1. Introduction
The OpenAPI specification (formerly Swagger specification) standardizes REST API documentation language and is platform agnostic. We can create OpenAPI documents in YAML or JSON formats.
On the other hand, Swagger is a collection of tools for implementing and working with the standard. Some are free, some are open-source, and some are commercial. These tools help us to design, document, and consume the REST APIs.
In this article, we'll learn how to format text descriptions in our OpenAPI documents.
2. OpenAPI Editors
Several tools support us in creating OpenAPI documents. A few popular tools are:
Several other editors provide support in creating OpenAPI documents. However, the most popular and widely used editor is Swagger Editor. Hence, we'll learn about formatting our OpenAPI documents with the help of Swagger Editor.
3. YAML vs. JSON Formatting
An OpenAPI document is represented either in JSON or YAML format. However, formatting the documentation is straightforward while using YAML.
For instance, to mark a word or a sentence as a heading, we use the below snippet in YAML:
description: |
# This is a heading in *italics*
This is in the next line
This is in **bold**The YAML representation uses a | (pipe) to represent scalar literals, which can be multi-line.
Now, Let's define the same thing in JSON:
{
"description": "# This is a heading in *italics*\nThis is in the next line\n\nThis is in **bold**
}Comparatively, in JSON representation, the escape sequences make the formatting counter-intuitive. Henceforth, we'll only look at formatting techniques for OpenAPI specification documents written in YAML.
Finally, OpenAPI specification allows the formatting of description fields at all levels. Thus, according to the specification, wherever the description field is permissible, we can format it, and the description field conforms to the CommonMark formatting style.
Now, let's enhance our API documents by formatting them.
4. Headings
Like we use <h1> to <h6> headings in HTML, we can use markdown headings to highlight the text. A # represents a heading. We can use # up to six levels to emphasize the text. The higher the number of #, the lesser the text emphasis is.
A text followed by a # is brighter and bigger than a text accompanied by ######.
For instance, consider the YAML:
openapi: 3.0.1
info:
title: Petstore
description: |
# Pet Store APIs
## This is a sample Petstore server
### Contains APIs to manage the pet store
#### Note that the APIs support Basic Authentication and OAUTH
##### The samples contain Request and Response models
###### There are status codes defined as wellSwagger renders the text as:

5. Text Emphasis
To enhance the readability of the description text, we can emphasize it by making it bold or italic.
Placing a text between ** and ** or within __ and __ makes the text bold. Similarly, placing the text within * and * or _ and _ will make the text italics. For instance, for the YAML:
openapi: 3.0.1
info:
title: Petstore
description: |
## This document contains
**Pet Store APIs** *Note: All the APIs return application/json*.
__User APIs__ _Note: These APIs contain attachments and only support image/jpeg as the content type_Swagger renders the YAML as:

6. Tables
Next, let's see how to add tables to our OpenAPI documents.
There are a set of rules to be followed to render tables. Firstly, each column in the table should start and end with a | (pipe) symbol. Secondly, divide each of the table headers with at least one – (hyphen) symbol. However, the maximum number of – (hyphen) is not restricted.
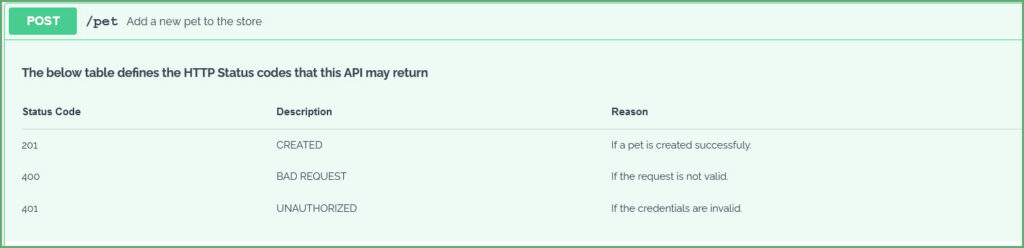
For instance, let's add a table to define HTTP status codes for our POST API:
paths:
/pet:
post:
tags:
- pet
description: |
**The below table defines the HTTP Status codes that this API may return**
| Status Code | Description | Reason |
| ---------------- | ------------| -----------------------------------|
| 201 | CREATED | If a pet is created successfuly. |
| 400 | BAD REQUEST | If the request is not valid. |
| 401 | UNAUTHORIZED| If the credentials are invalid. |Swagger generates:
7. Lists
Now, let's see how to format the description text to contain lists.
7.1. Ordered List
The description text items should start with a number followed by a . (period). However, the numbering order of the items isn't essential. That is, the snippets:
description: |
1. Available
3. Pending
1. Solddescription: |
1. Available
200. Pending
30. Solddescription: |
1. Available
100. Pending
50. Soldgenerate the same output:
1. Available
2. Pending
3. SoldThe numbering of the items depends on the starting item. For instance, if we start the item number with 10, the following items will be numbered 11, 12, 13, etc. The below YAML:
description: |
10. Available
120. Pending
50. Soldgenerates:
10. Available
11. Pending
12. SoldSimilarly, the same rules apply for ordered sub-lists as well. Indent a sub-list to its parent item. As an example, consider the YAML:
description: |
1. Available
2. Pending
1. Pending in Store
200. Pending in Cart
3. Soldwhich generates:
1. Available
2. Pending
1. Pending in Store
2. Pending in Cart
3. Sold7.2. Unordered List
Use * (asterisks) or + (plus) or a – (hyphen) to create an unordered list. That is, each item in the list should begin with one of these symbols. For example:
description: |
* Available
* Pending
* Sold
description: |
+ Available
+ Pending
+ Sold
description: |
- Available
- Pending
- Soldall the above snippets generate an unordered list.
Similarly, to generate unordered sub-lists, indent the items with their parent item and start with a * (asterisks) or + (plus) or a – (hyphen). For instance, the YAML:
- Available
- Pending
* Pending in Store
+ Pending in Cart
- Soldgenerates an unordered list with a sub-list. Note the mix and match of the delimiters. It is possible to mix the delimiters, which create the same results.
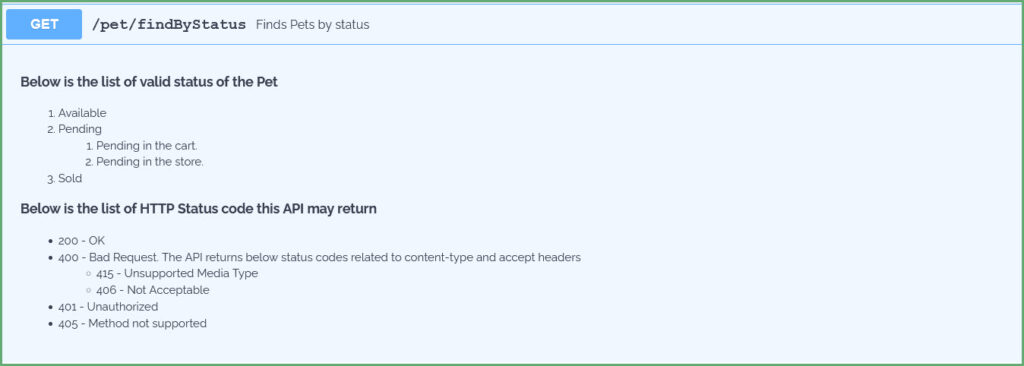
Finally, let's place all this together into a YAML:
/pet/findByStatus:
get:
summary: Finds Pets by status
description: |
__Below is the list of valid status of the Pet__
1. Available
2. Pending
1. Pending in the cart
2. Pending in the store
3. Sold
**Below is the list of HTTP Status code this API may return**
* 200 - OK
* 400 - Bad Request. The API returns below status codes related to content-type and accept headers
+ 415 - Unsupported Media Type
- 406 - Not Acceptable
* 401 - Unauthorized
* 405 - Method not supportedThis YAML generates:
8. Miscellaneous
8.1. Line Breaks and Paragraphs
description: |
Returns a single pet.
*Note: The API may throw a HTTP 404 if there are no pets found with a given id.*
The API returns a 200 OK if there is a pet with given Id. Also, this API returns the status of the pet
This YAML generates:

8.2. Code
description: |
The API returns user details for a given username.
The API can be invoked using *curl* like below:
```
curl --header accept: application/json -u username:password http://localhost:8080/api/v2/user/jhondoe
```
**Sample Output**
```
{
"id": 2,
"username": "jhondoe"
"email": "jhon.doe@mail.com"
}
```
8.3. Images
description: |
# Pet Store APIs

9. Conclusion
In this article, we have seen how to format the description field in our OpenAPI documents. YAML scalar literals enable the formatting of the description across the document. Consequently, an OpenAPI document can contain any or all of the supported constructs, such as lists, tables, and images.
Thus, documenting an API improves the ease of use. After all, well-documented and formatted APIs are what we all want for easy integrations and consumption.









