![]()
1. Overview
In this tutorial, we’ll discuss the various ways of finding a string among a group of strings using a single expression.
Let’s assume there’s a fruit “Apple” and a group of fruits “Mango”, “Papaya”, “Apple”, “Pineapple”, etc. Now we’ll explore the various ways to see if the string “Apple” is present among the group of fruits.
2. Introduction to the Problem
Before we move on to the next sections covering the single expression solution, let’s look at an implementation with the if condition:
boolean compareWithMultipleStringsUsingIf(String str, String ... strs) {
for(String s : strs) {
if (str.equals(s)) {
return true;
}
}
return false;
}
This is a very basic implementation, perhaps the most popular among all the implementations. We iterate through the array of Strings and return true when the String str matches with any one of the elements in strs.
Let’s see how this works:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingIf_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingIf(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingIf(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
We’re finding the presence of the Strings such as “Apple” and “Avacado” in a group of fruits. But this involves multiple lines of code. Hence let’s look at the upcoming sections for solutions involving a single expression.
3. Match With Set
java.util.Set has the contains() method which checks if an element exists in the collection. Hence, we’ll use java.util.Set for our use case with a single expression:
boolean compareWithMultipleStringsUsingSet(String str, String ... strs) {
return Set.of(strs).contains(str);
}
With a single expression, we’ve initialized a Set and then used the contains() method to see if str is present in the Set. However, we cannot implement a single expression case-insensitive matching method using Set.
Let’s test the method compareWithMultipleStringsUsingSet():
@Test
void givenStrings_whenCompareWithMultipleStringsUsingSet_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingSet(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingSet(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
Just like before, we first pass “Apple” to the method, and it returns true and when we pass “Avocado”, it returns false. Hence, that works pretty well.
4. Match With List
Similar to Set, List also has the contains() method. Hence let’s check out the implementation using List:
boolean compareWithMultipleStringsUsingList(String str, String ... strs) {
return List.of(strs).contains(str);
}
There isn’t much difference, we’ve replaced Set with List.
Let’s see it in action as well:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingList_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingList(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingList(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
The contains() method works as expected and it returns the correct result.
5. Match With Stream
The Stream API encourages the use of declarative statements and hence it can help us in implementing a single expression method:
boolean compareWithMultipleStringsUsingStream(String str, String ... strs) {
return Arrays.stream(strs).anyMatch(str::equals);
}
In a single expression, we converted the array of Strings into a Stream, and then we used the method anyMatch(). The method anyMatch() is a terminal operation in a Stream pipeline. Each element in the Stream is compared with the String str. However, the anyMatch() method returns the first match.
Let’s check out the method in action:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingStream_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingStream(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingStream(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
The method works as expected with “Apple” and “Avocado” as the first argument, returning true and false respectively.
Let’s see a case-insensitive version using Stream:
boolean compareCaseInsensitiveWithMultipleStringsUsingStream(String str, String ... strs) {
return Arrays.stream(strs).anyMatch(str::equalsIgnoreCase);
}
Unlike the earlier version we had to call the equalsIgnoreCase() method as a predicate to anyMatch().
We can now take a look at the method in action:
@Test
void givenStrings_whenCompareCaseInsensitiveWithMultipleStringsUsingStream_thenSuccess() {
String presentString = "APPLE";
String notPresentString = "AVOCADO";
assertTrue(compareCaseInsensitiveWithMultipleStringsUsingStream(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareCaseInsensitiveWithMultipleStringsUsingStream(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
This time it can find out “APPLE” among “Mango”, “Papaya”, “Pineapple”, and “Apple”.
6. Match With StringUtils
Before we can use the class StringUtils from the commons-lang3 library, let’s first update the pom.xml with its Maven dependency:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.13.0</version>
</dependency>
Now, let’s use the class StringUtils:
boolean compareWithMultipleStringsUsingStringUtils(String str, String ... strs) {
return StringUtils.equalsAny(str, strs);
}
The method equalsAny() in StringUtils helps implement our use case in a single expression.
Let’s see the method in action:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingStringUtils_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingStringUtils(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingStringUtils(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
This also works as expected, returning true and false when “Apple” and “Mango” are passed to the method, respectively.
Let’s take a look at the case-insensitive version of the method as well:
boolean compareCaseInsensitiveWithMultipleStringsUsingStringUtils(String str, String ... strs) {
return StringUtils.equalsAnyIgnoreCase(str, strs);
}
Instead of the method equalsAny() we used the method equalsAnyIgnoreCase() of StringUtils.
Let’s see how the method works:
@Test
void givenStrings_whenCompareCaseInsensitiveWithMultipleStringsUsingStringUtils_thenSuccess() {
String presentString = "APPLE";
String notPresentString = "AVOCADO";
assertTrue(compareCaseInsensitiveWithMultipleStringsUsingStringUtils(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareCaseInsensitiveWithMultipleStringsUsingStringUtils(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
We could successfully find the String “APPLE” among the group of fruits.
7. Match With ArrayUtils
Furthermore, we’ll see another class ArrayUtils from the same commons-lang library:
boolean compareWithMultipleStringsUsingArrayUtils(String str, String ... strs) {
return ArrayUtils.contains(strs, str);
}
ArrayUtils is a utility class that helps to check if an element is present in an array of objects. Hence, we exploited it to help us implement our use case involving Strings. Unfortunately, ArrayUtils doesn’t provide any method to find a String object in a case-insensitive way. Hence we cannot do a single expression implementation for the same.
Let’s see how the method compareWithAnyUsingArrayUtils() works:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingArrayUtils_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingArrayUtils(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingArrayUtils(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
Quite unsurprisingly, it works as well.
8. Match With Regular Expression
Regular expression helps find patterns and hence we’ll use it for our use case:
boolean compareWithMultipleStringsUsingRegularExpression(String str, String ... strs) {
return str.matches(String.join("|", strs));
}
The method String.join() creates a pipe-delimited list of Strings, for example, Mango|Papaya|Pineapple|Apple which is used as a regular expression pattern. In a single expression, we created the regular expression pattern with the array of Strings and then used the method matches() to check if the String str has the pattern.
Time to see the method in action:
@Test
void givenStrings_whenCompareWithMultipleStringsUsingRegularExpression_thenSuccess() {
String presentString = "Apple";
String notPresentString = "Avocado";
assertTrue(compareWithMultipleStringsUsingRegularExpression(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareWithMultipleStringsUsingRegularExpression(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
The method returns true for the argument “Mango” and false for “Avocado”. Hence, we can say it works too. However, regular expressions are always performance-intensive, so it’s better to avoid them.
Now, let’s take a look at the case-insensitive implementation:
boolean compareCaseInsensitiveWithMultipleStringsUsingRegularExpression(String str, String ... strs) {
return str.matches("(?i)" + String.join("|", strs));
}
We just had to modify the regular expression by prepending it with (?i) to do case-insensitive pattern matching.
Let’s take a look at the method in action:
@Test
void givenStrings_whenCompareCaseInsensitiveUsingRegularExpression_thenSuccess() {
String presentString = "APPLE";
String notPresentString = "AVOCADO";
assertTrue(compareCaseInsensitiveWithMultipleStringsUsingRegularExpression(presentString, "Mango", "Papaya", "Pineapple", "Apple"));
assertFalse(compareCaseInsensitiveWithMultipleStringsUsingRegularExpression(notPresentString, "Mango", "Papaya", "Pineapple", "Apple"));
}
By using the method now we can find “APPLE” in the provided group of fruits as well.
9. Benchmark
Let’s calculate the average execution time of each of the single expression methods using Java Microbenchmark Harness (JMH).
Let’s take a look at the class configured for carrying out the benchmark:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 2)
@Measurement(iterations = 5)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(value = 1)
public class CompareAnyBenchmark {
private final String[] groupOfFruits = {"Apple", "Mango", "Dragon Fruit", "Water Melon", "Avocado", "Guava", "Orange"};
private final String fruit = "Apple";
@Benchmark
public boolean compareWithMultipleStringsUsingStringUtils() {
return StringUtils.equalsAny(fruit, groupOfFruits);
}
@Benchmark
public boolean compareCaseInsensitiveWithMultipleStringsUsingStringUtils() {
return StringUtils.equalsAnyIgnoreCase(fruit, groupOfFruits);
}
//Other benchmark methods...
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder().include(CompareAnyBenchmark.class.getSimpleName())
.threads(1)
.shouldFailOnError(true)
.shouldDoGC(true)
.jvmArgs("-server")
.build();
new Runner(options).run();
}
}
The annotations at the class level set up the benchmark to measure the average time, in nanoseconds, taken for five runs of each method. Finally, the main() method is for running the benchmark.
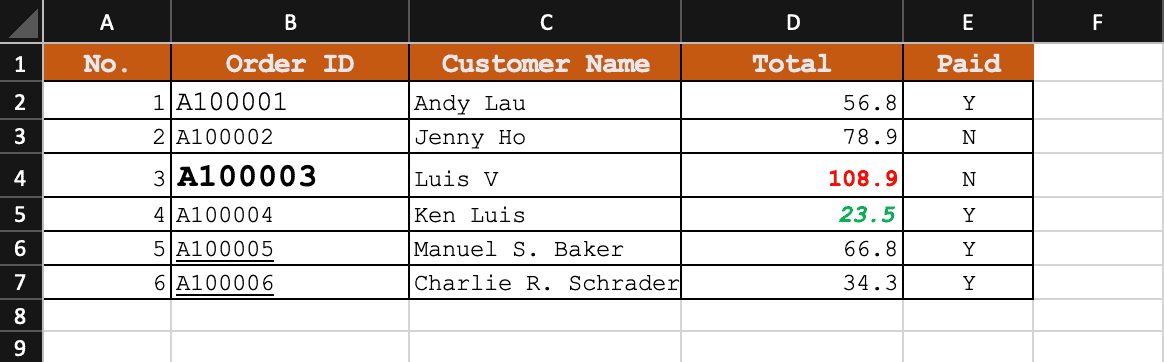
Let’s now take a look at the average execution time taken for each of the methods we discussed so far:
| Method Name |
Avg. Time |
Error(±) |
Unit |
| compareWithMultipleStringsUsingArrayUtils() |
1.150 |
0.031 |
ns/op |
| compareWithMultipleStringsUsingRegularExpression() |
1175.809 |
177.940 |
ns/op |
| compareWithMultipleStringsUsingSet() |
96.961 |
11.943 |
ns/op |
compareWithMultipleStringsUsingList()
|
28.718 |
1.612 |
ns/op |
| compareWithMultipleStringsUsingStream() |
47.266 |
3.968 |
ns/op |
| compareWithMultipleStringsUsingStringUtils |
1.507 |
0.040 |
ns/op |
| compareCaseInsensitiveWithMultipleStringsUsingRegularExpression() |
1803.497 |
645.104 |
ns/op |
| compareCaseInsensitiveWithMultipleStringsUsingStream() |
63.079 |
56.509 |
ns/op |
| compareCaseInsensitiveWithMultipleStringsUsingStringUtils() |
1.521 |
0.077 |
ns/op |
The methods compareCaseInsensitiveWithMultipleStringsUsingRegularExpression() and compareWithMultipleStringsUsingRegularExpression() using regular expressions take the longest to execute. On the other hand, the methods compareWithMultipleStringsUsingArrayUtils(), and compareWithMultipleStringsUsingStringUtils() take the least time to execute.
Without considering any external library, the methods compareWithMultipleStringsUsingStream(), and compareCaseInsensitiveWithMultipleStringsUsingStream() have the best score. Moreover, the performance also doesn’t vary much for case-insensitive searches.
10. Conclusion
In this article, we explored various ways to find the presence of a String in a group of Strings. With java.util.Set, java.util.List, java.util.Stream and regular expressions we didn’t use any external library outside of the JDK. Hence it’s advisable to use them rather than going for external libraries like commons-lang. Moreover, the List implementation is the best choice in the JDK library.
As usual, the code examples can be found over on GitHub.
![]()