentials: Atomikos' open-source product providing JTA/XA transaction manager for Java applications working with databases and message queues. This is mostly useful for testing and evaluation purposes.
- ExtremeTransactions: the commercial offering of Atomikos, which offers distributed transactions across composite applications, including REST services apart from databases and message queues. This is useful to build applications performing Extreme Transaction Processing (XTP).
In this tutorial, we'll use the TransactionsEssentials library to build and demonstrate the capabilities of Atomikos.
4. Setting up Atomikos
As we've seen earlier, one of the highlights of Atomikos is that it's an embedded transaction service. What this means is that we can run it in the same JVM as our application. Thus, setting up Atomikos is quite straightforward.
4.1. Dependencies
First, we need to set up the dependencies. Here, all we have to do is declare the dependencies in our Maven pom.xml file:
<dependency>
<groupId>com.atomikos</groupId>
<artifactId>transactions-jdbc</artifactId>
<version>5.0.6</version>
</dependency>
<dependency>
<groupId>com.atomikos</groupId>
<artifactId>transactions-jms</artifactId>
<version>5.0.6</version>
</dependency>
We're using Atomikos dependencies for JDBC and JMS in this case, but similar dependencies are available on Maven Central for other XA-complaint resources.
4.2. Configurations
Atomikos provides several configuration parameters, with sensible defaults for each of them. The easiest way to override these parameters is to provide a transactions.properties file in the classpath. We can add several parameters for the initialization and operation of the transaction service. Let's see a simple configuration to override the directory where log files are created:
com.atomikos.icatch.file=path_to_your_file
Similarly, there are other parameters that we can use to control the timeout for transactions, set unique names for our application, or define shutdown behavior.
4.3. Databases
In our tutorial, we'll build a simple retail application, like the one we described earlier, which reserves inventory and then places an order. We'll use a relational database for simplicity. Moreover, we'll use multiple databases to demonstrate distributed transactions. However, this can very well extend to other XA-complaint resources like message queues and topics.
Our inventory database will have a simple table to host product inventories:
CREATE TABLE INVENTORY (
productId VARCHAR PRIMARY KEY,
balance INT
);
And, our order database will have a simple table to host placed orders:
CREATE TABLE ORDERS (
orderId VARCHAR PRIMARY KEY,
productId VARCHAR,
amount INT NOT NULL CHECK (amount <= 5)
);
This is a very basic database schema and useful only for the demonstration. However, it's important to note that our schema constraint does not allow order with a product quantity of more than five.
5. Working With Atomikos
Now, we're ready to use one of the Atomikos libraries to build our application with distributed transactions. In the following subsections, we'll use the built-in Atomikos resource adapters to connect with our back-end database systems. This is the quickest and easiest way to get started with Atomikos.
5.1. Instantiating UserTransaction
We will leverage JTA UserTransaction to demarcate transaction boundaries. All other steps related to transaction service will be automatically taken care of. This includes enlisting and delisting resources with the transaction service.
Firstly, we need to instantiate a UserTransaction from Atomikos:
UserTransactionImp utx = new UserTransactionImp();
5.2. Instantiating DataSource
Then, we need to instantiate a DataSource from Atomikos. There are two versions of DataSource that Atomikos makes available.
The first, AtomikosDataSourceBean, is aware of an underlying XADataSource:
AtomikosDataSourceBean dataSource = new AtomikosDataSourceBean();
While AtomikosNonXADataSourceBean uses any regular JDBC driver class:
AtomikosNonXADataSourceBean dataSource = new AtomikosNonXADataSourceBean();
As the name suggests, AtomikosNonXADataSource is not XA compliant. Hence transactions executed with such a data source can not be guaranteed to be atomic. So why would we ever use this? We may have some database that does not support XA specification. Atomikos does not prohibit us from using such a data source and still try to provide atomicity if there is a single such data source in the transaction. This technique is similar to Last Resource Gambit, a variation of the two-phase commit process.
Further, we need to appropriately configure the DataSource depending upon the database and driver.
5.3. Performing Database Operations
Once configured, it's fairly easy to use DataSource within the context of a transaction in our application:
public void placeOrder(String productId, int amount) throws Exception {
String orderId = UUID.randomUUID().toString();
boolean rollback = false;
try {
utx.begin();
Connection inventoryConnection = inventoryDataSource.getConnection();
Connection orderConnection = orderDataSource.getConnection();
Statement s1 = inventoryConnection.createStatement();
String q1 = "update Inventory set balance = balance - " + amount + " where productId ='" +
productId + "'";
s1.executeUpdate(q1);
s1.close();
Statement s2 = orderConnection.createStatement();
String q2 = "insert into Orders values ( '" + orderId + "', '" + productId + "', " + amount + " )";
s2.executeUpdate(q2);
s2.close();
inventoryConnection.close();
orderConnection.close();
} catch (Exception e) {
rollback = true;
} finally {
if (!rollback)
utx.commit();
else
utx.rollback();
}
}
Here, we are updating the database tables for inventory and order within the transaction boundary. This automatically provides the benefit of these operations happening atomically.
5.4. Testing Transactional Behavior
Finally, we must be able to test our application with simple unit tests to validate that the transaction behavior is as expected:
@Test
public void testPlaceOrderSuccess() throws Exception {
int amount = 1;
long initialBalance = getBalance(inventoryDataSource, productId);
Application application = new Application(inventoryDataSource, orderDataSource);
application.placeOrder(productId, amount);
long finalBalance = getBalance(inventoryDataSource, productId);
assertEquals(initialBalance - amount, finalBalance);
}
@Test
public void testPlaceOrderFailure() throws Exception {
int amount = 10;
long initialBalance = getBalance(inventoryDataSource, productId);
Application application = new Application(inventoryDataSource, orderDataSource);
application.placeOrder(productId, amount);
long finalBalance = getBalance(inventoryDataSource, productId);
assertEquals(initialBalance, finalBalance);
}
Here, we're expecting a valid order to decrease the inventory, while we're expecting an invalid order to leave the inventory unchanged. Please note that, as per our database constraint, any order with a quantity of more than five of a product is considered an invalid order.
5.5. Advanced Atomikos Usage
The example above is the simplest way to use Atomikos and perhaps sufficient for most of the requirements. However, there are other ways in which we can use Atomikos to build our application. While some of these options make Atomikos easy to use, others offer more flexibility. The choice depends on our requirements.
Of course, it's not necessary to always use Atomikos adapters for JDBC/JMS. We can choose to use the Atomikos transaction manager while working directly with XAResource. However, in that case, we have to explicitly take care of enlisting and delisting XAResource instances with the transaction service.
Atomikos also makes it possible to use more advanced features through a proprietary interface, UserTransactionService. Using this interface, we can explicitly register resources for recovery. This gives us fine-grained control over what resources should be recovered, how they should be recovered, and when recovery should happen.
6. Integrating Atomikos
While Atomikos provides excellent support for distributed transactions, it's not always convenient to work with such low-level APIs. To focus on the business domain and avoid the clutter of boilerplate code, we often need the support of different frameworks and libraries. Atomikos supports most of the popular Java frameworks related to back-end integrations. We'll explore a couple of them here.
6.1. Atomikos With Spring and DataSource
Spring is one of the popular frameworks in Java that provides an Inversion of Control (IoC) container. Notably, it has fantastic support for transactions as well. It offers declarative transaction management using Aspect-Oriented Programming (AOP) techniques.
Spring supports several transaction APIs, including JTA for distributed transactions. We can use Atomikos as our JTA transaction manager within Spring without much effort. Most importantly, our application remains pretty much agnostic to Atomikos, thanks to Spring.
Let's see how we can solve our previous problem, this time leveraging Spring. We'll begin by rewriting the Application class:
public class Application {
private DataSource inventoryDataSource;
private DataSource orderDataSource;
public Application(DataSource inventoryDataSource, DataSource orderDataSource) {
this.inventoryDataSource = inventoryDataSource;
this.orderDataSource = orderDataSource;
}
@Transactional(rollbackFor = Exception.class)
public void placeOrder(String productId, int amount) throws Exception {
String orderId = UUID.randomUUID().toString();
Connection inventoryConnection = inventoryDataSource.getConnection();
Connection orderConnection = orderDataSource.getConnection();
Statement s1 = inventoryConnection.createStatement();
String q1 = "update Inventory set balance = balance - " + amount + " where productId ='" +
productId + "'";
s1.executeUpdate(q1);
s1.close();
Statement s2 = orderConnection.createStatement();
String q2 = "insert into Orders values ( '" + orderId + "', '" + productId + "', " + amount + " )";
s2.executeUpdate(q2);
s2.close();
inventoryConnection.close();
orderConnection.close();
}
}
As we can see here, most of the transaction-related boilerplate code has been replaced by a single annotation at the method level. Moreover, Spring takes care of instantiating and injecting DataSource, which our application depends on.
Of course, we have to provide relevant configurations to Spring. We can use a simple Java class to configure these elements:
@Configuration
@EnableTransactionManagement
public class Config {
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosDataSourceBean inventoryDataSource() {
AtomikosDataSourceBean dataSource = new AtomikosDataSourceBean();
// Configure database holding order data
return dataSource;
}
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosDataSourceBean orderDataSource() {
AtomikosDataSourceBean dataSource = new AtomikosDataSourceBean();
// Configure database holding order data
return dataSource;
}
@Bean(initMethod = "init", destroyMethod = "close")
public UserTransactionManager userTransactionManager() throws SystemException {
UserTransactionManager userTransactionManager = new UserTransactionManager();
userTransactionManager.setTransactionTimeout(300);
userTransactionManager.setForceShutdown(true);
return userTransactionManager;
}
@Bean
public JtaTransactionManager jtaTransactionManager() throws SystemException {
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setTransactionManager(userTransactionManager());
jtaTransactionManager.setUserTransaction(userTransactionManager());
return jtaTransactionManager;
}
@Bean
public Application application() {
return new Application(inventoryDataSource(), orderDataSource());
}
}
Here, we are configuring AtomikosDataSourceBean for the two different databases holding our inventory and order data. Moreover, we're also providing the necessary configuration for the JTA transaction manager.
Now, we can test our application for transactional behavior as before. Again, we should be validating that a valid order reduces our inventory balance, while an invalid order leaves it unchanged.
6.2. Atomikos With Spring, JPA, and Hibernate
While Spring has helped us cut down boilerplate code to a certain extent, it's still quite verbose. Some tools can make working with relational databases in Java even easier. Java Persistence API (JPA) is a specification that describes the management of relational data in Java applications. This simplifies the data access and manipulation code to a large extent.
Hibernate is one of the most popular implementations of the JPA specification. Atomikos has great support for several JPA implementations, including Hibernate. As before, our application remains agnostic to Atomikos as well as Hibernate, thanks to Spring and JPA!
Let's see how Spring, JPA, and Hibernate can make our application even more concise while providing the benefits of distributed transactions through Atomikos. As before, we will begin by rewriting the Application class:
public class Application {
@Autowired
private InventoryRepository inventoryRepository;
@Autowired
private OrderRepository orderRepository;
@Transactional(rollbackFor = Exception.class)
public void placeOrder(String productId, int amount) throws SQLException {
String orderId = UUID.randomUUID().toString();
Inventory inventory = inventoryRepository.findOne(productId);
inventory.setBalance(inventory.getBalance() - amount);
inventoryRepository.save(inventory);
Order order = new Order();
order.setOrderId(orderId);
order.setProductId(productId);
order.setAmount(new Long(amount));
orderRepository.save(order);
}
}
As we can see, we're not dealing with any low-level database APIs now. However, for this magic to work, we do need to configure Spring Data JPA classes and configurations. We'll begin by defining our domain entities:
@Entity
@Table(name = "INVENTORY")
public class Inventory {
@Id
private String productId;
private Long balance;
// Getters and Setters
}
@Entity
@Table(name = "ORDERS")
public class Order {
@Id
private String orderId;
private String productId;
@Max(5)
private Long amount;
// Getters and Setters
}
Next, we need to provide the repositories for these entities:
@Repository
public interface InventoryRepository extends JpaRepository<Inventory, String> {
}
@Repository
public interface OrderRepository extends JpaRepository<Order, String> {
}
These are quite simple interfaces, and Spring Data takes care of elaborating these with actual code to work with database entities.
Finally, we need to provide the relevant configurations for a data source for both inventory and order databases and the transaction manager:
@Configuration
@EnableJpaRepositories(basePackages = "com.baeldung.atomikos.spring.jpa.inventory",
entityManagerFactoryRef = "inventoryEntityManager", transactionManagerRef = "transactionManager")
public class InventoryConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosDataSourceBean inventoryDataSource() {
AtomikosDataSourceBean dataSource = new AtomikosDataSourceBean();
// Configure the data source
return dataSource;
}
@Bean
public EntityManagerFactory inventoryEntityManager() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
// Configure the entity manager factory
return factory.getObject();
}
}
@Configuration
@EnableJpaRepositories(basePackages = "com.baeldung.atomikos.spring.jpa.order",
entityManagerFactoryRef = "orderEntityManager", transactionManagerRef = "transactionManager")
public class OrderConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosDataSourceBean orderDataSource() {
AtomikosDataSourceBean dataSource = new AtomikosDataSourceBean();
// Configure the data source
return dataSource;
}
@Bean
public EntityManagerFactory orderEntityManager() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
// Configure the entity manager factory
return factory.getObject();
}
}
@Configuration
@EnableTransactionManagement
public class Config {
@Bean(initMethod = "init", destroyMethod = "close")
public UserTransactionManager userTransactionManager() throws SystemException {
UserTransactionManager userTransactionManager = new UserTransactionManager();
userTransactionManager.setTransactionTimeout(300);
userTransactionManager.setForceShutdown(true);
return userTransactionManager;
}
@Bean
public JtaTransactionManager transactionManager() throws SystemException {
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setTransactionManager(userTransactionManager());
jtaTransactionManager.setUserTransaction(userTransactionManager());
return jtaTransactionManager;
}
@Bean
public Application application() {
return new Application();
}
}
This is still quite a lot of configuration that we have to do. This is partly because we're configuring Spring JPA for two separate databases. Also, we can further reduce these configurations through Spring Boot, but that's beyond the scope of this tutorial.
As before, we can test our application for the same transactional behavior. There's nothing new this time, except for the fact that we're using Spring Data JPA with Hibernate now.
7. Atomikos Beyond JTA
While JTA provides excellent transaction support for distributed systems, these systems must be XA-complaint like most relational databases or message queues. However, JTA is not useful if one of these systems doesn't support XA specification for a two-phase commit protocol. Several resources fall under this category, especially within a microservices architecture.
Several alternative protocols support distributed transactions. One of these is a variation of two-phase commit protocol that makes use of compensations. Such transactions have a relaxed isolation guarantee and are known as compensation-based transactions. Participants commit the individual parts of the transaction in the first phase itself, offering a compensation handler for a possible rollback in the second phase.
There are several design patterns and algorithms to implement a compensation-based transaction. For example, Sagas is one such popular design pattern. However, they are usually complex to implement and error-prone.
Atomikos offers a variation of compensation-based transaction called Try-Confirm/Cancel (TCC). TCC offers better business semantics to the entities under a transaction. However, this is possible only with advanced architecture support from the participants, and TCC is only available under the Atomikos commercial offering, ExtremeTransactions.
8. Alternatives to Atomikos
We have gone through enough of Atomikos to appreciate what it has to offer. Moreover, there's a commercial offering from Atomikos with even more powerful features. However, Atomikos is not the only option when it comes to choosing a JTA transaction manager. There are a few other credible options to choose from. Let's see how they fare against Atomikos.
8.1. Narayana
Narayana is perhaps one of the oldest open-source distributed transaction managers and is currently managed by Red Hat. It has been widely used across the industry, and it has evolved through community support and influenced several specifications and standards.
Narayana provides support for a wide range of transaction protocols like JTA, JTS, Web-Services, and REST, to name a few. Further, Narayana can be embedded in a wide range of containers.
Compared to Atomikos, Narayana provides pretty much all the features of a distributed transaction manager. In many cases, Narayana is more flexible to integrate and use in applications. For instance, Narayana has language bindings for both C/C++ and Java. However, this comes at the cost of added complexity, and Atomikos is comparatively easier to configure and use.
8.2. Bitronix
Bitronix is a fully working XA transaction manager that provides all services required by the JTA API. Importantly, Bitronix is an embeddable transaction library that provides extensive and useful error reporting and logging. For a distributed transaction, this makes it easier to investigate failures. Moreover, it has excellent support for Spring's transactional capabilities and works with minimal configurations.
Compared to Atomikos, Bitronix is an open-source project and does not have a commercial offering with product support. The key features that are part of Atomikos' commercial offering but are lacking in Bitronix include support for microservices and declarative elastic scaling capability.
9. Conclusion
To sum up, in this tutorial, we went through the basic details of transactions. We understood what distributed transactions are and how a library like Atomikos can facilitate in performing them. In the process, we leveraged the Atomikos APIs to create a simple application with distributed transactions.
We also understood how Atomikos works with other popular Java frameworks and libraries. Finally, we went through some of the alternatives to Atomikos that are available to us.
As usual, the source code for this article can be found over on GitHub.
![]()