In this tutorial, we’ll see how to avoid ambiguous method calls in the specific context of the Mockito framework.
In Java, method overloading allows a class to have multiple methods with the same name but different parameters. An ambiguous method call happens when the compiler can’t determine the concrete method to invoke based on the provided arguments.
Mockito is a mocking framework for unit testing Java applications. The latest version of the library can be found in the Maven Central Repository. Let’s add the dependency to our pom.xml:
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>5.11.0</version>
<scope>test</scope>
</dependency>ArgumentMatchers are part of the Mockito framework: thanks to them, we can specify the mocked method’s behavior when the arguments match given conditions.
First, let’s define a method that takes an Integer as a parameter and always return 1 as a result:
Integer myMethod(Integer i) {
return 1;
}For the sake of our demonstration, we’ll want our overloaded method to use a custom type. Thus, let’s define this dummy class:
class MyOwnType {}We can now add an overloaded myMethod() that accepts a MyOwnType object as an argument and always return baeldung as a result:
String myMethod(MyOwnType myOwnType) {
return "baeldung";
}Intuitively, if we pass a null argument to myMethod(), the compiler won’t know which version it should use. Moreover, we can note that the method’s return type has no impact on this problem.
Let’s naively try to mock a call to myMethod() with a null parameter by using the base isNull() ArgumentMatcher:
@Test
void givenMockedMyMethod_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(isNull())).thenReturn(1);
}Given we called the class where myMethod() is defined MyClass, we nicely injected a mocked MyClass object via the test’s method parameters. We can also note that we didn’t add any assertion to the test yet. Let’s run this code:
java.lang.Error: Unresolved compilation problem:
The method myMethod(Integer) is ambiguous for the type MyClass
As we can see, the compiler can’t decide which version of myMethod() to use, thus throwing an error. Let’s underline that the compiler’s decision is only based on the method argument. Since we wrote thenReturn(1) in our instruction, as readers, we could guess that the intention is to use the version of myMethod() that returns an Integer. However, the compiler won’t use this part of the instruction in its decision process.
To solve this problem, we need to use the overloaded isNull() ArgumentMatcher that takes a class as an argument instead. For instance, to tell the compiler it should use the version that takes an Integer as a parameter, we can write:
@Test
void givenMockedMyMethod_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(isNull(Integer.class))).thenReturn(1);
assertEquals(1, myClass.myMethod((Integer) null));
}We added an assertion to complete the test, and it now runs successfully. Similarly, we can modify our test to use the other version of the method:
@Test
void givenCorrectlyMockedNullMatcher_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(isNull(MyOwnType.class))).thenReturn("baeldung");
assertEquals("baeldung", myClass.myMethod((MyOwnType) null));
}Lastly, let’s notice that we needed to give the type of null in the call to myMethod() in the assertion as well. Otherwise, this would throw for the same reason!
In the same way, we can try to mock a myMethod() call that accepts any argument by using the any() ArgumentMatcher:
@Test
void givenMockedMyMethod_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(any())).thenReturn(1);
}Running this code once again results in an ambiguous method call error. All the remarks we made in the previous case are still valid here. In particular, the compiler fails before even looking at the thenReturn() method’s argument.
The solution is also similar: we need to use a version of the any() ArgumentMatcher that clearly states what is the type of the expected argument:
@Test
void givenMockedMyMethod_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(anyInt())).thenReturn(1);
assertEquals(1, myClass.myMethod(2));
}Most base Java types already have a Mockito method defined for this purpose. In our case, the anyInt() method will accept any Integer argument. On the other hand, the other version of myMethod() accepts an argument of our custom MyOwnType type. Thus, we’ll need to use the overloaded version of the any() ArgumentMatcher that takes the object’s type as an argument:
@Test
void givenCorrectlyMockedNullMatcher_whenMyMethod_ThenMockedResult(@Mock MyClass myClass) {
when(myClass.myMethod(any(MyOwnType.class))).thenReturn("baeldung");
assertEquals("baeldung", myClass.myMethod((MyOwnType) null));
}Our tests are now working fine: we successfully eliminated the ambiguous method call error!
In this article, we understood why we can face an ambiguous method call error with the Mockito framework. Additionally, we showcased the solution to the problem. In real life, this kind of problem is most likely to arise when we’ve got overloaded methods with tons of arguments, and we decide to use the less constraining isNull() or any() ArgumentMatcher because the value of some of the arguments isn’t relevant to our test. In simple cases, most modern IDEs can point out the problem before we even need to run the test.
As always, the code is available over on GitHub.
When we work with Java objects and need to convert them into JSON format, it’s crucial to handle null values appropriately. Omitting null values from the JSON output might not align with our data requirements, especially when data integrity is paramount.
In this tutorial, we’ll delve into effective methods for including null values during JSON serialization in Java.
Let’s consider that we’re developing a customer management system where each customer is a Java object with attributes like name, email, and age. Moreover, some customers may lack email addresses.
When serializing customer data into JSON for storage or transmission, including null values for missing email addresses is crucial to maintain data consistency.
For the sake of completeness, let’s define the Customer class used in our examples:
public class Customer {
@JsonProperty
private final String name;
@JsonProperty
private final String address;
@JsonProperty
private final int age;
public Customer(String name, String address, int age) {
this.name = name;
this.address = address;
this.age = age;
}
// ...
}Here, we define the Customer class which includes fields for name, address, and age, initialized through a constructor method. The toString() method also provides a string representation of the object in a JSON-like format for easy debugging.
Please note that including @JsonProperty annotations ensures that all relevant fields are accurately serialized into the JSON output, including null values when applicable.
Jackson, a renowned Java library for JSON processing, typically excludes null values from JSON output by default. However, we can leverage Jackson’s annotations to include null values explicitly:
String expectedJson = "{\"name\":\"John\",\"address\":null,\"age\":25}";
Customer obj = new Customer("John", null, 25);
@Test
public void givenObjectWithNullField_whenJacksonUsed_thenIncludesNullValue() throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
mapper.setSerializationInclusion(JsonInclude.Include.ALWAYS);
String json = mapper.writeValueAsString(obj);
assertEquals(expectedJson, json);
}In this method, we begin by establishing the expectedJson string. Subsequently, we instantiate a Customer object with values John, null, and 25.
Moving forward, we configure an ObjectMapper instance to consistently include null values during serialization by invoking the setSerializationInclusion() method with the parameter JsonInclude.Include.ALWAYS. This meticulous setup ensures that even if the address is null, it’s accurately represented in the resulting JSON output.
Lastly, we use the assertEquals() method to verify that the json string matches the expectedJson.
Gson is an alternative Java library that can be used for JSON serialization and deserialization. It offers similar options to include null values explicitly. Let’s see an example:
@Test
public void givenObjectWithNullField_whenGsonUsed_thenIncludesNullValue() {
Gson gson = new GsonBuilder().serializeNulls().create();
String json = gson.toJson(obj);
assertEquals(expectedJson, json);
}Here, we employ the GsonBuilder to set up a Gson instance using the serializeNulls() method. This configuration ensures that null values are incorporated during serialization, ensuring precise representation in the resulting JSON output, even if the address field is null.
In conclusion, it’s essential to handle null values appropriately when working with Java objects and converting them into JSON format.
In this tutorial, we learned how to do it during JSON serialization.
As always, the source code for the examples is available over on GitHub.
In this tutorial, we’ll review the @Subselet annotation in Hibernate, how to use it, and its benefits. We’ll also see Hibernate’s constraints on entities annotated as @Subselect and their consequences.
@Subselect allows us to map an immutable entity to the SQL query. So let’s unroll this explanation a bit, starting from what entity to SQL query mapping even means.
Normally, when we create our entities in Hibernate, we annotate them with @Entity. This annotation indicates that this is an entity, and it should be managed by persistence context. We may, optionally, provide @Table annotation as well to indicate to what table Hibernate should map this entity exactly. So, by default, whenever we create an entity in Hibernate, it assumes that an entity is mapped directly to a particular table. In most cases, that is exactly what we want, but not always.
Sometimes, our entity is not directly mapped into a particular table in DB but is a result of a SQL query execution. As an example, we might have a Client entity, where each instance of this entity is a row in a ResultSet of a SQL query (or SQL view) execution:
SELECT
u.id as id,
u.firstname as name,
u.lastname as lastname,
r.name as role
FROM users AS u
INNER JOIN roles AS r
ON r.id = u.role_id
WHERE u.type = 'CLIENT'The important thing is that there might be no dedicated clients table in DB at all. So that’s what mapping an entity into a SQL query means – we fetch entities from a sub-select SQL query, not from a table. This query may select from any tables and perform any logic within – Hibernate doesn’t care.
So, we may have an entity that is not mapped to a particular table. As a direct consequence, it is unclear how to perform any INSERT/UPDATE statements. There is simply no clients (as in the example above) table that we can just insert records to.
Indeed, Hibernate doesn’t have a clue about what kind of SQL we execute to retrieve the data. Therefore, Hibernate cannot do any write operations on such an entity – it becomes read-only. The tricky thing here is that we can still ask Hibernate to insert this entity, but it will fail since it is impossible (at least according to ANSI SQL) to issue an INSERT into the sub-select.
Now, once we understand what @Subselect annotation does, let’s try to get our hands dirty and try to use it. Here, we have a simple RuntimeConfiguration:
@Data
@Entity
@Immutable
// language=sql
@Subselect(value = """
SELECT
ss.id,
ss.key,
ss.value,
ss.created_at
FROM system_settings AS ss
INNER JOIN (
SELECT
ss2.key as k2,
MAX(ss2.created_at) as ca2
FROM system_settings ss2
GROUP BY ss2.key
) AS t ON t.k2 = ss.key AND t.ca2 = ss.created_at
WHERE ss.type = 'SYSTEM' AND ss.active IS TRUE
""")
public class RuntimeConfiguration {
@Id
private Long id;
@Column(name = "key")
private String key;
@Column(name = "value")
private String value;
@Column(name = "created_at")
private Instant createdAt;
}
This entity represents a runtime parameter of our application. But, to just return the set of the up-to-date parameters that belong to our application, we need to execute a specific SQL query over system_settings table. As we can see, @Subselect annotation’s body contains that SQL statement. Now, because each RuntimeConfiguration entry is essentially a key value pair, we might want to implement a simple query – fetch the most recent active RuntimeConfiguration record that has a specific key.
Please also note that we marked our entity with @Immutable. Hibernate will, therefore, disable any dirty check tracking for our entity to avoid accidental UPDATE statements.
So, if we want to fetch RuntimeConfiguration with a specific key, we can do something like this:
@Test
void givenEntityMarkedWithSubselect_whenSelectingRuntimeConfigByKey_thenSelectedSuccessfully() {
String key = "config.enabled";
CriteriaBuilder criteriaBuilder = entityManager.getCriteriaBuilder();
CriteriaQuery<RuntimeConfiguration> query = criteriaBuilder.createQuery(RuntimeConfiguration.class);
var root = query.from(RuntimeConfiguration.class);
RuntimeConfiguration configurationParameter = entityManager
.createQuery(query.select(root).where(criteriaBuilder.equal(root.get("key"), key))).getSingleResult();
Assertions.assertThat(configurationParameter.getValue()).isEqualTo("true");
}Here, we’re using Hibernate Criteria API to query RuntimeConfiguration by key. Now, let’s check what query Hibernate actually produces in order to fulfill our request:
select
rc1_0.id,
rc1_0.created_at,
rc1_0.key,
rc1_0.value
from
( SELECT
ss.id,
ss.key,
ss.value,
ss.created_at
FROM
system_settings AS ss
INNER JOIN
( SELECT
ss2.key as k2, MAX(ss2.created_at) as ca2
FROM
system_settings ss2
GROUP BY
ss2.key ) AS t
ON t.k2 = ss.key
AND t.ca2 = ss.created_at
WHERE
ss.type = 'SYSTEM'
AND ss.active IS TRUE ) rc1_0
where
rc1_0.key=?As we can see, Hibernate just selects records from the SQL statement provided in @Subselect. Now, each filter that we provide will be applied to a resulting subselect records set.
Experienced Hibernate developers might notice that there are already some ways to achieve a similar result. One of these is using projection mapping into a DTO, and another is view mapping. Those two have their pros and cons. Let’s discuss them one by one.
So, let’s talk about DTO projections a bit. It allows the SQL queries to be mapped into a DTO projection that is not an entity. It is also considered faster to work with DTO projections than with entities. DTO projections are also immutable, which means Hibernate doesn’t manage such entities and doesn’t apply any dirty checks on them.
Though all of the above is true, DTO projections themselves have limitations. One of the most important is that DTO projections do not support associations. This is pretty obvious since we’re dealing with a DTO projection, which is not a managed entity. That makes DTO projections fast in Hibernate, but it also implies that Persistence Context does not manage these DTOs. So, we cannot have any OneToX or ManyToX fields on DTOs.
However, if we’re mapping an entity to an SQL statement, we’re still mapping an entity. It might have managed associations. So, this constraint is not applicable to entity-to-query mapping.
Another significant, essential, and conceptual difference is that @Subselect allows us to represent the entity as an SQL query. Hibernate will do what the annotation name suggests. It’ll just use the provided SQL query to select from it (so our query becomes a sub-select) and then apply additional filters. So, let’s assume that to fetch entity X, we need to perform some filtering, grouping, etc.. Then, if we use DTO projections, we would always have to write filters, groupings, etc., down in each JPQL or native query. When using @Subselect, we can specify this query once and select from it.
Although this is not widely known, Hibernate can map our entities to SQL views out of the box. That is very similar regarding entity to SQL query mapping. The view itself is almost always read-only in DB. Some exceptions exist in different RDBMS, like simple views in PostgreSQL, but that is entirely vendor-specific. It implies that our entities are also immutable, and we’ll just read from the underlying view, we won’t update/insert any data.
In general, the difference between @Subselect and entity-to-view mapping is very small. The former uses the exact SQL statement that we provide in annotation, while the latter uses an existing view. Both approaches support managed associations, so choosing one of these options entirely depends on our requirements.
In this article, we discussed how to use @Subselect to select entities not from a particular table but from a sub-select query. This is very convenient if we do not want to duplicate the same parts of SQL statements to fetch our entities. But this implies that our entities that use @Subselect are de-facto immutable, and we should not try to persist them from the application code. There are some alternatives to @Subselect, for instance, entity to view mapping in Hibernate or even DTO projection usage. They both have their advantages and disadvantages, therefore in order to make a choice we need to, as always, comply to requirements and common sense.
As always, the source code is available over on GitHub.
>> Java 22 Delivers Foreign Memory & Memory API, Unnamed Variables & Patterns, and Return of JavaOne [infoq.com]
Last week, we celebrated the release of Java 22, but now it’s time to look into the amazing new features… and have a glimpse at what’s coming to Java 23!
>> Spring: Internals of RestClient [foojay.io]
RestTemplate is deprecated, and it’s time to dig deeper into its successor – the mighty RestClient 
>> Reflectionless Templates With Spring [spring.io]
Template engines that don’t rely on reflection? Very cool
Webinars and presentations:
Time to upgrade:
>> Localize applications with AI [foojay.io]
Another cool use case for AI – localization. Seems to work pretty well.
>> TDD: You’re Probably Doing It Just Fine [thecodewhisperer.com]
You don’t need to do TDD all the time – it’s ok to apply it selectively.
Also worth reading:
>> Context-switching – one of the worst productivity killers in the engineering industry [eng-leadership.com]
Map is an efficient structure for key-value storage and retrieval.
In this tutorial, we’ll explore different approaches to finding map keys with duplicate values in a Set. In other words, we aim to transform a Map<K, V> to a Map<V, Set<K>>.
Let’s consider a scenario where we possess a map that stores the association between developers and the operating systems they primarily work on:
Map<String, String> INPUT_MAP = Map.of(
"Kai", "Linux",
"Eric", "MacOS",
"Kevin", "Windows",
"Liam", "MacOS",
"David", "Linux",
"Saajan", "Windows",
"Loredana", "MacOS"
);Now, we aim to find the keys with duplicate values, grouping different developers that use the same operating system in a Set:
Map<String, Set<String>> EXPECTED = Map.of(
"Linux", Set.of("Kai", "David"),
"Windows", Set.of("Saajan", "Kevin"),
"MacOS", Set.of("Eric", "Liam", "Loredana")
);While we primarily handle non-null keys and values, it’s worth noting that HashMap allows both null values and one null key. Therefore, let’s create another input based on INPUT_MAP to cover scenarios involving null keys and values:
Map<String, String> INPUT_MAP_WITH_NULLS = new HashMap<String, String>(INPUT_MAP) {{
put("Tom", null);
put("Jerry", null);
put(null, null);
}};As a result, we expect to obtain the following map:
Map<String, Set<String>> EXPECTED_WITH_NULLS = new HashMap<String, Set<String>>(EXPECTED) {{
put(null, new HashSet<String>() {{
add("Tom");
add("Jerry");
add(null);
}});
}};We’ll address various approaches in this tutorial. Next, let’s dive into the code.
In our first idea to solve the problem, we initialize an empty HashMap<V, Set<K>> and populate it using in a classic for-each loop:
static <K, V> Map<V, Set<K>> transformMap(Map<K, V> input) {
Map<V, Set<K>> resultMap = new HashMap<>();
for (Map.Entry<K, V> entry : input.entrySet()) {
if (!resultMap.containsKey(entry.getValue())) {
resultMap.put(entry.getValue(), new HashSet<>());
}
resultMap.get(entry.getValue())
.add(entry.getKey());
}
return resultMap;
}As the code shows, transformMap() is a generic method. Within the loop, we use each entry’s value as the key for the resultant map and collect values associated with the same key into a Set.
transformMap() does the job no matter whether the input map contains null keys or values:
Map<String, Set<String>> result = transformMap(INPUT_MAP);
assertEquals(EXPECTED, result);
Map<String, Set<String>> result2 = transformMap(INPUT_MAP_WITH_NULLS);
assertEquals(EXPECTED_WITH_NULLS, result2);Java 8 brought forth a wealth of new capabilities, simplifying collection operations with tools like the Stream API. Furthermore, it enriched the Map interface with additions such as computeIfAbsent().
In this section, we’ll tackle the problem using the functionalities introduced in Java 8.
The groupingBy() collector, which ships with the Stream API, allows us to group stream elements based on a classifier function, storing them as lists under corresponding keys in a Map.
Hence, we can construct a stream of Entry<K, V> and employ groupingBy() to collect the stream into a Map<V, List<K>>. This aligns closely with our requirements. The only remaining step is converting the List<K> into a Set<K>.
Next, let’s implement this idea and see how to convert List<K> to a Set<K>:
Map<String, Set<String>> result = INPUT_MAP.entrySet()
.stream()
.collect(groupingBy(Map.Entry::getValue, mapping(Map.Entry::getKey, toSet())));
assertEquals(EXPECTED, result);As we can see in the above code, we used the mapping() collector to map the grouped result (List) to a different type (Set).
Compared to our transformMap() solution, the groupingBy() approach is easier to read and understand. Furthermore, as a functional solution, this approach allows us to apply further operations fluently.
However, the groupingBy() solution raises NullPointerException when it transforms our INPUT_MAP_WITH_NULLS input:
assertThrows(NullPointerException.class, () -> INPUT_MAP_WITH_NULLS.entrySet()
.stream()
.collect(groupingBy(Map.Entry::getValue, mapping(Map.Entry::getKey, toSet()))));This is because groupingBy() cannot handle null keys:
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,...){
...
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
...
}Next, let’s see if we can build a solution for both non-null and nullable keys or values.
Java 8’s forEach() provides a concise way to iterate collections. computeIfAbsent() computes a new value for a specified key if the key is not already associated with a value or is mapped to null.
Next, let’s combine these two methods to solve our problem:
Map<String, Set<String>> result = new HashMap<>();
INPUT_MAP.forEach((key, value) -> result.computeIfAbsent(value, k -> new HashSet<>())
.add(key));
assertEquals(EXPECTED, result);This solution follows the same logic as transformMap(). However, with the power of Java 8, the implementation is more elegant and compact.
Furthermore, the forEach() + computeIfAbsent() solution works with maps containing null keys or values:
Map<String, Set<String>> result2 = new HashMap<>();
INPUT_MAP_WITH_NULLS.forEach((key, value) -> result2.computeIfAbsent(value, k -> new HashSet<>())
.add(key));
assertEquals(EXPECTED_WITH_NULLS, result2);Guava, a widely used library, offers the Multimap interface, enabling the association of a single key with multiple values.
Now, let’s develop solutions based on Multimaps to address our problem.
We’ve seen how the Java Stream API empowers us to craft compact, concise, and functional implementations. Guava provides Multimap collectors, such as Multimaps.toMultimap(), that allow us to collect elements from a stream into a Multimap conveniently.
Next, let’s see how to combine a stream and Multimaps.toMultimap() to solve the problem:
Map<String, Set<String>> result = INPUT_MAP.entrySet()
.stream()
.collect(collectingAndThen(Multimaps.toMultimap(Map.Entry::getValue, Map.Entry::getKey, HashMultimap::create), Multimaps::asMap));
assertEquals(EXPECTED, result);The toMultimap() method takes three arguments:
Thus, toMultimap() collect Map.Entry<K, V> objects into a SetMultimap<V, K>. Then, we employed collectingAndThen() to perform Multimaps.asMap() to convert the collected SetMultimap<V, K> to a Map<V, Set<K>>.
This approach works with maps holding null keys or values:
Map<String, Set<String>> result2 = INPUT_MAP_WITH_NULLS.entrySet()
.stream()
.collect(collectingAndThen(Multimaps.toMultimap(Map.Entry::getValue, Map.Entry::getKey, HashMultimap::create), Multimaps::asMap));
assertEquals(EXPECTED_WITH_NULLS, result2);Alternatively, we can use Multimaps.invertFrom() and Multimaps.forMap() to achieve our goal:
SetMultimap<String, String> multiMap = Multimaps.invertFrom(Multimaps.forMap(INPUT_MAP), HashMultimap.create());
Map<String, Set<String>> result = Multimaps.asMap(multiMap);
assertEquals(EXPECTED, result);
SetMultimap<String, String> multiMapWithNulls = Multimaps.invertFrom(Multimaps.forMap(INPUT_MAP_WITH_NULLS), HashMultimap.create());
Map<String, Set<String>> result2 = Multimaps.asMap(multiMapWithNulls);
assertEquals(EXPECTED_WITH_NULLS, result2);The forMap() method returns a Multimap<K, V> view of the specified Map<K, V>. Subsequently, as the name implies, invertFrom() converts the Multimap<K, V> view to a Multimap<V, K> and transfers it to the target Multimap provided as the second argument. Finally, we use Multimaps.asMap() again to convert Multimap<V, K> to Map<V, Set<K>>.
Also, as we can see, this approach works maps with null keys or values.
In this article, we’ve explored various ways to find map keys with duplicate values in a Set, including a classic loop-based solution, Java 8-based solutions, and approaches using Guava.
As always, the complete source code for the examples is available over on GitHub.
In this tutorial, we’ll look at taking a Collection of intervals and merging any that overlap.
First, let’s define what an interval is. We’ll describe it as a pair of numbers where the second is greater than the first. This could also be dates, but we’ll stick with integers here. So for example, an interval could be 2 -> 7, or 100 -> 200.
We can create a simple Java class to represent an interval. We’ll have start as our first number and end as our second and higher number:
class Interval {
int start;
int end;
// Usual constructor, getters, setters and equals functions
}Now, we want to take a Collection of Intervals and merge any that overlap. We can define overlapping intervals as anywhere the first interval ends after the second interval starts. For example, if we take two intervals 2 -> 10 and 5 -> 15 we can see that they overlap and the result of merging them would be 2 -> 15.
To perform the merge we’ll need code following this pattern:
List<Interval> doMerge(List<Interval> intervals) {
// Sort the intervals based on the start
intervals.sort((one, two) -> one.start - two.start);
// Create somewhere to put the merged list, start it off with the earliest starting interval
ArrayList<Interval> merged = new ArrayList<>();
merged.add(intervals.get(0));
// Loop over each interval and merge if start is before the end of the
// previous interval
intervals.forEach(interval -> {
if (merged.get(merged.size() - 1).end > interval.start) {
merged.get(merged.size() - 1).setEnd(interval.end);
} else {
merged.add(interval);
}
});
return merged;
}To start we’ve defined a method that takes a List of Intervals and returns the same but sorted. Of course, there are other types of Collections our Intervals could be stored in, but we’ll use a List today.
The first step in the processing we need to take is to sort our Collection of Intervals. We’ve sorted based on the Interval’s start so that when we loop over them each Interval is followed by the one most likely to overlap with it.
We can use List.sort() to do this assuming our Collection is a List. However, if we had a different kind of Collection we’d have to use something else. List.sort() takes a Comparator and sorts in place, so we don’t need to reassign our variable. For our Comparator, we can subtract the start of the second Interval from the start of the first. This results in higher starts being placed after lower starts in our Collection.
Next, we need somewhere to put the results of our merging process. We’ve created an ArrayList called merged for this purpose. We can also get it started by putting in the first interval as we know it has the earliest start.
Now for the interesting part. We need to loop over every Interval and do one of two things. If the Interval starts before the end of the previous Interval, we merge them by setting the end of the previous Interval to the end of the current Interval. Alternatively, if the Interval starts after the end of the previous Interval we simply add it to the Collection.
Finally, we returned the list of merged Intervals.
Let’s see that method in action with a test. We can define four Intervals we want to merge:
ArrayList<Interval> intervals = new ArrayList<>(Arrays.asList(
new Interval(2, 5),
new Interval(13, 20),
new Interval(11, 15),
new Interval(1, 3)
));After merging we’d expect the result to be only two Intervals:
ArrayList<Interval> intervalsMerged = new ArrayList<>(Arrays.asList(
new Interval(1, 5),
new Interval(11, 20)
));We can now use the method we created earlier and confirm it works as expected:
@Test
void givenIntervals_whenMerging_thenReturnMergedIntervals() {
MergeOverlappingIntervals merger = new MergeOverlappingIntervals();
ArrayList<Interval> result = (ArrayList<Interval>) merger.doMerge(intervals);
assertArrayEquals(intervalsMerged.toArray(), result.toArray());
}In this article, we learned how to merge overlapping intervals in a Collection in Java. We saw that the process of merging the intervals is fairly simple. First, we have to know how to properly sort them, by start value. Then we just have to understand that we need to merge them when one interval starts before the previous one ends.
As always, the full code for the examples is available over on GitHub.
Selenium offers plenty of methods to locate elements on a webpage, and we often need to find an element based on its attribute.
Attributes are additional pieces of information that can be added to provide more context or functionality. They can be broadly categorized into two types:
In this tutorial, we’ll dive into using CSS to pinpoint elements on a web page. We’ll explore finding elements by their attribute name or description, with options for both full and partial matches. By the end, we’ll be masters at finding any element on a page with ease!
One of the simplest scenarios is finding elements based on the presence of a specific attribute. Consider a webpage with multiple buttons, each tagged with a custom attribute called “data-action.” Now, let’s say we want to locate all buttons on the page with this attribute. In such cases, we can use [attribute] locator:
driver.findElements(By.cssSelector("[data-action]"));In the code above, the [data-action] will select all elements on a page with a target attribute, and we’ll receive a list of WebElements.
When we need to locate a concrete element with a unique attribute value, we can use the strict match variant of the CSS locator [attribute=value]. This method allows us to find elements with exact attribute value matches.
Let’s proceed with our web page where buttons have a “data-action” attribute, each assigned a distinct action value. For instance, data-action=’delete’, data-action=’edit’, and so forth. If we want to locate buttons with a particular action, such as “delete”, we can employ the attribute selector with an exact match:
driver.findElement(By.cssSelector("[data-action='delete']"));In situations where the exact attribute value may vary but starts from a specific substring, we can use another approach.
Let’s consider a scenario where our application has many pop-ups, each featuring an “Accept” button with a custom attribute named “data-action”. These buttons may have distinct identifiers appended after a shared prefix, such as “btn_accept_user_pop_up”, “btn_accept_document_pop_up”, and so forth. We can write a universal locator in the base class using [attribute^=value] locator:
driver.findElement(By.cssSelector("[data-action^='btn_accept']"));This locator will find an element where the “data-action” attribute value starts from “btn_accept”, so we can write a base class with a universal “Accept” button locator for each pop-up.
Similarly, when our attribute value ends with a specific suffix, let’s use [attribute$=value]. Imagine that we have a list of URLs on a page and want to get all PDF document references:
driver.findElements(By.cssSelector("[href^='.pdf']"));In this example, the driver will find all elements where “href” attribute value ends with “.pdf”.
When we’re not sure about our attribute prefix or suffix, there will be helpful a contains approach [attribute*=value]. Let’s consider a scenario where we want to get all elements with a reference to a specific resource path:
driver.findElements(By.cssSelector("[href*='archive/documents']"));In this example, we’ll receive all elements with reference to a document from the archive folder.
We can locate an element by using its class as an attribute. This is a common technique, especially when checking if an element is enabled, disabled, or has gained some other capability reflected in its class. Consider that we want to find a disabled button:
<a href="#" class="btn btn-primary btn-lg disabled" role="button" aria-disabled="true">Accept</a>This time, let’s use a strict match for the role and contain a match for a class:
driver.findElement(By.cssSelector("[role='button'][class*='disabled']"));In this example, “class” was used as attribute locator [attribute*=value] and detected in value “btn btn-primary btn-lg disabled” a “disabled” part.
In this tutorial, we’ve explored different ways to locate elements based on their attributes.
We’ve categorized attributes into two main types: standard, which are recognized by browsers and have predefined meanings, and custom, which are created by developers to fulfill specific requirements.
Using CSS selectors, we’ve learned how to efficiently find elements based on attribute names, values, prefixes, suffixes, or even substrings. Understanding these methods gives us powerful tools to locate elements easily, making our automation tasks smoother and more efficient.
As always, all code examples are available over on GitHub.
In this tutorial, we’ll review Hibernate’s @Struct annotation which let’s developers create structured user-defined types.
Support for structured user-defined types, a.k.a structured types, was introduced in the SQL:1999 standard, which was a feature of object-relational (ORM) databases.
Structured or composite types have their use cases, especially since support for JSON was introduced in the SQL:2016 standard. Values of these structured types provide access to their sub-parts and do not have an identifier or primary key like a row in a table.
Hibernate lets you specify structured types through the annotation type @Struct for the class annotated with the @Embeddable annotation or the @Embedded attribute.
Consider the below example of a Department class which has an @Embedded Manager class (a structured type):
@Entity
public class Department {
@Id
@GeneratedValue
private Integer id;
@Column
private String departmentName;
@Embedded
private Manager manager;
}The Manager class defined with @Struct annotation is given below:
@Embeddable
@Struct(name = "Department_Manager_Type", attributes = {"firstName", "lastName", "qualification"})
public class Manager {
private String firstName;
private String lastName;
private String qualification;
}A class annotated with @Struct maps the class to the structured user-defined type in the database. For example, without the @Struct annotation, the @Embedded Manager object, despite being a separate type, will be part in the Department table as shown in the DDL below:
CREATE TABLE DEPRARTMENT (
Id BIGINT,
DepartmentName VARCHAR,
FirstName VARCHAR,
LastName VARCHAR,
Qualification VARCHAR
);The Manager class, with the @Struct annotation, will produce a user-defined type similar to:
create type Department_Manager_Type as (
firstName VARCHAR,
lastName VARCHAR,
qualification VARCHAR
)With the added @Struct annotation, the Department object as shown in the DDL below:
CREATE TABLE DEPRARTMENT (
Id BIGINT,
DepartmentName VARCHAR,
Manager Department_Manager_Type
);Since a structured type has multiple attributes, the order of the attributes is very important for mapping data to the right attributes. One way to define the order of attributes is through the “attributes” field of the @Struct annotation.
In the Manager class above, you can see the “attributes” field of the @Struct annotation, which specifies that Hibernate expects the order of the Manager attributes (while Serializing and De-serializing it) to be “firstName”, “lastName” and finally “qualification”.
The second way to define the order of attributes is by using a Java record to implicitly specify the order through the canonical constructor, for example:
@Embeddable
@Struct(name = "Department_Manager")
public record Manager(String lastName, String firstName, String qualification) {}Above, the Manager record attributes will have the following order: “lastName”, “firstName” and “qualification”.
Since JSON is a predefined unstructured type, no type name or attribute order has to be defined. Mapping an @Embeddable as JSON can be done by annotating the embedded field/property with @JdbcTypeCode(SqlTypes.JSON).
For example, the below class holds a Manager object which is also a JSON unstructured type:
@Entity
public class Department_JsonHolder {
@Id
@GeneratedValue
private int id;
@JdbcTypeCode(SqlTypes.JSON)
@Column(name = "department_manager_json")
private Manager manager;
}Below is the expected DDL code for the class above:
create table Department_JsonHolder as (
id int not null primary key,
department_manager_json json
)Below is the example HQL query to select attributes from the department_manager_json column:
select djh.manager.firstName, djh.manager.lastName, djh.manager.qualifications
from department_jsonholder djhThe difference between an @Embeddable and an @Embeddable @Struct is that the latter is actually a user-defined type in the underlying database. Although many databases support user-defined types, the hibernate dialects that have support for @Struct annotation are:
In this article, we discussed Hibernate’s @Struct annotation, how to use it, and when to add it to a domain class.
The source code for the article is available over on GitHub.
In this tutorial, we’ll explore a few different ways to get the last n characters from a String.
Let’s pretend that we have the following String whose value represents a date:
String s = "10-03-2024";From this String, we want to extract the year. In other words, we want just the last four characters, so, n is:
int n = 4;We can use an overload of the substring() method that obtains the characters starting inclusively at the beginIndex and ending exclusively at the endIndex:
@Test
void givenString_whenUsingTwoArgSubstringMethod_thenObtainLastNCharacters() {
int beginIndex = s.length() - n;
String result = s.substring(beginIndex, s.length());
assertThat(result).isEqualTo("2024");
}Since we want the last n characters, we first determine our beginIndex by subtracting n from the length of the String. Finally, we supply the endIndex as simply the length of the String.
And since we’re only interested in the last n characters, we can make use of the more convenient overload of the substring() method that only takes the beginIndex as a method argument:
@Test
void givenString_whenUsingOneArgSubstringMethod_thenObtainLastNCharacters() {
int beginIndex = s.length() - n;
assertThat(s.substring(beginIndex)).isEqualTo("2024");
}This method returns the characters ranging from the beginIndex inclusively and terminates at the end of the String.
Finally, it’s worth mentioning the existence of the subSequence() method of the String class, which uses substring() under the hood. Even though it could be used to solve our use case, it would be considered more appropriate to just use the substring() method from a readability perspective.
To use Apache Commons Lang 3, we need to add its dependency to our pom.xml:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.14.0</version>
</dependency>We can use the StringUtils.right() method to obtain the last n characters:
@Test
void givenString_whenUsingStringUtilsRight_thenObtainLastNCharacters() {
assertThat(StringUtils.right(s, n)).isEqualTo("2024");
}Here, we just need to supply the String in question and the number of characters we want to return from the end of the String. Thus, this would be the preferred solution for our use case as we remove the need to calculate indexes, resulting in more maintainable and bug-free code.
Now, let’s explore what a functional programming solution might look like.
One option for our Stream source would be to use the chars() method. This method returns an IntStream whose primitive int elements represent the characters in the String:
@Test
void givenString_whenUsingIntStreamAsStreamSource_thenObtainLastNCharacters() {
String result = s.chars()
.mapToObj(c -> (char) c)
.skip(s.length() - n)
.map(String::valueOf)
.collect(Collectors.joining());
assertThat(result).isEqualTo("2024");
}Here, we use the mapToObj() intermediate operation to convert each int element to a Character object. Now that we have a Character stream, we can use the skip() operation to retain only the elements after a certain index.
Next, we use the map() operation with the String::valueOf method reference. We convert each Character element to a String because we want to use the terminal collect() operation with the Collectors.joining() static method.
Another functional approach uses the toCharArray() method initially instead:
@Test
void givenString_whenUsingStreamOfCharactersAsSource_thenObtainLastNCharacters() {
String result = Arrays.stream(ArrayUtils.toObject(s.toCharArray()))
.skip(s.length() - n)
.map(String::valueOf)
.collect(Collectors.joining());
assertThat(result).isEqualTo("2024");
}This method returns an array of char primitives. We can use the ArrayUtils.toObject() from Apache Commons Lang 3 to convert our array to an array of Character elements. Finally, we obtain a Character stream using the static method Arrays.stream(). From here, our logic remains the same to obtain the last n characters.
As we can see above, we need to do a lot of work to achieve our goal using a functional programming approach. This highlights that functional programming should only be used when it’s appropriate to do so.
In this article, we’ve explored several different ways to get the last n characters from a String. We highlighted that an imperative approach over a functional one yielded a more concise and readable solution. We should note that the examples of extracting the year from a String explored in this article were just for demonstration purposes. More appropriate ways of achieving this exist such as parsing the String as a LocalDate and using the getYear() method.
As always, the code samples used in this article are available over on GitHub.
Grafana Labs developed Loki, an open-source log aggregation system inspired by Prometheus. Its purpose is to store and index log data, facilitating efficient querying and analysis of logs generated by diverse applications and systems.
In this article, we’ll set up logging with Grafana Loki for a Spring Boot application. Loki will collect and aggregate the application logs, and Grafana will display them.
We’ll first spin up Loki and Grafana services so that we can collect and observe logs. Docker containers will help us to more easily configure and run them.
First, let’s compose Loki and Grafana services in a docker-compose file:
version: "3"
networks:
loki:
services:
loki:
image: grafana/loki:2.9.0
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yaml
networks:
- loki
grafana:
environment:
- GF_PATHS_PROVISIONING=/etc/grafana/provisioning
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
entrypoint:
- sh
- -euc
- |
mkdir -p /etc/grafana/provisioning/datasources
cat <<EOF > /etc/grafana/provisioning/datasources/ds.yaml
apiVersion: 1
datasources:
- name: Loki
type: loki
access: proxy
orgId: 1
url: http://loki:3100
basicAuth: false
isDefault: true
version: 1
editable: false
EOF
/run.sh
image: grafana/grafana:latest
ports:
- "3000:3000"
networks:
- lokiNext, we need to bring up the services using the docker-compose command:
docker-compose upFinally, let’s confirm if both services are up:
docker ps
211c526ea384 grafana/loki:2.9.0 "/usr/bin/loki -conf…" 4 days ago Up 56 seconds 0.0.0.0:3100->3100/tcp surajmishra_loki_1
a1b3b4a4995f grafana/grafana:latest "sh -euc 'mkdir -p /…" 4 days ago Up 56 seconds 0.0.0.0:3000->3000/tcp surajmishra_grafana_1Once we’ve spun up Grafana and the Loki service, we need to configure our application to send logs to it. We’ll use loki-logback-appender, which will be responsible for sending logs to the Loki aggregator to store and index logs.
First, we need to add loki-logback-appender in the pom.xml file:
<dependency>
<groupId>com.github.loki4j</groupId>
<artifactId>loki-logback-appender</artifactId>
<version>1.4.1</version>
</dependency>Second, we need to create a logging-spring.xml file under the src/main/resources folder. This file will control the logging behavior, such as the format of logs, the endpoint of our Loki service, and others, for our Spring Boot application:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="LOKI" class="com.github.loki4j.logback.Loki4jAppender">
<http>
<url>http://localhost:3100/loki/api/v1/push</url>
</http>
<format>
<label>
<pattern>app=${name},host=${HOSTNAME},level=%level</pattern>
<readMarkers>true</readMarkers>
</label>
<message>
<pattern>
{
"level":"%level",
"class":"%logger{36}",
"thread":"%thread",
"message": "%message",
"requestId": "%X{X-Request-ID}"
}
</pattern>
</message>
</format>
</appender>
<root level="INFO">
<appender-ref ref="LOKI" />
</root>
</configuration>Once we finish setting up, let’s write a simple service that logs data at INFO level:
@Service
class DemoService{
private final Logger LOG = LoggerFactory.getLogger(DemoService.class);
public void log(){
LOG.info("DemoService.log invoked");
}
}Let’s conduct a live test by spinning up Grafana and Loki containers, and then executing the service method to push the logs to Loki. Afterward, we’ll query Loki using the HTTP API to confirm if the log was indeed pushed. For spinning up Grafana and Loki containers, please see the earlier section.
First, let’s execute the DemoService.log() method, which will call Logger.info(). This sends a message using the loki-logback-appender, which Loki will collect:
DemoService service = new DemoService();
service.log();Second, we’ll create a request for invoking the REST endpoint provided by the Loki HTTP API. This GET API accepts query parameters representing the query, start time, and end time. We’ll add those parameters as part of our request object:
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
String query = "{level=\"INFO\"} |= `DemoService.log invoked`";
// Get time in UTC
LocalDateTime currentDateTime = LocalDateTime.now(ZoneOffset.UTC);
String current_time_utc = currentDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd'T'HH:mm:ss'Z'"));
LocalDateTime tenMinsAgo = currentDateTime.minusMinutes(10);
String start_time_utc = tenMinsAgo.format(DateTimeFormatter.ofPattern("yyyy-MM-dd'T'HH:mm:ss'Z'"));
URI uri = UriComponentsBuilder.fromUriString(baseUrl)
.queryParam("query", query)
.queryParam("start", start_time_utc)
.queryParam("end", current_time_utc)
.build()
.toUri();Next, let’s use the request object to execute REST request:
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<String> response = restTemplate.exchange(uri, HttpMethod.GET, new HttpEntity<>(headers), String.class);Now we need to process the response and extract the log messages we’re interested in. We’ll use an ObjectMapper to read the JSON response and extract the log messages:
ObjectMapper objectMapper = new ObjectMapper();
List<String> messages = new ArrayList<>();
String responseBody = response.getBody();
JsonNode jsonNode = objectMapper.readTree(responseBody);
JsonNode result = jsonNode.get("data")
.get("result")
.get(0)
.get("values");
result.iterator()
.forEachRemaining(e -> {
Iterator<JsonNode> elements = e.elements();
elements.forEachRemaining(f -> messages.add(f.toString()));
});
Finally, let’s assert that the messages we receive in the response contain the message that was logged by the DemoService:
assertThat(messages).anyMatch(e -> e.contains(expected));Our service logs are pushed to the Loki service because of the configuration setup with the loki-logback-appender. We can visualize it by visiting http://localhost:3000 (where the Grafana service is deployed) in our browser.
To see logs that have been stored and indexed in Loki, we need to use Grafana. The Grafana datasource provides configurable connection parameters for Loki where we need to enter the Loki endpoint, authentication mechanism, and more.
First, let’s configure the Loki endpoint to which logs have been pushed:
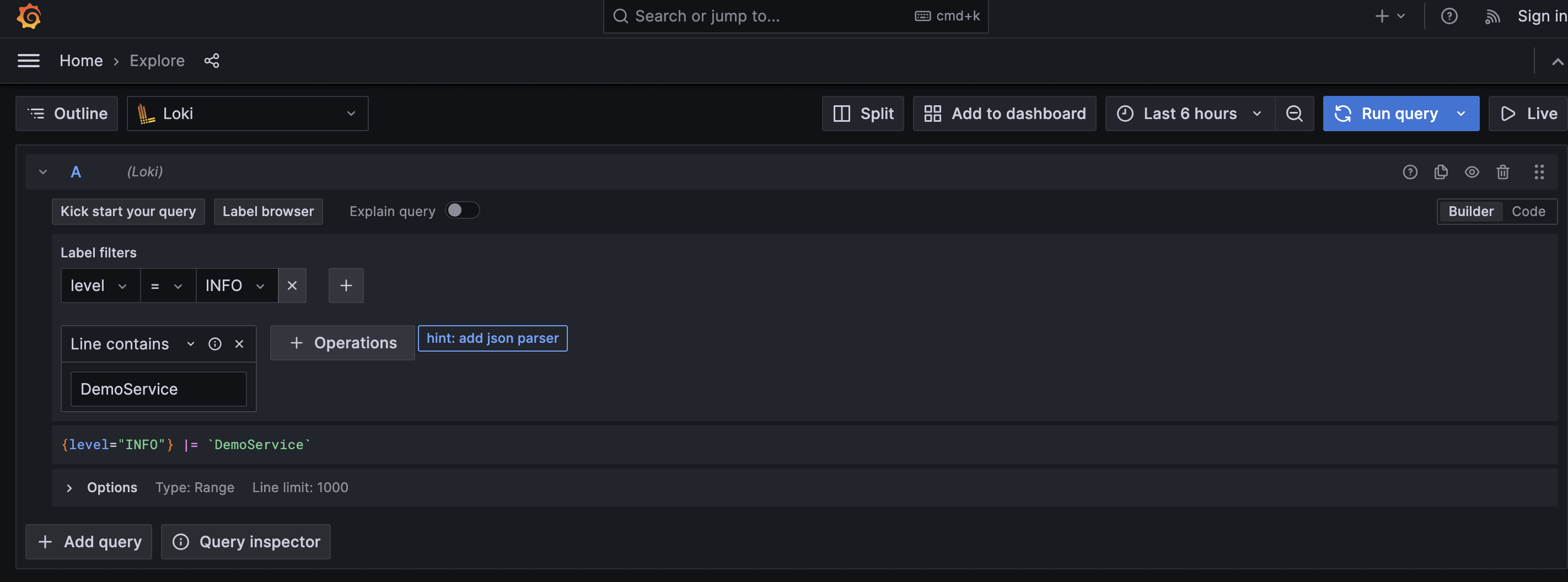
Once we’ve successfully configured the data source, let’s move to explore the data page for querying our logs:
We can write our query to fetch app logs into Grafana for visualization. In our demo service, we’re pushing INFO logs, so we need to add that to our filter and run the query:
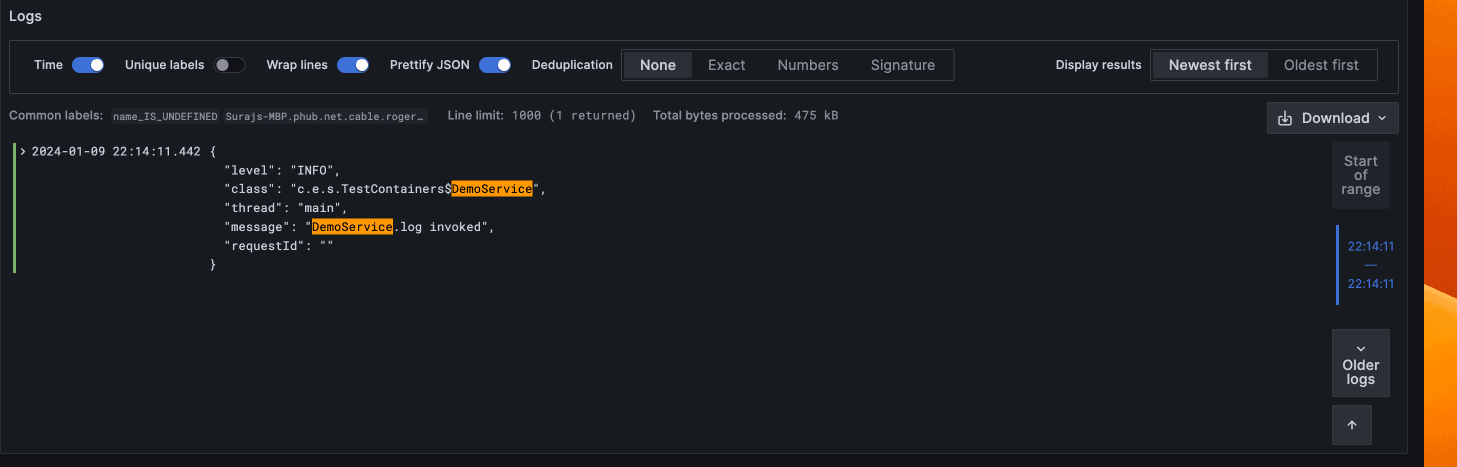
Once we run the query, we’ll see all the INFO logs that match our search:
In this article, we set up logging for a Spring Boot application with Grafana Loki. We also verified our setup with a unit test and visualization, using simple logic that logged INFO logs and setting a Loki data source in Grafana.
As always, the example code is available over on GitHub.
In this short tutorial, we’ll cast light on how to check if an element is present in a Set in Java.
First, we’ll kick things off by exploring solutions using core JDK. Then, we’ll elucidate how to achieve the same outcome using external libraries such as Apache Commons.
Java provides several convenient ways to check whether a Set contains a given element. Let’s explore these and see how to use them in practice.
As the name implies, this method checks if a specific Set contains the given element. It’s one of the easiest solutions that we can use to answer our central question:
@Test
void givenASet_whenUsingContainsMethod_thenCheck() {
assertThat(CITIES.contains("London")).isTrue();
assertThat(CITIES.contains("Madrid")).isFalse();
}Typically, the contains() method returns true if the given element is present in the Set, and false otherwise.
According to the documentation, the method returns true if and only:
object==null ? element==null : object.equals(element);This is why it’s important to implement the equals() method within the class to which the Set objects belong. That way, we can customize the equality logic to account for either all or some of the class fields.
In short, the contains() method offers the most concise and straightforward way to check if an element is present in a given Set compared to the other methods.
The Collections utility class provides another method, called disjoint(), that we can use to check if a Set contains a given element.
This method accepts two collections as parameters and returns true if they have no elements in common:
@Test
public void givenASet_whenUsingCollectionsDisjointMethod_thenCheck() {
boolean isPresent = !Collections.disjoint(CITIES, Collections.singleton("Paris"));
assertThat(isPresent).isTrue();
}Overall, we created an immutable Set containing only the given string “Paris”. Furthermore, we used the disjoint() method with the negation operator to check whether the two collections have elements in common.
The Stream API offers the anyMatch() method that we can use to verify if any element of a given collection matches the provided predicate.
So, let’s see it in action:
class CheckIfPresentInSetUnitTest {
private static final Set<String> CITIES = new HashSet<>();
@BeforeAll
static void setup() {
CITIES.add("Paris");
CITIES.add("London");
CITIES.add("Tokyo");
CITIES.add("Tamassint");
CITIES.add("New york");
}
@Test
void givenASet_whenUsingStreamAnyMatchMethod_thenCheck() {
boolean isPresent = CITIES.stream()
.anyMatch(city -> city.equals("London"));
assertThat(isPresent).isTrue();
}
}As we can see, we used the predicate city.equals(“London”) to check if there is any city in the stream that matches the condition of being equal to “London”.
Another solution would be using the filter() method. It returns a new stream consisting of elements that satisfy the provided condition.
In other words, it filters the stream based on the specified condition:
@Test
void givenASet_whenUsingStreamFilterMethod_thenCheck() {
long resultCount = CITIES.stream()
.filter(city -> city.equals("Tamassint"))
.count();
assertThat(resultCount).isPositive();
}As shown above, we filtred our Set to include only elements that are equal to the value “Tamassint”. Then, we used the terminal operation count() to return the number of the filtered elements.
The Apache Commons Collections library is another option to consider if we want to check if a given element is present in a Set. Let’s start by adding its dependency to the pom.xml file:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
CollectionUtils provides a set of utility methods to perform common operations on collections. Among these methods, we find containsAny(Collection<?> coll1, Collection<?> coll2). This method returns true if at least one element of the second collection is also contained in the first collection.
So, let’s see it in action:
@Test
void givenASet_whenUsingCollectionUtilsContainsAnyMethod_thenCheck() {
boolean isPresent = CollectionUtils.containsAny(CITIES, Collections.singleton("Paris"));
assertThat(isPresent).isTrue();
}Similarly, we created a singleton Set containing one element, “Paris”. Then, we used the containsAny() method to check if our collection CITIES contains the given value “Paris”.
Alternatively, we can use the SetUtils utility class to tackle our challenge. This class offers the intersection(Set<? extends E> a, Set<? extends E> b) method that returns a new Set containing elements that are both present in the specified two Sets:
@Test
void givenASet_whenUsingSetUtilsIntersectionMethod_thenCheck() {
Set<String> result = SetUtils.intersection(CITIES, Collections.singleton("Tamassint"));
assertThat(result).isNotEmpty();
}In a nutshell, the idea here is to verify whether the city “Tamassint” is present in CITIES by checking if the intersection between CITIES and the given singleton Set is not empty.
In this short article, we explored the nitty-gritty of how to check if a Set contains a given element in Java.
First, we saw how to do this using ready-to-use JDK methods. Then, we demonstrated how to accomplish the same goal using the Apache Commons Collections library.
As always, the code used in this article can be found over on GitHub.
Dealing with date and time values is a common task. Sometimes, we may need to convert a TemporalAccessor object to a LocalDate object to perform date-specific operations. Hence, this could be useful when parsing date-time strings or extracting date components from a date-time object.
In this tutorial, we’ll explore different approaches to achieve this conversion in Java.
One straightforward approach to convert a TemporalAccessor to a LocalDate is to use the LocalDate.from(TemporalAccessor temporal) method. Practically, this method extracts date components (year, month, and day) from the TemporalAccessor and constructs a LocalDate object. Let’s see an example:
String dateString = "2022-03-28";
TemporalAccessor temporalAccessor = DateTimeFormatter.ISO_LOCAL_DATE.parse(dateString);@Test
public void givenTemporalAccessor_whenUsingLocalDateFrom_thenConvertToLocalDate() {
LocalDate convertedDate = LocalDate.from(temporalAccessor);
assertEquals(LocalDate.of(2022, 3, 28), convertedDate);
}In this code snippet, we initialize a String variable dateString with the value (2022-03-28), representing a date in the (ISO 8601) format. In addition, we use the DateTimeFormatter.ISO_LOCAL_DATE.parse() method to parse this string into a TemporalAccessor object temporalAccessor.
Subsequently, we employ the LocalDate.from(temporalAccessor) method to convert temporalAccessor into a LocalDate object convertedDate, effectively extracting and constructing the date components.
Finally, through the assertion assertEquals(LocalDate.of(2022, 3, 28), convertedDate), we ensure that the conversion results in convertedDate matching the expected date.
Another approach to convert a TemporalAccessor to a LocalDate is by using TemporalQueries. We can define a custom TemporalQuery to extract the necessary date components and construct a LocalDate object. Here’s an example:
@Test
public void givenTemporalAccessor_whenUsingTemporalQueries_thenConvertToLocalDate() {
int year = temporalAccessor.query(TemporalQueries.localDate()).getYear();
int month = temporalAccessor.query(TemporalQueries.localDate()).getMonthValue();
int day = temporalAccessor.query(TemporalQueries.localDate()).getDayOfMonth();
LocalDate convertedDate = LocalDate.of(year, month, day);
assertEquals(LocalDate.of(2022, 3, 28), convertedDate);
}In this test method, we invoke the temporalAccessor.query(TemporalQueries.localDate()) method to obtain a LocalDate instance representing the date extracted from temporalAccessor.
We then retrieve the year, month, and day components from this LocalDate instance using getYear(), getMonthValue(), and getDayOfMonth() methods, respectively. Subsequently, we construct a LocalDate object convertedDate using the LocalDate.of() method with these extracted components.
In conclusion, converting a TemporalAccessor to a LocalDate in Java can be achieved using the LocalDate.from() or TemporalQueries. Besides, these methods provide flexible and efficient ways to perform the conversion, enabling seamless integration of date-time functionalities in Java applications.
As usual, the accompanying source code can be found over on GitHub.
Resources within a JAR file are typically accessed using a path relative to the root of the JAR file in Java. Furthermore, it’s essential to understand how these paths are structured to retrieve resources effectively.
In this tutorial, we’ll explore different methods to obtain the path to a resource within a Java JAR file.
The Class.getResource() method provides a straightforward way to obtain the URL of a resource within a JAR file. Let’s see how we can use this method:
@Test
public void givenFile_whenClassUsed_thenGetResourcePath() {
URL resourceUrl = GetPathToResourceUnitTest.class.getResource("/myFile.txt");
assertNotNull(resourceUrl);
}In this test, we call the getResource() method on the GetPathToResourceUnitTest.class, passing the path to the resource file “/myFile.txt” as an argument. Then, we assert that the obtained resourceUrl is not null, indicating that the resource file was successfully located.
Alternatively, we can use the ClassLoader.getResource() method to access resources within a JAR file. This method is useful when the resource path is not known at compile time:
@Test
public void givenFile_whenClassLoaderUsed_thenGetResourcePath() {
URL resourceUrl = GetPathToResourceUnitTest.class.getClassLoader().getResource("myFile.txt");
assertNotNull(resourceUrl);
}In this test, we’re employing the class loader GetPathToResourceUnitTest.class.getClassLoader() to fetch the resource file. Unlike the previous approach, this method doesn’t rely on the class’s package structure. Instead, it searches for the resource file at the root level of the classpath.
This means it can locate resources regardless of their location within the project structure, making it more flexible for accessing resources located outside the class’s package.
Starting from Java 7, we can use the Paths.get() method to obtain a Path object representing a resource within a JAR file. Here’s how:
@Test
public void givenFile_whenPathUsed_thenGetResourcePath() throws Exception {
Path resourcePath = Paths.get(Objects.requireNonNull(GetPathToResourceUnitTest.class.getResource("/myFile.txt")).toURI());
assertNotNull(resourcePath);
}Here, we first call the getResource() method to retrieve the URL of the resource file. Then, we convert this URL to a URI and pass it to Paths.get() to obtain a Path object representing the resource file’s location.
This approach is beneficial when we need to work with the resource file as a Path object. It enables more advanced file operations, such as reading or writing content to the file. Moreover, it offers a convenient way to interact with resources within the context of the Java NIO package.
In conclusion, accessing resources within a Java JAR file is crucial for many applications. Whether we prefer the simplicity of Class.getResource(), the flexibility of ClassLoader.getResource(), or the modern approach with Paths.get(), Java provides various methods to accomplish this task efficiently.
As usual, the accompanying source code can be found over on GitHub.
>> Code Before super() – JEP 447 [javaspecialists.eu]
A revolution is coming to Java! Soon, you will be able to add custom code before a super() call
>> Java users on macOS 14 running on Apple silicon systems should skip macOS 14.4 and update directly to macOS 14.4.1 [oracle.com]
The situation got stable – Java now works correctly on Apple Silicon.
>> JEP targeted to JDK 23: 466: Class-File API (Second Preview) [openjdk.org]
It’s good to see JDK provide low-level public APIs. No more need for Unsafe!
Webinars and presentations:
Time to upgrade:
>> The xz Backdoor Should Not Happen Again [techblog.bozho.net]
This shouldn’t happen again, but if the approach towards open source doesn’t change, it probably will.
>> Fixing duplicate API requests [frankel.ch]
Distributed systems are fun until you realize that you always need to be ready to handle duplicate requests.
Also worth reading:
Let’s dig into the Azure Spring Apps platform, built by Microsoft in collaboration with VMware:
>> Learn more and deploy your first Spring Boot app to Azure Spring Apps [microsoft.com]
In this tutorial, we’ll discuss Java’s JEP 418, which establishes a new Service Provider Interface (SPI) for Internet host and address resolution.
Any device connected to a computer network is assigned a numeric value or an IP (Internet Protocol) Address. IP addresses help identify the device on a network uniquely, and they also help in routing packets to and from the devices.
They are typically of two types. IPv4 is the fourth generation of the IP standard and is a 32-bit address. Due to the rapid growth of the Internet, a newer v6 of the IP standard has also been published, which is much larger and contains hexadecimal characters.
Additionally, there is another relevant type of address. Network devices, such as an Ethernet port or a Network Interface Card (NIC), have the MAC (Media Access Control) address. These are globally distributed, and all network interface devices can be uniquely identified with MAC addresses.
Internet Address Resolution broadly refers to converting a higher-level network address, such as a domain (e.g., baeldung) or a URL (https://www.baeldung.com), to a lower-level network address, such as an IP address or a MAC address.
Java provides multiple ways to resolve internet addresses today using the java.net.InetAddress API. The API internally uses the operating system’s native resolver for DNS lookup.
The OS native address resolution, which the InetAddress API currently uses, involves multiple steps. A system-level DNS cache is involved, where commonly queried DNS mappings are stored. If a cache miss occurs in the local DNS cache, the system resolver configuration provides information about a DNS server to perform subsequent lookups.
The OS then queries the configured DNS server obtained in the previous step for the information. This step might happen a couple of more times recursively.
If a match and lookup is successful, the DNS address is cached at all the servers and returned to the original client. However, if there is no match, an iterative lookup process is triggered to a Root Server, providing information about the Authoritative Nave Servers (ANS). These Authoritative Name Servers (ANS) store information about Top Level Domains (TLD) such as the .org, .com, etc.
These steps ultimately match the domain to an Internet address if it is valid or returns failure to the client.
The InetAddress API provides numerous methods for performing DNS query and resolution. These APIs are available as part of the java.net package.
The getAllByName() API tries to map a hostname to a set of IP addresses:
InetAddress[] inetAddresses = InetAddress.getAllByName(host);
Assert.assertTrue(Arrays.stream(inetAddresses).map(InetAddress::getHostAddress).toArray(String[]::new) > 1);This is also termed forward lookup.
The getByName() API is similar to the previous forward lookup API except that it only maps the host to the first matching IP Address:
InetAddress inetAddress = InetAddress.getByName("www.google.com");
Assert.assertNotNull(inetAddress.getHostAddress()); // returns an IP Address
This is the most basic API to perform a reverse lookup, wherein it takes an IP address as its input and tries to return a host associated with it:
InetAddress inetAddress = InetAddress.getByAddress(ip);
Assert.assertNotNull(inetAddress.getHostName()); // returns a host (eg. google.com)These APIs perform a similar reverse lookup and try to return the Fully Qualified Domain Name(FQDN) associated with it:
InetAddress inetAddress = InetAddress.getByAddress(ip);
Assert.assertNotNull(inetAddress.getCanonicalHostName()); // returns a FQDN
Assert.assertNotNull(inetAddress.getHostName());The Service Provider Interface (SPI) pattern is an important design pattern used in software development. The purpose of this pattern is to allow for pluggable components and implementations for a specific service.
It allows developers to extend the capabilities of a system without modifying any of the core expectations of the service and use any of the implementations without being tied down to a single one.
Following the SPI design pattern, this JEP proposes a way to substitute the default system resolver with a custom one. The SPI is available from Java 18 onwards. A service locator is necessary to locate the provider to use. If the service locator fails to identify any provider service, it returns to the default implementation.
As with any SPI implementation, there are four main components:
The changes put forth through this SPI are available in the java.net.spi package, and the following classes are newly added:
In this section, we’ll try to write a custom resolver implementation for InetAddressResolver to substitute for the system default resolver. Before we write our custom resolver, we can define a small utility class that will load the registry of address mappings from a file onto memory (or cache).
Based on the registry entries, our custom address resolver will be able to resolve address hosts to IPs and vice versa.
First, we define our class CustomAddressResolverImpl by extending from the abstract class InetAddressResolverProvider. Doing this requires us to immediately provide implementations of two methods: get(Configuration configuration) and name().
We can use the name() to return the name of the current implementation class or any other relevant identifier:
@Override
public String name() {
return "CustomInternetAddressResolverImpl";
}Let’s now implement the get() method. The get() method returns an instance of the InetAddressResolver class, which we can define inline or separately. We’ll define it inline for simplicity.
An InetAddressResolver interface has two methods:
We can write any custom logic to map a host to its IP Address (in the form of InetAddress) and vice versa. In this example, we’ll let our Registry functionality take care of the same:
@Override
public InetAddressResolver get(Configuration configuration) {
LOGGER.info("Using Custom Address Resolver :: " + this.name());
LOGGER.info("Registry initialised");
return new InetAddressResolver() {
@Override
public Stream<InetAddress> lookupByName(String host, LookupPolicy lookupPolicy) throws UnknownHostException {
return registry.getAddressesfromHost(host);
}
@Override
public String lookupByAddress(byte[] addr) throws UnknownHostException {
return registry.getHostFromAddress(addr);
}
};
}For this article, we’ll use a HashMap to store a list of IP Addresses and hostnames in memory. We can load the list from a file on the system as well.
The Map is of type Map<String, List<byte[]>> where the host names are stored as the keys and the IP address are stored as a List of byte[]. This data structure allows multiple IPs to be mapped against a single host. We can perform forward and backward lookups using this Map.
Forward Lookup, in this case, is when we pass the hostname as a parameter and expect to resolve it against its IP Address, for example, when we type www.baeldung.com:
public Stream<InetAddress> getAddressesfromHost(String host) throws UnknownHostException {
LOGGER.info("Performing Forward Lookup for HOST : " + host);
if (!registry.containsKey(host)) {
throw new UnknownHostException("Missing Host information in Resolver");
}
return registry.get(host)
.stream()
.map(add -> constructInetAddress(host, add))
.filter(Objects::nonNull);
}We should note that the response is a Stream of InetAddress to accommodate multiple IPs.
An example of reverse lookup is when we want to know the hostname associated with an IP Address:
public String getHostFromAddress(byte[] arr) throws UnknownHostException {
LOGGER.info("Performing Reverse Lookup for Address : " + Arrays.toString(arr));
for (Map.Entry<String, List<byte[]>> entry : registry.entrySet()) {
if (entry.getValue()
.stream()
.anyMatch(ba -> Arrays.equals(ba, arr))) {
return entry.getKey();
}
}
throw new UnknownHostException("Address Not Found");
}Finally, the ServiceLoader module loads our custom implementation for InetAddress resolution.
To discover our Service Provider, we create a configuration under the resources/META-INF/services hierarchy named java.net.spi.InetAddressResolverProvider. The configuration file should maintain our provider’s fully qualified path as com.baeldung.inetspi.providers.CustomAddressResolverImpl.java.
This tells the JVM to load the corresponding implementation of the provider following the SPI pattern.
We have a few workarounds in case we don’t wish to add a custom implementation for address resolution:
In this article, we examined how Internet Address Resolution works in Java using the InetAddress API. We also examined JEP 418 for the Service Provider Interface (SPI) for Internet host and address resolution. We implemented a custom Provider for Internet Address resolution and discussed some alternatives.
As always, the code for the examples is available over on GitHub.
Logging is essential in software development as it aids in recording every footprint of an application. It helps with tracking the activities and state of an application. Essentially, it’s useful for debugging purposes.
Apache Camel provides a component, interface, and interceptor to log messages and exchanges. It simplifies logging by providing a layer of abstraction over various logging frameworks.
In this tutorial, we’ll look at four ways to log messages and exchanges in a Camel application.
Apache Camel 2.2 provides a lightweight log() DSL to log human-readable messages from a route. Its major use case is to output a message to the log console quickly. Also, we can use it with Camel Simple expression language to further log details from a route to the log console.
Let’s see an example that copies a file from one folder to another:
class FileCopierCamelRoute extends RouteBuilder {
void configure() {
from("file:data/inbox?noop=true")
.log("We got an incoming file ${file:name} containing: ${body}")
.to("file:data/outbox")
.log("Successfully transfer file: ${file:name}");
}
}In the code above, we configure a RouteBuilder that transfers files from the inbox to the outbox folder. First, we define the location of the incoming file. Next, we use the log() DSL to output a human-readable log on the incoming file and its content. Also, we use Simple expression language to get the file name and the content of the file as part of the log message.
Here’s the log output:
14:39:23.389 [Camel (camel-1) thread #1 - file://data/inbox] INFO route1 - We got an incoming file welcome.txt containing: Welcome to Baeldung
14:39:23.423 [Camel (camel-1) thread #1 - file://data/inbox] INFO route1 - Successlly transfer file: welcome.txtThe log() DSL is lightweight compared to the Log component and Tracer interceptor.
Furthermore, we can explicitly specify the log level and name:
// ...
.log(LoggingLevel.DEBUG,"Output Process","The Process ${id}")
// ...Here, we indicate the log level and name before passing the log message. We also have the WARN, TRACE, and OFF options as log levels. When the debug level is not specified, the log() DSL uses INFO.
The Processor is an important interface in Apache Camel that gives access to exchange for further manipulation. It gives us the flexibility to alter the exchange body. However, we can also use it to output human-readable log messages.
Primarily, the Processor is not a logging tool. Therefore, we need to create a Logger instance to use it with. Apache Camel uses the SLF4J library by default. Let’s create a Logger instance:
private static final Logger LOGGER = LoggerFactory.getLogger(FileCopierCamelRoute.class);Next, let’s see an example that passes a message to a bean for further manipulation:
void configure() {
from("file:data/inbox?noop=true")
.to("log:com.baeldung.apachecamellogging?level=INFO")
.process(process -> {
LOGGER.info("We are passing the message to a FileProcesor bean to capitalize the message body");
})
.bean(FileProcessor.class)
.to("file:data/outbox")
}Here, we pass the incoming message to the FileProcessor bean to convert the file content to uppercase. However, we log a piece of information before the message is passed to the bean for process by creating an instance of the Processor.
Finally, let’s see the log output:
14:50:47.048 [Camel (camel-1) thread #1 - file://data/inbox] INFO c.b.a.FileCopierCamelRoute - We are passing the message to a FileProcesor to Capitalize the message bodyFrom the output above, the custom log message is output to the console.
Apache Camel provides a Log component that helps log Camel Message to a console output. To use the Log component, we can route messages to it:
void configure() {
from("file:data/inbox?noop=true")
.to("log:com.baeldung.apachecamellogging?level=INFO")
.bean(FileProcessor.class)
.to("file:data/outbox")
.to("log:com.baeldung.apachecamellogging")
}Here, we use the Log component in two places. First, we log the message body at the INFO logging level by using the level option. Also, we log the message body after manipulating the file but we didn’t specify the logging level.
Notably, in a case where the logging level is not specified, the Log component uses the INFO level as the default.
Here’s the log output:
09:36:32.432 [Camel (camel-1) thread #1 - file://data/inbox] INFO com.baeldung.apachecamellogging - Exchange[ExchangePattern: InOnly, BodyType: org.apache.camel.component.file.GenericFile, Body: [Body is file based: GenericFile[welcome.txt]]]
09:36:32.454 [Camel (camel-1) thread #1 - file://data/inbox] INFO com.baeldung.apachecamellogging - Exchange[ExchangePattern: InOnly, BodyType: String, Body: WELCOME TO BAELDUNG]Also, we can make the output less verbose by adding showBodyType and maxChars option:
.to("log:com.baeldung.apachecamellogging?showBodyType=false&maxChars=20")In the code above, we ignore the message body time and streamline the body characters to 20.
Tracer is part of Apache Camel architecture that helps log how messages are routed during runtime. It keeps track of exchange snapshots during the process of routing. It can intercept message movement from one node to another.
To use a Tracer, we have to enable it in the route configuration method:
getContext().setTracing(true);This enables the Tracer interceptor to intercept all exchange processes and log them to the log console.
Let’s see an example code that enables Tracer to keep track of the exchange process:
void configure() {
getContext().setTracing(true);
from("file:data/json?noop=true")
.unmarshal().json(JsonLibrary.Jackson)
.bean(FileProcessor.class, "transform")
.marshal().json(JsonLibrary.Jackson)
.to("file:data/output");
}In the code above, we copy a JSON file from a source and convert it to a data structure that Camel can manipulate. We pass the content to a bean to alter the file content. Next, we convert the message to JSON and send it to the intended destination.
Here’s the log from the Tracer interceptor:
// ...
09:23:10.767 [Camel (camel-1) thread #1 - file://data/json] INFO FileCopierTracerCamelRoute:14 - *--> [route1 ] [from[file:data/json?noop=true] ]
09:23:10.768 [Camel (camel-1) thread #1 - file://data/json] INFO FileCopierTracerCamelRoute:14 - [route1 ] [log:input?level=INFO ]
// ...In the output above, the Tracer records every process and exchanges that occur from the producer down to the consumer. This can be useful for debugging.
Notably, the log output is verbose, but for simplicity, we show the essential log message.
In this article, we learned four ways to log in to Apache Camel. Additionally, we saw examples that use the log() DSL, Tracer, Processor, and Log component to log messages to the console. The log() DSL and the Processor interface are ideal for human-readable logs, while the Log component and Tracer are suitable for more complex logs used in debugging.
As always, the source code for the examples is available over on GitHub.
In this tutorial, we’ll learn how to map one enum type to another using MapStruct, mapping enums to built-in Java types such as int and String, and vice versa.
Let’s add the below dependency to our Maven pom.xml:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>1.6.0.Beta1</version>
</dependency>The latest stable release of MapStruct is available from the Maven Central Repository.
In this section, we’ll learn to perform various mappings.
Now, let us see a few real-world scenarios.
In REST API response mapping, MapStruct converts external API status codes into our application’s internal status enums.
For data transformation in microservices, MapStruct facilitates smooth data exchange between services by mapping similar enums.
Integration with third-party libraries often involves dealing with third-party enums. MapStruct simplifies this by converting them into our application’s enums.
To configure the mapping of source constant values to target constant values, we use the @ValueMapping MapStruct annotation. It maps based on names. However, we can also map a constant from the source enum to a constant with a different name in the target enum type. For instance, we can map a source enum “Go” to the target enum “Move“.
It’s also possible to map several constants from the source enum to the same constant in the target type.
TrafficSignal enum represents a traffic signal. The external service we interact with uses the RoadSign enum. The mapper would convert the enums to each other.
Let’s define the traffic signal enum:
public enum TrafficSignal {
Off, Stop, Go
}Let’s define the road sign enum:
public enum RoadSign {
Off, Halt, Move
}Let’s implement the @Mapper:
@Mapper
public interface TrafficSignalMapper {
TrafficSignalMapper INSTANCE = Mappers.getMapper(TrafficSignalMapper.class);
@ValueMapping(target = "Off", source = "Off")
@ValueMapping(target = "Go", source = "Move")
@ValueMapping(target = "Stop", source = "Halt")
TrafficSignal toTrafficSignal(RoadSign source);
}@Mapper defines a MapStruct mapper called TrafficSignalMapper to convert enums to TrafficSignal. Its methods represent a mapping operation.
The @ValueMapping annotations within the interface specify explicit mappings between enum values. For example, @ValueMapping(target = “Go”, source = “Move”) maps the Move enum to Go enum in TrafficSignal, and so on.
We need to make sure to map all enum values from source to target for complete coverage and prevent unexpected behavior.
Here’s the test for it:
@Test
void whenRoadSignIsMapped_thenGetTrafficSignal() {
RoadSign source = RoadSign.Move;
TrafficSignal target = TrafficSignalMapper.INSTANCE.toTrafficSignal(source);
assertEquals(TrafficSignal.Go, target);
}It verifies the mapping of RoadSign.Move to TrafficSignal.Go.
We must test mapping methods thoroughly with unit tests to ensure accurate behavior and detect potential issues.
Let’s convert text literal values into enum values.
Our application collects user input as strings. We map these strings to enum values to represent different commands or options. For example, we map “add” to Operation.ADD, “subtract” to Operation.SUBTRACT, etc.
We specify settings as strings in the application configuration. We map these strings to enum values to ensure type-safe configuration. For instance, we map “EXEC” to Mode.EXEC, “TEST” to Mode.TEST, etc.
We map external API strings to enum values in our application. For instance, we map “active” to Status.ACTIVE, “inactive” to Status.INACTIVE, etc.
Let’s use @ValueMapping to map each signal:
@ValueMapping(target = "Off", source = "Off")
@ValueMapping(target = "Go", source = "Move")
@ValueMapping(target = "Stop", source = "Halt")
TrafficSignal stringToTrafficSignal(String source);Here’s the test for it:
@Test
void whenStringIsMapped_thenGetTrafficSignal() {
String source = RoadSign.Move.name();
TrafficSignal target = TrafficSignalMapper.INSTANCE.stringToTrafficSignal(source);
assertEquals(TrafficSignal.Go, target);
}It verifies “Move” maps to TrafficSignal.Go.
Enum names may differ only by naming convention. It may follow a different case, prefix, or suffix convention. For example, a signal could be Go, go, GO, Go_Value, Value_Go.
We apply a suffix to the source enum to get the target enum. For instance, Go becomes Go_Value:
public enum TrafficSignalSuffixed { Off_Value, Stop_Value, Go_Value }Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.SUFFIX_TRANSFORMATION, configuration = "_Value")
TrafficSignalSuffixed applySuffix(TrafficSignal source);@EnumMapping defines custom mappings for enum types. nameTransformationStrategy specifies the transformation strategy to apply to the enum constant name before mapping. We pass the appropriate controlling value in the configuration.
Here is the test to check the suffix:
@ParameterizedTest
@CsvSource({"Off,Off_Value", "Go,Go_Value"})
void whenTrafficSignalIsMappedWithSuffix_thenGetTrafficSignalSuffixed(TrafficSignal source, TrafficSignalSuffixed expected) {
TrafficSignalSuffixed result = TrafficSignalMapper.INSTANCE.applySuffix(source);
assertEquals(expected, result);
}We can also apply a prefix to the source enum to get the target enum. For instance, Go becomes Value_Go:
public enum TrafficSignalPrefixed { Value_Off, Value_Stop, Value_Go }Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.PREFIX_TRANSFORMATION, configuration = "Value_")
TrafficSignalPrefixed applyPrefix(TrafficSignal source);PREFIX_TRANSFORMATION tells MapStruct to apply the prefix “Value_” to the source enum.
Let’s check the prefix mapping:
@ParameterizedTest
@CsvSource({"Off,Value_Off", "Go,Value_Go"})
void whenTrafficSignalIsMappedWithPrefix_thenGetTrafficSignalPrefixed(TrafficSignal source, TrafficSignalPrefixed expected) {
TrafficSignalPrefixed result = TrafficSignalMapper.INSTANCE.applyPrefix(source);
assertEquals(expected, result);
}We remove suffixes from the source enum to get the target enum. For instance, Go_Value becomes Go.
Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.STRIP_SUFFIX_TRANSFORMATION, configuration = "_Value")
TrafficSignal stripSuffix(TrafficSignalSuffixed source);STRIP_SUFFIX_TRANSFORMATION tells MapStruct to remove the suffix “_Value” from the source enum.
Here’s the test to check the stripped suffix:
@ParameterizedTest
@CsvSource({"Off_Value,Off", "Go_Value,Go"})
void whenTrafficSignalSuffixedMappedWithStripped_thenGetTrafficSignal(TrafficSignalSuffixed source, TrafficSignal expected) {
TrafficSignal result = TrafficSignalMapper.INSTANCE.stripSuffix(source);
assertEquals(expected, result);
}We remove a prefix from the source enum to get the target enum. For instance, Value_Go becomes Go.
Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.STRIP_PREFIX_TRANSFORMATION, configuration = "Value_")
TrafficSignal stripPrefix(TrafficSignalPrefixed source);STRIP_PREFIX_TRANSFORMATION tells MapStruct to remove the prefix “Value_” from the source enum.
And here’s the test to check the stripped prefix:
@ParameterizedTest
@CsvSource({"Value_Off,Off", "Value_Stop,Stop"})
void whenTrafficSignalPrefixedMappedWithStripped_thenGetTrafficSignal(TrafficSignalPrefixed source, TrafficSignal expected) {
TrafficSignal result = TrafficSignalMapper.INSTANCE.stripPrefix(source);
assertEquals(expected, result);
}We apply lowercase to the source enum to get the target enum. For instance, Go becomes go:
public enum TrafficSignalLowercase { off, stop, go }Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.CASE_TRANSFORMATION, configuration = "lower")
TrafficSignalLowercase applyLowercase(TrafficSignal source);CASE_TRANSFORMATION and lower configuration tells MapStruct to apply lowercase to source enum.
Here is the test method to check for lowercase mapping:
@ParameterizedTest
@CsvSource({"Off,off", "Go,go"})
void whenTrafficSignalMappedWithLower_thenGetTrafficSignalLowercase(TrafficSignal source, TrafficSignalLowercase expected) {
TrafficSignalLowercase result = TrafficSignalMapper.INSTANCE.applyLowercase(source);
assertEquals(expected, result);
}We apply uppercase to the source enum to get the target enum. For instance, Mon becomes MON:
public enum <em>TrafficSignalUppercase</em> { OFF, STOP, GO }Let’s define the mapping:
@EnumMapping(nameTransformationStrategy = MappingConstants.CASE_TRANSFORMATION, configuration = "upper")
TrafficSignalUppercase applyUppercase(TrafficSignal source);CASE_TRANSFORMATION and upper configuration tell MapStruct to apply uppercase to the source enum.
Here is the test to verify uppercase mapping:
@ParameterizedTest
@CsvSource({"Off,OFF", "Go,GO"})
void whenTrafficSignalMappedWithUpper_thenGetTrafficSignalUppercase(TrafficSignal source, TrafficSignalUppercase expected) {
TrafficSignalUppercase result = TrafficSignalMapper.INSTANCE.applyUppercase(source);
assertEquals(expected, result);
}We apply the title case to the source enum to get the target enum. For instance, go becomes Go:
@EnumMapping(nameTransformationStrategy = MappingConstants.CASE_TRANSFORMATION, configuration = "captial")
TrafficSignal lowercaseToCapital(TrafficSignalLowercase source);CASE_TRANSFORMATION and capital configuration tell MapStruct to capitalize the source enum.
Here is the test to check the capital case:
@ParameterizedTest
@CsvSource({"OFF_VALUE,Off_Value", "GO_VALUE,Go_Value"})
void whenTrafficSignalUnderscoreMappedWithCapital_thenGetStringCapital(TrafficSignalUnderscore source, String expected) {
String result = TrafficSignalMapper.INSTANCE.underscoreToCapital(source);
assertEquals(expected, result);
}There would be scenarios when we map the enum back to other types. Let’s look at them in this section.
Let’s define the mapping:
@ValueMapping(target = "Off", source = "Off")
@ValueMapping(target = "Go", source = "Go")
@ValueMapping(target = "Stop", source = "Stop")
String trafficSignalToString(TrafficSignal source);The @ValueMapping maps enum values to strings. For instance, we map the Go enum to the “Go” string value, and so on.
Here is the test to check the string mapping:
@Test
void whenTrafficSignalIsMapped_thenGetString() {
TrafficSignal source = TrafficSignal.Go;
String targetTrafficSignalStr = TrafficSignalMapper.INSTANCE.trafficSignalToString(source);
assertEquals("Go", targetTrafficSignalStr);
}It verifies if the mapping maps enum TrafficSignal.Go to a string literal “Go”.
Mapping directly to an integer can cause ambiguity due to multiple constructors. We add a default mapper method that converts the enum to an integer. In addition, we can also define a class with an integer property to address this issue.
Let’s define a wrapper class:
public class TrafficSignalNumber
{
private Integer number;
// getters and setters
}Let’s map the enum to an integer using the default method:
@Mapping(target = "number", source = ".")
TrafficSignalNumber trafficSignalToTrafficSignalNumber(TrafficSignal source);
default Integer convertTrafficSignalToInteger(TrafficSignal source) {
Integer result = null;
switch (source) {
case Off:
result = 0;
break;
case Stop:
result = 1;
break;
case Go:
result = 2;
break;
}
return result;
}Here is the test to check the integer result:
@ParameterizedTest
@CsvSource({"Off,0", "Stop,1"})
void whenTrafficSignalIsMapped_thenGetInt(TrafficSignal source, int expected) {
Integer targetTrafficSignalInt = TrafficSignalMapper.INSTANCE.convertTrafficSignalToInteger(source);
TrafficSignalNumber targetTrafficSignalNumber = TrafficSignalMapper.INSTANCE.trafficSignalToTrafficSignalNumber(source);
assertEquals(expected, targetTrafficSignalInt.intValue());
assertEquals(expected, targetTrafficSignalNumber.getNumber().intValue());
}We need to handle unmatched enum values by setting defaults, handling nulls, or throwing exceptions based on the business logic.
MapStruct raises an error if a source enum doesn’t have a corresponding one in the target type. In addition, MapStruct can also map remaining or unmapped values to a default.
We have two options applicable to source only: ANY_REMAINING and ANY_UNMAPPED. However, we need to use only one of these options at a time.
The ANY_REMAINING option maps any remaining source values with the same name to the default value.
Let’s define a simple traffic signal:
public enum SimpleTrafficSignal { Off, On }Notably, it has less number of values than TrafficSignal. However, MapStruct needs us to map all enum values.
Let’s define the mapping:
@ValueMapping(target = "Off", source = "Off")
@ValueMapping(target = "On", source = "Go")
@ValueMapping(target = "Off", source = "Stop")
SimpleTrafficSignal toSimpleTrafficSignal(TrafficSignal source);We explicitly map to Off. It would be inconvenient to map these if there are many such values. We may miss mapping a few values. That is where ANY_REMAINING helps.
Let’s define the mapping:
@ValueMapping(target = "On", source = "Go")
@ValueMapping(target = "Off", source = MappingConstants.ANY_REMAINING)
SimpleTrafficSignal toSimpleTrafficSignalWithRemaining(TrafficSignal source);Here, we map Go to On. And then using MappingConstants.ANY_REMAINING, we map any remaining value to Off. Isn’t that a cleaner implementation now?
Here is the test to check the remaining mapping:
@ParameterizedTest
@CsvSource({"Off,Off", "Go,On", "Stop,Off"})
void whenTrafficSignalIsMappedWithRemaining_thenGetTrafficSignal(TrafficSignal source, SimpleTrafficSignal expected) {
SimpleTrafficSignal targetTrafficSignal = TrafficSignalMapper.INSTANCE.toSimpleTrafficSignalWithRemaining(source);
assertEquals(expected, targetTrafficSignal);
}It verifies that all other values are mapped to Off except for the value Go.
Instead of remaining values, we can instruct MapStruct to map the unmapped values irrespective of the name.
Let’s define the mapping:
@ValueMapping(target = "On", source = "Go")
@ValueMapping(target = "Off", source = MappingConstants.ANY_UNMAPPED)
SimpleTrafficSignal toSimpleTrafficSignalWithUnmapped(TrafficSignal source);Here is the test to check unmapped mapping:
@ParameterizedTest
@CsvSource({"Off,Off", "Go,On", "Stop,Off"})
void whenTrafficSignalIsMappedWithUnmapped_thenGetTrafficSignal(TrafficSignal source, SimpleTrafficSignal expected) {
SimpleTrafficSignal target = TrafficSignalMapper.INSTANCE.toSimpleTrafficSignalWithUnmapped(source);
assertEquals(expected, target);
}It verifies that all other values are mapped to Off except for the value Go.
MapStruct can handle null sources and null targets using the NULL keyword.
Let’s suppose we need to map null input to Off, Go to On, and any other unmapped value to null.
Let’s define the mapping:
@ValueMapping(target = "Off", source = MappingConstants.NULL)
@ValueMapping(target = "On", source = "Go")
@ValueMapping(target = MappingConstants.NULL, source = MappingConstants.ANY_UNMAPPED)
SimpleTrafficSignal toSimpleTrafficSignalWithNullHandling(TrafficSignal source);
We use MappingConstants.NULL to set the null value to the target. It’s also used to indicate null input.
Here is the test to check null mapping:
@CsvSource({",Off", "Go,On", "Stop,"})
void whenTrafficSignalIsMappedWithNull_thenGetTrafficSignal(TrafficSignal source, SimpleTrafficSignal expected) {
SimpleTrafficSignal targetTrafficSignal = TrafficSignalMapper.INSTANCE.toSimpleTrafficSignalWithNullHandling(source);
assertEquals(expected, targetTrafficSignal);
}Let’s consider a scenario where we raise an exception instead of mapping it to a default or null.
Let’s define the mapping:
@ValueMapping(target = "On", source = "Go")
@ValueMapping(target = MappingConstants.THROW_EXCEPTION, source = MappingConstants.ANY_UNMAPPED)
@ValueMapping(target = MappingConstants.THROW_EXCEPTION, source = MappingConstants.NULL)
SimpleTrafficSignal toSimpleTrafficSignalWithExceptionHandling(TrafficSignal source);We use MappingConstants.THROW_EXCEPTION to raise an exception for any unmapped input.
Here is the test to check the exception thrown:
@ParameterizedTest
@CsvSource({",", "Go,On", "Stop,"})
void whenTrafficSignalIsMappedWithException_thenGetTrafficSignal(TrafficSignal source, SimpleTrafficSignal expected) {
if (source == TrafficSignal.Go) {
SimpleTrafficSignal targetTrafficSignal = TrafficSignalMapper.INSTANCE.toSimpleTrafficSignalWithExceptionHandling(source);
assertEquals(expected, targetTrafficSignal);
} else {
Exception exception = assertThrows(IllegalArgumentException.class, () -> {
TrafficSignalMapper.INSTANCE.toSimpleTrafficSignalWithExceptionHandling(source);
});
assertEquals("Unexpected enum constant: " + source, exception.getMessage());
}
}It verifies that the result is an exception for Stop, or else it’s an expected signal.
In this article, we learned to map between enum types and other data types like strings or integers using MapStruct @ValueMapping. Whether mapping one enum to another or gracefully handling unknown enum values, @ValueMapping offers flexibility and strength in mapping tasks. By adhering to best practices and taking care of null inputs and unmatched values, we improve code clarity and maintainability.
As always, the source code for the examples is available over on GitHub.
In this tutorial, we’ll dive into the topic of testing Spring applications which utilize scheduled tasks. Their extensive usage might cause a headache when we try to develop tests, especially integration ones. We’ll talk about possible options to make sure that they’re as stable as they can be.
Let’s start with a short explanation of the example we’ll be using throughout the article. Let’s imagine a system that allows the representative of the company to send notifications to their clients. Some of them are time-sensitive and should be delivered immediately, but some should wait until the next business day. Therefore, we need a mechanism that will periodically attempt to send them:
public class DelayedNotificationScheduler {
private NotificationService notificationService;
@Scheduled(fixedDelayString = "${notification.send.out.delay}", initialDelayString = "${notification.send.out.initial.delay}")
public void attemptSendingOutDelayedNotifications() {
notificationService.sendOutDelayedNotifications();
}
}We can spot the @Scheduled annotation on the attemptSendingOutDelayedNotifications() method. The method will be invoked for the first time when the time configured by the initialDelayString passes. Once the execution ends, Spring invokes it again after the time configured by the fixedDelayString parameter. The method itself delegates the actual logic to NotificationService.
Of course, we also need to turn on the scheduling. We do this by applying the @EnableScheduling annotation on the class annotated with @Configuration. Although crucial, we won’t dive into it here, because it’s tightly connected to the main topic. Later on, we’ll see a couple of ways how we can do it in a way that doesn’t negatively interfere with tests.
First, let’s write a basic integration test for our notification application:
@SpringBootTest(
classes = { ApplicationConfig.class, SchedulerTestConfiguration.class },
properties = {
"notification.send.out.delay: 10",
"notification.send.out.initial.delay: 0"
}
)
public class DelayedNotificationSchedulerIntegrationTest {
@Autowired
private Clock testClock;
@Autowired
private NotificationRepository repository;
@Autowired
private DelayedNotificationScheduler scheduler;
@Test
public void whenTimeIsOverNotificationSendOutTime_thenItShouldBeSent() {
ZonedDateTime fiveMinutesAgo = ZonedDateTime.now(testClock).minusMinutes(5);
Notification notification = new Notification(fiveMinutesAgo);
repository.save(notification);
scheduler.attemptSendingOutDelayedNotifications();
Notification processedNotification = repository.findById(notification.getId());
assertTrue(processedNotification.isSentOut());
}
}
@TestConfiguration
class SchedulerTestConfiguration {
@Bean
@Primary
public Clock testClock() {
return Clock.fixed(Instant.parse("2024-03-10T10:15:30.00Z"), ZoneId.systemDefault());
}
}It’s important to mention that the @EnableScheduling annotation was simply applied to the ApplicationConfig class, which is also responsible for creating all additional beans we autowire in the test.
Let’s run this test and see the produced logs:
2024-03-13T00:17:38.637+01:00 INFO 4728 --- [pool-1-thread-1] c.b.d.DelayedNotificationScheduler : Scheduled notifications send out attempt
2024-03-13T00:17:38.637+01:00 INFO 4728 --- [pool-1-thread-1] c.b.d.NotificationService : Sending out delayed notifications
2024-03-13T00:17:38.644+01:00 INFO 4728 --- [ main] c.b.d.DelayedNotificationScheduler : Scheduled notifications send out attempt
2024-03-13T00:17:38.644+01:00 INFO 4728 --- [ main] c.b.d.NotificationService : Sending out delayed notifications
2024-03-13T00:17:38.647+01:00 INFO 4728 --- [pool-1-thread-1] c.b.d.DelayedNotificationScheduler : Scheduled notifications send out attempt
2024-03-13T00:17:38.647+01:00 INFO 4728 --- [pool-1-thread-1] c.b.d.NotificationService : Sending out delayed notifications
Analyzing the output, we can spot that the attemptSendingOutDelayedNotifications() method has been invoked more than once.
One invocation comes from the main thread, while the others from the pool-1-thread-1 one.
We can observe this behavior because the application initialized scheduled tasks during startup. They periodically invoke our scheduler in the threads belonging to the separate thread pool. That’s why we can see method calls coming from the pool-1-thread-1. On the other hand, the call coming from the main thread is one that we directly called in the integration test.
The test passed, but the action was invoked multiple times. It’s just a code smell here, but it may lead to flaky tests in less fortunate circumstances. Our tests should be as explicit and isolated as possible. Therefore, we should introduce the fix reassuring us that the only time when the scheduler is invoked is the time when we directly call it.
Let’s consider what we can do to make sure that during the test, only the code we’d like to execute is being executed. The approaches we’re going to go through are similar to the ones allowing us to conditionally enable scheduled jobs in Spring applications but are adjusted for usage in integration tests.
First, we can extract the part of the configuration enabling scheduling to another configuration class. Then, we can apply it conditionally based on the active profile. In our case, we’d like to disable scheduling when the integrationTest profile is active:
@Configuration
@EnableScheduling
@Profile("!integrationTest")
public class SchedulingConfig {
}On the integration test side, the only thing we need to do is to enable the mentioned profile:
@SpringBootTest(
classes = { ApplicationConfig.class, SchedulingConfig.class, SchedulerTestConfiguration.class },
properties = {
"notification.send.out.delay: 10",
"notification.send.out.initial.delay: 0"
}
)This setup allows us to make sure that during the execution of all tests defined in the DelayedNotificationSchedulerIntegrationTest, the scheduling is disabled and no code will be executed automatically as a scheduled task.
Another, but still similar approach, is to enable the scheduling for the application based on the property value. We can use the already extracted configuration class and apply it based on the different condition:
@Configuration
@EnableScheduling
@ConditionalOnProperty(value = "scheduling.enabled", havingValue = "true", matchIfMissing = true)
public class SchedulingConfig {
}Now, the scheduling is dependent on the value of the scheduling.enabled property. If we consciously set it to false, Spring won’t pick up the SchedulingConfig configuration class. Changes required on the integration test side are minimal:
@SpringBootTest(
classes = { ApplicationConfig.class, SchedulingConfig.class, SchedulerTestConfiguration.class },
properties = {
"notification.send.out.delay: 10",
"notification.send.out.initial.delay: 0",
"scheduling.enabled: false"
}
)The effect is identical to the one we achieved following the previous idea.
The last approach we can take is to carefully fine-tune the configuration of our scheduled tasks. We can set a very long initial delay time for them so that integration tests have a lot of time to be executed before Spring tries to execute any periodic actions:
@SpringBootTest(
classes = { ApplicationConfig.class, SchedulingConfig.class, SchedulerTestConfiguration.class },
properties = {
"notification.send.out.delay: 10",
"notification.send.out.initial.delay: 60000"
}
)We just set the 60 seconds of the initial delay. There should be enough time for the integration test to pass without interferences with Spring-managed scheduled tasks.
However, we need to note that it’s the action of a last resort when the previously shown options are impossible to be introduced. It’s a good practice to avoid introducing any time-related dependencies to the code. There are many reasons for the test to sometimes take slightly more time to execute. Let’s consider a trivial example of an overutilized CI server. In such a case, we risk having flaky tests in the project.
In this article, we’ve discussed different options for configuring integration tests while testing applications that use scheduled tasks mechanisms.
We’ve showcased the consequences of just leaving the scheduler running together with the integration test at the same time. We risk it being flaky.
Next, we proceeded with ideas on how to make sure that scheduling doesn’t negatively impact our tests. It’s a good idea to disable scheduling by extracting the @EnableScheduling annotation to the separate configuration applied conditionally, based either on the profile or the property’s value. When it’s not possible, we can always set a high initial delay for the task executing the logic we’re testing.
All the code presented in this article is available over on GitHub.
In this tutorial, we’ll discuss the well-known Mockito annotations @InjectMock, @Mock, @Spy and understand how they work together in multiple-level injection scenarios. We’ll talk about important testing concepts and learn how to make a proper test configuration.
The multiple-level injection is a powerful concept, but it can be dangerous when misused. Let’s review important theoretical concepts before moving on to implementation.
By definition, a unit test is a test that covers one unit of source code. In the Java world, we can talk about the unit test as a test that covers some specific class – service, repository, utils, etc.
When testing a class, we want to test its business logic only, and not the behavior of its dependencies. To deal with dependencies, for example, to mock them, or to verify their usage, we usually use a mocking framework – Mockito. It has been designed to extend existing test engines (JUnit, TestNG) and helps to build unit tests for a class with multiple dependencies properly.
Spy is one of the essential pillars of Mockito that helps to work with dependencies effectively.
A Mock is a complete stub that performs no action when methods are called and doesn’t reach the actual object. On the contrary, Spy delegates all calls to the real object methods by default. And when specified, the spy method can behave as a mock with all its features.
We need to set up the spy object with the necessary dependencies due to its default behavior as a real object. Mockito tries to inject dependencies implicitly to the spy object. However, we can set dependencies explicitly when required.
Multiple-level injection in Mockito refers to the scenario where a tested class requires a spy, and this spy depends on specific mocks for injection, creating a nested injection structure.
In some scenarios, we might face a need for multiple-level mocking. For example, we’re testing some ServiceA, that depends on some complex MapperA, and MapperA depends on a different ServiceB. Generally, it will be easier to make MapperA a spy and inject ServiceB as a mock. However, such an approach breaks a unit test concept. When we need to cover more than one service in a test, we should rather stick to complete integration tests.
If we face a need for multiple-level injection too often, it can be a sign of an incorrect testing approach or complex code design, that should be refactored.
Before we move on to test cases, let’s define sample code to show how we can use Mockito to test our codebase.
We’ll work with the library concept, where we have a main Book entity, that is being processed by multiple services. The most important takeaway here is the dependencies between classes.
The entry point for processing is BookStorageService, that intended to store information about taken/given books and verify book state via BookControlService:
public class BookStorageService {
private BookControlService bookControlService;
private final List<Book> availableBooks;
}BookControlService on the other hand depends on two more classes, StatisticService and RepairService that should calculate the amount of processed books and check if the book should be repaired:
public class BookControlService {
private StatisticService statisticService;
private RepairService repairService;
}When we think about injecting one Mockito-managed class into another, @InjectMock annotation looks like the most intuitive mechanism. However, its capabilities are limited. The documentation highlights that Mockito should not be considered a dependency injection framework. It’s not designed to handle complex injection for networks of objects.
Also, Mockito won’t report any injection failure. In other words, when Mockito can’t inject a mock into the field, the field will remain null. Thus we’ll end up with multiple NullPointerExceptions (NPE) in case of incorrect test class setup.
@InjectMock behaves differently in the different configurations, and not every setup will work in the desired way. Let’s review the features of annotation usage in detail.
It might be intuitive to use multiple @InjectMock annotations in one class:
public class MultipleInjectMockDoestWorkTest {
@InjectMocks
private BookStorageService bookStorageService;
@Spy
@InjectMocks
private BookControlService bookControlService;
@Mock
private StatisticService statisticService;
}Such configuration is intended to inject statisticService mock into bookControlService spy and inject bookContorlService into bookStorageService. However, such a configuration doesn’t work and causes NPE in the newer Mockito versions.
Under the hood, the current version of the framework (5.10.0) collects all annotated objects into two collections. The first collection is for mock-dependent fields annotated with @InjectMock (bookStorageService and bookControlService).
The second collection is for all entities candidates for injection, which are all mocks and eligible spies. However, fields marked as @Spy and @InjectMock at the same time are never considered candidates for injection. As a result, Mockito won’t know that bookControlService should be injected into bookStorageService.
Another issue with the configuration above is conceptual. With @InjectMock annotation we’re targeting two classes (BookStorageService and BookControlService) to be tested in the class, which is against the unit test approach.
At the same time, there is no restriction on the usage of @Spy and @InjectMock together, as soon as there is only one @InjectMock annotation in the class:
@Spy
@InjectMocks
private BookControlService bookControlService;
@Mock
private StatisticService statisticService;
@Spy
private RepairService repairService;
With this configuration, we have a properly built and testable hierarchy:
@Test
void whenOneInjectMockWithSpy_thenHierarchySuccessfullyInitialized(){
Book book = new Book("Some name", "Some author", 355, ZonedDateTime.now());
bookControlService.returnBook(book);
Assertions.assertNull(book.getReturnDate());
Mockito.verify(statisticService).calculateAdded();
Mockito.verify(repairService).shouldRepair(book);
}One of the options to resolve multiple-level injection is to manually instantiate a spy object before Mockito initialization. As we’ve already discussed, Mockito cannot inject all dependencies into the field, which is annotated with both @Spy and @InjectMock. However, the framework can inject dependencies to an object that is annotated with @InjectMock only, even if this object is a spy.
We can use @ExtendWith(MockitoExtension.class) on the class level and initialize spy in the field:
@InjectMocks
private BookControlService bookControlService = Mockito.spy(BookControlService.class);Or we can use MockitoAnnotations.openMocks(this) and initialize spy in the @BeforeEach method:
@BeforeEach
public void openMocks() {
bookControlService = Mockito.spy(BookControlService.class);
closeable = MockitoAnnotations.openMocks(this);
}In both cases, a spy should be created before Mockito initialization.
With the setups above, Mockito handles @InjectMock on the manually created spy and injects all needed mocks:
@InjectMocks
private BookStorageService bookStorageService;
@InjectMocks
private BookControlService bookControlService;
@Mock
private StatisticService statisticService;
@Mock
private RepairService repairService;The test is successfully executed:
@Test
void whenSpyIsManuallyCreated_thenInjectMocksWorks() {
Book book = new Book("Some name", "Some author", 355);
bookStorageService.returnBook(book);
Assertions.assertEquals(1, bookStorageService.getAvailableBooks().size());
Mockito.verify(bookControlService).returnBook(book);
Mockito.verify(statisticService).calculateAdded();
Mockito.verify(repairService).shouldRepair(book);
}Another possible approach to handling complex test setups is by manually creating the required spy object and then injecting it into the object under test. Leveraging reflection mechanisms, we can update Mockito-created objects with the needed spy.
In the following example, rather than annotating BookControlService with @InjectMocks, we’ve manually configured everything. To ensure the Mockito-created mocks are available during spy initialization, the Mockito context must be initialized first. Otherwise, NullPointerExceptions may occur wherever mocks are utilized.
Once the BookControlService spy is configured with all mocks, we inject it to BookStorageService via reflection:
@InjectMocks
private BookStorageService bookStorageService;
@Mock
private StatisticService statisticService;
@Mock
private RepairService repairService;
private BookControlService bookControlService;
@BeforeEach
public void openMocks() throws Exception {
bookControlService = Mockito.spy(new BookControlService(statisticService, repairService));
injectSpyToTestedMock(bookStorageService, bookControlService);
}With such a configuration, we can verify the behavior of repairService and bookControlService.
In this article, we’ve reviewed the important unit-test concepts and learned how to work with @InjectMock, @Spy, and @Mock annotations to perform complex multiple-level injections. We’ve discovered how spy can be configured manually and how it can be injected into the tested object.
As always, the complete examples are available over on GitHub.