1. Introduction
Maven is one of the most popular build and dependency management tools in the Java ecosystem. While it provides a convenient way to declare and use different frameworks and libraries in a project, some unexpected problems could arise when dealing with many dependencies in our applications.
To avoid such compile time and runtime issues, we’ll learn how to properly configure the list of dependencies. In this tutorial, we’ll also mention the tools we can use to detect and fix the inconsistencies between different versions of artifacts.
2. The Dependency Mechanism
For starters, let’s briefly review the main concepts of Maven.
As previously learned, a Project Object Model (POM) configures a Maven project. This XML file contains details about the project and configuration information necessary to build it.
The external libraries declared in the pom.xml file are called dependencies. Each dependency is uniquely defined using a set of identifiers – groupId, artifactId, and version – commonly referred to as Coordinates. Maven’s internal mechanisms automatically resolve and download dependencies from a central repository, making them available in our projects.
Complex projects usually have multiple dependencies, some of which depend on other libraries. Those explicitly listed in the project’s pom are called direct dependencies. On the other hand, the dependencies of direct ones are called transitive, and Maven automatically includes them.
Let’s explain those in more detail.
2.1. Transitive Dependencies
A transitive dependency is simply a dependency of a dependency. Let’s illustrate this:
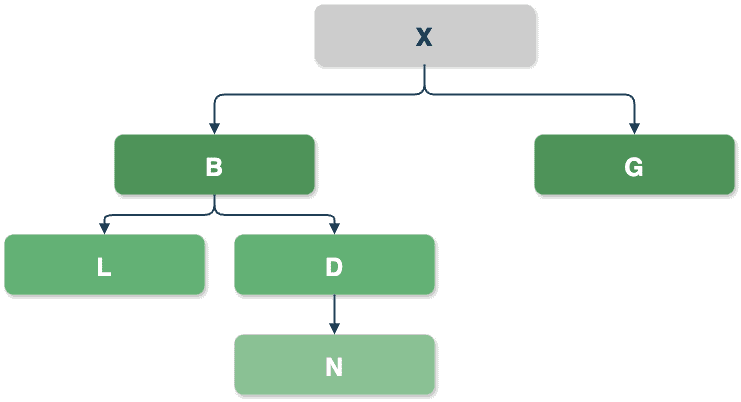
As shown in the example graph above, our code base X depends on several other projects. One of X‘s dependencies is project B, which depends on projects L and D. These two, L and D, are the transitive dependencies of X. If D also depends on N, then N becomes another transitive dependency of X. On the other hand, project G is a direct dependency of X and has no additional dependencies, so there will be no transitives included on this path.
One of Maven’s key features is its ability to manage transitive dependencies. If our project relies on a library that, in turn, depends on others, Maven will eliminate the need to track all the dependencies required to compile and run an application.
In the example above, we would add dependencies B and G to our pom.xml, and Maven will take care of the rest. This is particularly useful for large enterprise applications since they can have hundreds of dependencies. In such scenarios, besides having duplicate dependencies, multiple direct dependencies may require different versions of the same JAR file. In other words, we would have dependencies that might not work together.
Luckily, a few other Maven features come in handy to limit the included dependencies.
2.2. Dependency Mediation
We’ve covered most of them in our other tutorials – dependency management, scope, exclusion, and optional dependencies. Here, we’ll focus on dependency mediation.
Let’s see this in action:
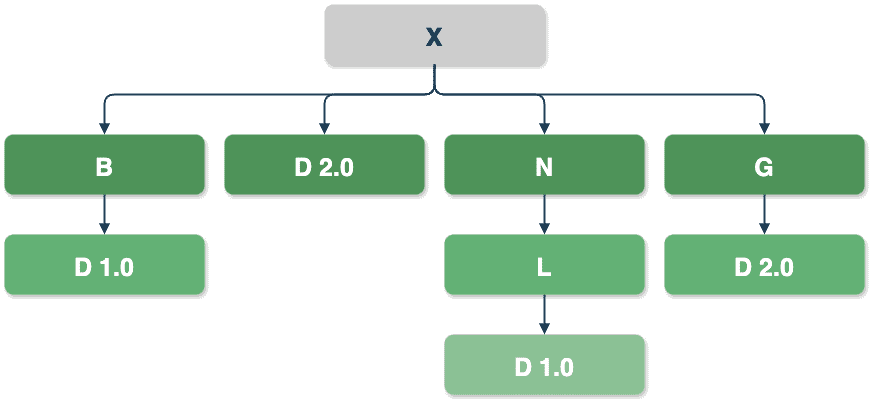
In the example above, Maven will resolve the conflicts by choosing the version of D nearest to the root of the dependency tree (X) – version D 2.0 via path X -> D 2.0.
In the path X -> G -> D 2.0, D is a transitive dependency, but since it is the same version as a direct D dependency, it is omitted due to duplication. Other transitive dependencies, i.e., X -> B -> D 1.0 and X -> N -> L -> D 1.0, are omitted due to conflict since their versions differ from the direct dependency D.
On the other hand, if X doesn’t declare D as a direct dependency, dependencies X -> B -> D 1.0 and X -> G -> D 2.0 will have the same tree depth. When two dependencies are at the same level in the dependency tree, the first declaration wins, so D 1.0 will be used in the final build.
3. Dependency Ordering Problems
To demonstrate the scenario above, let’s switch to a more realistic example that uses common libraries – Apache POI and OpenCSV. Both depend on Apache Commons Collections, so our project adds this library as a transitive dependency.
3.1. Practical Example
We’ll intentionally select the older versions of Apache POI and OpenCSV dependencies, the ones that use different versions of Apache Commons Collections:
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>4.2</version>
</dependency>
</dependencies>Moreover, the two commons-collections4 libraries are at the same depth of the dependency tree. We can verify that using a mvn dependency:tree command. With it, we can list all dependencies in the project, both direct and transitive ones:
mvn dependency:tree -Dverbose
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ dependency-ordering ---
[INFO] com.baeldung:dependency-ordering:jar:0.0.1-SNAPSHOT
[INFO] +- org.apache.poi:poi:jar:5.3.0:compile
[INFO] | \- org.apache.commons:commons-collections4:jar:4.4:compile
...
[INFO] +- com.opencsv:opencsv:jar:4.2:compile
[INFO] | \- (org.apache.commons:commons-collections4:jar:4.1:compile - omitted for conflict with 4.4)
...As we can see, the project will use version 4.4. Between versions 4.1 and 4.4., there were multiple changes. Besides many, in release 4.2, the method MapUtils.size(Map<?, ?>) was added.
Let’s make use of it in a simple test to demonstrate the dependency ordering issue:
@Test
void whenCorrectDependencyVersionIsUsed_thenShouldCompile() {
assertEquals(0, MapUtils.size(new HashMap<>()));
}The code compiles and the test passes successfully. Let’s now change the order of the dependencies in the pom.xml file and recompile the code.
Consequently, the following error occurs:
java: cannot find symbol
symbol: method size(java.util.HashMap<java.lang.Object,java.lang.Object>)
location: class org.apache.commons.collections4.MapUtilsAdditionally, we can use the mvn dependency:tree command again to check if anything has changed:
$ mvn dependency:tree -Dverbose
[INFO] com.baeldung:dependency-ordering:jar:0.0.1-SNAPSHOT
[INFO] +- com.opencsv:opencsv:jar:4.2:compile
[INFO] | \- org.apache.commons:commons-collections4:jar:4.1:compile
...
[INFO] +- org.apache.poi:poi:jar:5.3.0:compile
[INFO] | \- (org.apache.commons:commons-collections4:jar:4.4:compile - omitted for conflict with 4.1)
...Our code now uses an older version of the commons-collections4 library that doesn’t have the MapUtils.size method.
3.2. Common Exceptions Indicating a Dependency Resolution Problem
Besides the cannot find symbol error, dependency problems can manifest in various ways. Here are some of the most frequently encountered ones:
- NoSuchFieldError,
- NoSuchMethodError,
- NoSuchMethodException,
- ClassNotFoundException,
- NoClassDefFoundError
Custom and Core Maven plugins also require dependencies to be able to execute specific goals. If there is an issue, we will get back an error like this:
[ERROR] Failed to execute goal (…) on project (…): Execution (…) of goal (…) failed: A required class was missing while executing (…)Unfortunately, not all dependency-related exceptions occur at compile time.
4. Tools for Resolving Dependency Issues
Luckily, there are several tools available that help ensure runtime safety.
4.1. Maven Dependency Plugin
The Apache Maven Dependency Plugin helps manage and analyze project dependencies. With the maven-dependency-plugin, we can find unused ones, display the project’s dependency tree, find duplicate dependencies, and much more.
4.2. Maven Enforcer Plugin
On the other hand, maven-enforcer-plugin allows us to enforce rules and guidelines within a project. One option the plugin provides is the ability to ban specific dependencies – this can include both direct and transitive dependencies. With the enforcer plugin, we can also make sure our project doesn’t have duplicate dependencies.
4.3. Maven Help Plugin
Since POMs can inherit configuration from other POMs, the final version could combine various POMs. The maven-help-plugin provides information about a project. To get more information that could help identify configuration issues, we can use the plugin’s effective-pom goal to display the effective POM as XML.
5. Conclusion
In this article, we’ve covered several techniques for improving the control of dependencies in our projects.
Frequently updating, adding new, and maintaining existing libraries includes ensuring compatibility among all dependencies, which could be challenging. However, existing Maven features help the process. While various plugins can automate dependency management and enforce version consistency, it’s important to remember Maven’s resolution rules.
To sum up, when encountering multiple versions of dependencies, Maven resolves conflicts by first using the depth of a dependency in the tree. Here, the definition closest to the root of the dependency tree is selected. On the other hand, if two dependency versions are at the same depth in the tree, Maven uses the one declared first in the project’s POM and makes it available in the final build.
As always, the complete source code with examples is available over on GitHub.