↧
TEST 5
↧
Advise Methods on Annotated Classes With AspectJ
1. Overview
In this tutorial, we'll use AspectJ to write trace logging output when calling methods of configured classes. By using an AOP advice to write trace logging output, we encapsulate the logic into a single compilation unit.
Our example expands upon the information presented in Intro to AspectJ.
2. Trace Logging Annotation
We'll use an annotation to configure classes so their method calls can be traced. Using an annotation gives us an easy mechanism for adding the trace logging output to new code without having to add logging statements directly.
Let's create the annotation:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Trace {
}3. Creating Our Aspect
We'll create an aspect to define our pointcut to match the join points we care about and the around advice containing the logic to execute.
Our aspect will look similar to this:
public aspect TracingAspect {
private static final Log LOG = LogFactory.getLog(TracingAspect.class);
pointcut traceAnnotatedClasses(): within(@Trace *) && execution(* *(..));
Object around() : traceAnnotatedClasses() {
String signature = thisJoinPoint.getSignature().toShortString();
LOG.trace("Entering " + signature);
try {
return proceed();
} finally {
LOG.trace("Exiting " + signature);
}
}
}In our aspect, we define a pointcut named traceAnnotatedClasses to match the execution of methods within classes annotated with our Trace annotation. By defining and naming a pointcut, we can reuse it as we would a method in a class. We'll use this named pointcut to configure our around advice.
Our around advice will execute in place of any join point matched by our pointcut and will return an Object. By having an Object return type, we can account for advised methods having any return type, even void.
We retrieve the signature of the matched join point to create a short String representation of the signature to add context to our tracing messages. As a result, our logging output will have the name of the class and the method executed, which gives us some needed context.
In between our trace output calls, we've called a method named proceed. This method is available for around advice in order to continue the execution of the matched join point. The return type will be Object since we have no way to know the return type at compile time. We will send this value back to the caller after sending the final trace output to the log.
We wrap the proceed() call in a try/finally block to ensure the exit message is written. If we wanted to trace the thrown exception, we could add after() advice to write a log message when an exception is thrown:
after() throwing (Exception e) : traceAnnotatedClasses() {
LOG.trace("Exception thrown from " + thisJoinPoint.getSignature().toShortString(), e);
}4. Annotating Our Code
Now we need to enable our trace. Let's create a simple class and activate the trace logging with our custom annotation:
@Trace
@Component
public class MyTracedService {
public void performSomeLogic() {
...
}
public void performSomeAdditionalLogic() {
...
}
}With the Trace annotation in place, the methods in our class will match the pointcut we've defined. When these methods execute, the tracing messages will be written to the log.
After running our code calling these methods, our log output should include content similar to:
22:37:58.867 [main] TRACE c.b.a.c.TracingAspect - Entering MyTracedService.performSomeAdditionalLogic()
22:37:58.868 [main] INFO c.b.a.c.MyTracedService - Inside performSomeAdditionalLogic...
22:37:58.868 [main] TRACE c.b.a.c.TracingAspect - Exiting MyTracedService.performSomeAdditionalLogic()
22:37:58.869 [main] TRACE c.b.a.c.TracingAspect - Entering MyTracedService.performSomeLogic()
22:37:58.869 [main] INFO c.b.a.c.MyTracedService - Inside performSomeLogic...
22:37:58.869 [main] TRACE c.b.a.c.TracingAspect - Exiting MyTracedService.performSomeLogic()
5. Conclusion
In this article, we used AspectJ to intercept all of a class's methods with a single annotation on the class. Doing so allows us to quickly add our trace logging functionality to new code.
We also consolidated our trace logging output logic to a single compilation unit to improve our ability to modify our trace logging output as our application evolves.
As always, the full source code of the article is available over on GitHub.
The post Advise Methods on Annotated Classes With AspectJ first appeared on Baeldung.






↧
↧
Java Weekly, Issue 384
1. Spring and Java
>> Why Java's Records Are Better* Than Lombok's @Data and Kotlin's Data Classes [nipafx.dev]
More than just boilerplate reductions: a practical take on why Java records are superior to other approaches. Interesting read.
>> Kotlin 1.5.0 – the First Big Release of 2021 [blog.jetbrains.com]
The New Kotlin version supports stable features such as Java records, indy for string concatenations, and lots of new standard library features.
>> JEP 413: Code Snippets in Java API Documentation [openjdk.java.net]
No more @code or <pre> tags – this is a proposal to simplify the addition of example codes in Javadocs.
Also worth reading:
- >> A real-world example of a Stream Collector [blog.frankel.ch]
- >> Compilation Meets Documentation [infoq.com]
- >> “Failed to write core dump” [inside.java]
- >> Spring Cloud Gateway for Kubernetes [spring.io]
- >> Creating and Analyzing Thread Dumps [reflectoring.io]
- >> JHipster Releases Micronaut Blueprint 1.0.0 [infoq.com]
- >> Exploring a Spring Boot App with Actuator and jq [reflectoring.io]
Webinars and presentations:
- >> A Bootiful Podcast: Oracle's Dilip Krishnan about Spring Fox, the Oracle Cloud Lift team, and more [spring.io]
Time to upgrade:
- >> IntelliJ IDEA 2021.1.1 Is Available [blog.jetbrains.com]
- >> Quarkus 1.13.3.Final released – Maintenance release [quarkus.io]
- >> Spring Security 5.5.0-RC2 released [spring.io]
- >> Hibernate ORM 5.4.31.Final and 5.5.0.Alpha1 released [in.relation.to]
- >> Hibernate Reactive 1.0.0.CR4 released [in.relation.to]
- >> Hibernate Search 5.11.9.Final and 5.10.11.Final released [in.relation.to]
- >> JReleaser 0.2.0 has been released! [andresalmiray.com]
2. Technical & Musings
>> How to index JSON columns using MySQL [vladmihalcea.com]
Virtual columns to the rescue – index JSON fields without having access to a GIN index type in MySQL.
Also worth reading:
- >> Why I’m using Linux (Video) [blog.sebastian-daschner.com]
- >> Developers are Obsessed With Their Text Editors [techblog.bozho.net]
- >> Supporting bulk operations in REST APIs [mscharhag.com]
- >> COVID19 Predictions for 2021 [jacquesmattheij.com]
3. Comics
And my favorite Dilberts of the week:
>> Must Register To Date [dilbert.com]
>> Project On Hold [dilbert.com]
>> Shaking Hands [dilbert.com]
4. Pick of the Week
>> The Podcast for Location Independent Business Owners [tropicalmba.com]
The post Java Weekly, Issue 384 first appeared on Baeldung. ↧
Should Logging Out Be a GET or POST?
1. Overview
In a traditional web application, logging in usually requires sending a username and password to the server for authentication. While these elements could theoretically be URL parameters in a GET request, it is obviously much better to encapsulate them into a POST request.
However, should logging out be available through a GET request since it does not require any sensitive information to be sent?
In this tutorial, we'll look at various aspects of this design consideration.
2. Server-Side Sessions
When we manage server-side sessions, we must expose an endpoint to destroy those sessions. We may be tempted to use the GET method due to its simplicity. Of course, this will technically work, but it may lead to some undesirable behavior.
There are some processes like web accelerators that will prefetch GET links for the user. The purpose of prefetching is to immediately serve content when a user follows that link, which cuts down on page loading times. These processes make an assumption that the GET link is strictly for returning content and not for changing the state of anything.
If we expose our logout as a GET request and present it as a link, these processes may inadvertently log users out while trying to prefetch links on the page.
This may not be a problem if our logout URL is not statically available, such as being determined by javascript, for example. However, the HTTP/1.1 RFC clearly states that GET methods should only be used to return content and the user cannot be held responsible for any side-effects of a GET request. We should follow this recommendation whenever possible.
In contrast, the RFC describes the POST method as one that can submit data (our session or session ID) to a data-handling process (logout). This is a more appropriate description of what we are trying to accomplish.
2.1. Spring Security
By default, Spring Security requires the logout request to be of type POST. However, we can cause Spring to use a GET logout request when we disable CSRF protection:
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable()
...
}3. Stateless REST
When we manage stateless REST sessions, the concept of “logging out” changes. In a stateless environment, every request includes the entire session. Therefore, it is possible to “log out” by simply using Javascript to throw away the session rather than sending any kind of request at all.
However, for security reasons, the server should still be notified of log-out actions in order to blacklist the revoked JWT. This prevents a session from being used after “logging out.”
Even in a stateless environment, we must still send a request to the server upon logging out. Since the intent of such a request is not to retrieve content, it should not be made via GET. Instead, the session should be POST-ed to the server with the explicit intent to log out.
4. Conclusion
In this short discussion, we've briefly looked at the common design question of whether logging out should be a GET or POST.
We considered various aspects of this issue:
- Semantically, GET requests should not have any stateful side effects
- There are processes that users might be running in their browser that include prefetching links. If logging out happens over GET, a prefetching process could inadvertently log the user out after logging in
- Even stateless sessions should report log-out events to the server, which should be done via a POST request
↧
A Guide to Events in OkHTTP
1. Overview
Typically when working with HTTP calls in our web applications, we'll want a way to capture some kind of metrics about the requests and responses. Usually, this is to monitor the size and frequency of the HTTP calls our application makes.
OkHttp is an efficient HTTP & HTTP/2 client for Android and Java applications. In a previous tutorial, we looked at the basics of how to work with OkHttp.
In this tutorial, we'll learn all about how we can capture these types of metrics using events.
2. Events
As the name suggests, events provide a powerful mechanism for us to record application metrics relating to the entire HTTP call life cycle.
In order to subscribe to the events we are interested in all, we need to do is define an EventListener and override the methods for the events we want to capture.
This is particularly useful if, for example, we only want to monitor failed and successful calls. In that case, we simply override the specific methods that correspond to those events within our event listener class. We'll see this in more detail later.
There is at least a couple of advantages to using events in our applications:
- We can use events to monitor the size and frequency of the HTTP calls our application makes
- This can help us quickly determine where we might have a bottleneck in our application
Finally, we can also use events to determine if we have an underlying problem with our network as well.
3. Dependencies
Of course, we'll need to add the standard okhttp dependency to our pom.xml:
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.9.1</version>
</dependency>We'll also need another dependency specifically for our tests. Let's add the OkHttp mockwebserver artifact:
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>mockwebserver</artifactId>
<version>4.9.1</version>
<scope>test</scope>
</dependency>Now that we have all the necessary dependencies configured, we can go ahead and write our first event listener.
4. Event Methods and Order
But before we start defining our own event listener, we're going to take a step back and briefly look at what event methods are available to us and also the order we can expect events to arrive in. This will help us when we dive into some real examples later on.
Let's assume we're dealing with a successful HTTP call with no redirects or retries. Then we can expect this typical flow of method calls.
4.1. callStart()
This method is our entry point, and we'll invoke it as soon as we enqueue a call or our client executes it.
4.2. proxySelectStart() and proxySelectEnd()
The first method is invoked prior to a proxy selection and likewise after proxy selection, including the lists of proxies in the order they will be attempted. This list can, of course, be empty if no proxy is configured.
4.3. dnsStart() and dnsEnd()
These methods are invoked just before DNS lookup and immediately after the DNS is resolved.
4.4. connectStart() and connectEnd()
These methods are invoked prior to establishing and closing a socket connection.
4.5. secureConnectStart() and secureConnectEnd()
If our call uses HTTPS, then interspersed between connectStart and connectEnd we'll have these secure connect variations.
4.6. connectionAcquired() and connectionReleased()
Called after a connection has been acquired or released.
4.7. requestHeadersStart() and requestHeadersEnd()
These methods will be invoked immediately prior to and after sending request headers.
4.8. requestBodyStart() and requestBodyEnd()
As the name suggests, invoked prior to sending a request body. Of course, this will only apply to requests that contain a body.
4.9. responseHeadersStart() and responseHeadersEnd()
These methods are called when response headers are first returned from the server and immediately after they are received.
4.10. responseBodyStart() and responseBodyEnd()
Likewise, called when the response body is first returned from the server and immediately after the body is received.
In addition to these methods, we also have three additional methods we can use for capturing failures:
4.11. callFailed(), responseFailed(), and requestFailed()
If our call fails permanently, the request has a write failure, or the response has a read failure.
5. Defining a Simple Event Listener
Let's start by defining our own even listener. To keep things really simple, our event listener will log when the call starts and ends along with some request and response header information:
public class SimpleLogEventsListener extends EventListener {
private static final Logger LOGGER = LoggerFactory.getLogger(SimpleLogEventsListener.class);
@Override
public void callStart(Call call) {
LOGGER.info("callStart at {}", LocalDateTime.now());
}
@Override
public void requestHeadersEnd(Call call, Request request) {
LOGGER.info("requestHeadersEnd at {} with headers {}", LocalDateTime.now(), request.headers());
}
@Override
public void responseHeadersEnd(Call call, Response response) {
LOGGER.info("responseHeadersEnd at {} with headers {}", LocalDateTime.now(), response.headers());
}
@Override
public void callEnd(Call call) {
LOGGER.info("callEnd at {}", LocalDateTime.now());
}
}As we can see, to create our listener, all we need to do is extend from the EventListener class. Then we can go ahead and override the methods for the events we care about.
In our simple listener, we log the time the call starts and ends along with the request and response headers when they arrive.
5.1. Plugging It Together
To actually make use of this listener, all we need to do is call the eventListener method when we build our OkHttpClient instance, and it should just work:
OkHttpClient client = new OkHttpClient.Builder()
.eventListener(new SimpleLogEventsListener())
.build();In the next section, we'll take a look at how we can test our new listener.
5.2. Testing the Event Listener
Now, we have defined our first event listener; let's go ahead and write our first integration test:
@Rule
public MockWebServer server = new MockWebServer();
@Test
public void givenSimpleEventLogger_whenRequestSent_thenCallsLogged() throws IOException {
server.enqueue(new MockResponse().setBody("Hello Baeldung Readers!"));
OkHttpClient client = new OkHttpClient.Builder()
.eventListener(new SimpleLogEventsListener())
.build();
Request request = new Request.Builder()
.url(server.url("/"))
.build();
try (Response response = client.newCall(request).execute()) {
assertEquals("Response code should be: ", 200, response.code());
assertEquals("Body should be: ", "Hello Baeldung Readers!", response.body().string());
}
}First of all, we are using the OkHttp MockWebServer JUnit rule.
This is a lightweight, scriptable web server for testing HTTP clients that we're going to use to test our event listeners. By using this rule, we'll create a clean instance of the server for every integration test.
With that in mind, let's now walk through the key parts of our test:
- First of all, we set up a mock response that contains a simple message in the body
- Then, we build our OkHttpClient and configure our SimpleLogEventsListener
- Finally, we send the request and check the response code and body received using assertions
5.3. Running the Test
When we run our test, we'll see our events logged:
callStart at 2021-05-04T17:51:33.024
...
requestHeadersEnd at 2021-05-04T17:51:33.046 with headers User-Agent: A Baeldung Reader
Host: localhost:51748
Connection: Keep-Alive
Accept-Encoding: gzip
...
responseHeadersEnd at 2021-05-04T17:51:33.053 with headers Content-Length: 23
callEnd at 2021-05-04T17:51:33.0556. Putting It All Together
Now let's imagine we want to build on our simple logging example and record the elapsed times for each of the steps in our call chain:
public class EventTimer extends EventListener {
private long start;
private void logTimedEvent(String name) {
long now = System.nanoTime();
if (name.equals("callStart")) {
start = now;
}
long elapsedNanos = now - start;
System.out.printf("%.3f %s%n", elapsedNanos / 1000000000d, name);
}
@Override
public void callStart(Call call) {
logTimedEvent("callStart");
}
// More event listener methods
}This is very similar to our first example, but this time we capture the elapsed time from when our call started for each event. Typically this could be quite interesting to detect network latency.
Let's take a look if we run this against a real site like our very own https://www.baeldung.com/:
0.000 callStart
0.012 proxySelectStart
0.012 proxySelectEnd
0.012 dnsStart
0.175 dnsEnd
0.183 connectStart
0.248 secureConnectStart
0.608 secureConnectEnd
0.608 connectEnd
0.609 connectionAcquired
0.612 requestHeadersStart
0.613 requestHeadersEnd
0.706 responseHeadersStart
0.707 responseHeadersEnd
0.765 responseBodyStart
0.765 responseBodyEnd
0.765 connectionReleased
0.765 callEnd
As this call is going over HTTPS, we'll also see the secureConnectStart and secureConnectStart events.
7. Monitoring Failed Calls
Up until now, we've focussed on successfully HTTP requests, but we can also capture failed events:
@Test (expected = SocketTimeoutException.class)
public void givenConnectionError_whenRequestSent_thenFailedCallsLogged() throws IOException {
OkHttpClient client = new OkHttpClient.Builder()
.eventListener(new EventTimer())
.build();
Request request = new Request.Builder()
.url(server.url("/"))
.build();
client.newCall(request).execute();
}In this example, we've deliberately avoided setting up our mock web server, which means, of course, we'll see a catastrophic failure in the form of a SocketTimeoutException.
Let's take a look at the output when we run our test now:
0.000 callStart
...
10.008 responseFailed
10.009 connectionReleased
10.009 callFailedAs expected, we'll see our call start, and then after 10 seconds, the connection timeout occurs, and consequently, we see the responseFailed and callFailed events logged.
8. A Quick Word on Concurrency
So far, we have assumed that we do not have multiple calls executing concurrently. If we want to accommodate this scenario, then we need to use the eventListenerFactory method when we configure our OkHttpClient.
We can use a factory to create a new EventListener instance for each HTTP call. When we use this approach, it is possible to keep a call-specific state in our listener.
9. Conclusion
In this article, we've learned all about how to capture events using OkHttp. First, we began by explaining what an event is and understanding what kind of events are available to us and the order they arrive in when processing an HTTP call.
Then we took a look at how we can define a simple event logger to capture parts of our HTTP calls and how to write an integration test.
As always, the full source code of the article is available over on GitHub.
The post A Guide to Events in OkHTTP first appeared on Baeldung. ↧
↧
Spring Boot Cache with Redis
1. Introduction
In this short tutorial, we'll look at how to configure Redis as the data store for Spring Boot cache.
2. Dependencies
To get started, let's add the spring-boot-starter-cache and spring-boot-starter-data-redis artifacts:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.4.3</version>
</dependency>These add caching support and bring in all the required dependencies.
3. Configuration
By adding the above dependencies and the @EnableCaching annotation, Spring Boot will auto-configure a RedisCacheManager with default cache configuration. However, we can modify this configuration prior to cache manager initialization in a couple of useful ways.
First, let's create a RedisCacheConfiguration bean:
@Bean
public RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(60))
.disableCachingNullValues()
.serializeValuesWith(SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}This gives us more control over the default configuration — for example, we can set the desired time-to-live (TTL) values and customize the default serialization strategy for in-flight cache creation.
Following on, in order to have full control over the caching setup, let's register our own RedisCacheManagerBuilderCustomizer bean:
@Bean
public RedisCacheManagerBuilderCustomizer redisCacheManagerBuilderCustomizer() {
return (builder) -> builder
.withCacheConfiguration("itemCache",
RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofMinutes(10)))
.withCacheConfiguration("customerCache",
RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofMinutes(5)));
}Here, we've used RedisCacheManagerBuilder along with RedisCacheConfiguration to configure TTL values of 10 and 5 minutes for itemCache and customerCache, respectively. This helps to further fine-tune the caching behavior on a per-cache basis including null values, key prefixes, and binary serialization.
It's worth mentioning that the default connection details for the Redis instance are localhost:6379. Redis configuration can be used to further tweak the low-level connection details along with the host and port.
4. Example
In our example, we have an ItemService component that retrieves item information from the database. In effect, this represents a potentially costly operation and a good candidate for caching.
First, let's create the integration test for this component using an embedded Redis server:
@Import({ CacheConfig.class, ItemService.class})
@ExtendWith(SpringExtension.class)
@EnableCaching
@ImportAutoConfiguration(classes = {
CacheAutoConfiguration.class,
RedisAutoConfiguration.class
})
class ItemServiceCachingIntegrationTest {
@MockBean
private ItemRepository mockItemRepository;
@Autowired
private ItemService itemService;
@Autowired
private CacheManager cacheManager;
@Test
void givenRedisCaching_whenFindItemById_thenItemReturnedFromCache() {
Item anItem = new Item(AN_ID, A_DESCRIPTION);
given(mockItemRepository.findById(AN_ID))
.willReturn(Optional.of(anItem));
Item itemCacheMiss = itemService.getItemForId(AN_ID);
Item itemCacheHit = itemService.getItemForId(AN_ID);
assertThat(itemCacheMiss).isEqualTo(anItem);
assertThat(itemCacheHit).isEqualTo(anItem);
verify(mockItemRepository, times(1)).findById(AN_ID);
assertThat(itemFromCache()).isEqualTo(anItem);
}
}Here, we create a test slice for the caching behavior and invoke the getItemForId twice. The first invocation should obtain the item from the repository, but the second invocation should return the item from the cache without invoking the repository.
Finally, let's enable the caching behavior using Spring's @Cacheable annotation:
@Cacheable(value = "itemCache")
public Item getItemForId(String id) {
return itemRepository.findById(id)
.orElseThrow(RuntimeException::new);
}This applies the caching logic while relying on the Redis cache infrastructure that we've configured earlier. Further details about controlling properties and behaviors of the Spring caching abstraction, including data update and eviction, are covered in our Guide to Caching in Spring article.
5. Conclusion
In this tutorial, we've seen how to use Redis for Spring caching.
Initially, we described how to auto-configure Redis caching with minimal configuration. Then, we looked at how to further customize the caching behavior by registering configuration beans.
Finally, we created a sample use case to demonstrate this caching in practice.
As always, the full source code is available over on GitHub.
The post Spring Boot Cache with Redis first appeared on Baeldung. ↧
How to Convert Mono Into Flux
1. Overview
Sometimes in Reactive Programming, we could have a publisher of a large collection of items. In some cases, consumers of this publisher might not be able to process all items in one go. Therefore, we may need to publish each item asynchronously to match the consumer's processing speed.
In this tutorial, we'll be looking into some ways by which we can convert our Mono of a Collection to Flux of Collection's items.
2. Problem Description
When working with Reactive Streams, we use a Publisher and its two implementations, Flux and Mono. Though Mono<T> is a type of Publisher<T> that can emit 0 or 1 item of type T, the Flux<T> can emit 0 to N items of type T.
Let's say we have a Mono publisher that is holding a Mono<List<T>> — an iterable collection of items of type T. Our requirement is to produce the collection items asynchronously using Flux<T>:
Here, we can see that we need an operator on Mono<List<T>> that can perform this transformation. First, we'll extract collection items from stream publisher Mono and then produce items one by one asynchronously as Flux.
The Mono publisher contains a map operator, which can transform a Mono synchronously, and a flatMap operator for transforming a Mono asynchronously. Also, both of these operators produce a single item as an output.
However, for our use case to produce many items after flattening Mono<List<T>>, we can use flatMapMany or flatMapIterable.
Let's explore how to use these operators.
3. flatMapMany
Let's start with a sample List of String to create our Mono publisher:
private Mono<List<String>> monoOfList() {
List<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
return Mono.just(list);
}The flatMapMany is a generic operator on Mono that returns a Publisher. Let's apply flatMapManyto our solution:
private <T> Flux<T> monoTofluxUsingFlatMapMany(Mono<List<T>> monoList) {
return monoList
.flatMapMany(Flux::fromIterable)
.log();
}In this case, the flatMapMany takes the Mono‘s List, flattens it, and creates a Flux publisher using Flux operator the fromIterable. We also used log() here to log each element produced. Therefore, this will output elements one by one like “one“, “two“, “three“, “four“, and then terminate.
4. flatMapIterable
For the same sample List of String, we'll now explore flatMapIterable — a custom-built operator.
Here, we don't need to create Flux explicitly from the List; we only need to provide the List. This operator implicitly creates a Flux out of its elements. Let's use flatMapIterable for our solution:
private <T> Flux<T> monoTofluxUsingFlatMapIterable(Mono<List<T>> monoList) {
return monoList
.flatMapIterable(list -> list)
.log();
}Here, flatMapIterable takes the Mono‘s List and converts it internally into a Flux of its elements. Hence, it's more optimized compared with the flatMapMany operator. And this will output the same “one“, “two“, “three“, “four“, and then terminate.
5. Conclusion
In this article, we discussed different ways to convert a Mono<List<T>> into Flux<T> using the operators flatMapMany and flatMapIterable. Both are easy-to-use operators. Whereas flatMapMany is useful for more generic publishers, flatMapIterable is better optimized for such purposes.
As always, the code example is available over on GitHub.
The post How to Convert Mono- > Into Flux
↧
Using Namespaces and Selectors With the Kubernetes Java API
1. Introduction
In this tutorial, we'll explore different ways to filter resources using the Kubernetes Java API.
In our previous articles covering the Kubernetes Java API, we've focused on the available methods to query, manipulate, and monitor cluster resources.
Those examples assumed that we were either looking for resources of a specific kind or targeting a single resource. In practice, however, most applications need a way to locate resources based on some criteria.
Kubernetes' API supports three ways to limit the scope of those searches:
- Namespaces: scope limited to a given Kubernetes namespace
- Field Selectors: scope limited to resources having matching field values
- Label Selectors: scope limited to resources having matching labels
Moreover, we can combine those methods in a single query. This gives us a lot of flexibility to address even complex requirements.
Now, let's see each method in more detail.
2. Using Namespaces
Using namespaces is the most basic way to limit the scope of a query. As the name implies, a namespaced query only returns items within the specified namespace.
In the Java API, namespaced query methods follow the pattern listNamespacedXXX(). For instance, to list pods in a specific namespace, we'd use listNamespacedPod():
ApiClient client = Config.defaultClient();
CoreV1Api api = new CoreV1Api(client);
String ns = "ns1";
V1PodList items = api.listNamespacedPod(ns,null, null, null, null, null, null, null, null, 10, false);
items.getItems()
.stream()
.map((pod) -> pod.getMetadata().getName() )
.forEach((name) -> System.out.println("name=" + name));
Here, ApliClient and CoreV1Api are used to perform actual access to the Kubernetes API server. We use ns1 as the namespace to filter resources. We also use the remaining arguments similar to the ones in the non-namespaced method.
As expected, namespaced queries also have call variants, thus allowing us to create Watches using the same techniques described before. Asynchronous calls and paging also work in the same way as their non-namespaced versions.
3. Using Field Selectors
Namespaced API calls are simple to use but have some limitations:
- It's all-or-nothing, meaning we can't select more than one (but not all) namespaces
- No way to filter based on resource properties
- Using a different method for each scenario leads to more complex/verbose client code
Field selectors provide a way to select resources based on the value of one of its fields. A field in Kubernetes parlance is just the JSON path associated with a given value in a resource's YAML or JSON document. For instance, this is a typical Kubernetes YAML for a pod running an Apache HTTP server:
apiVersion: v1
kind: Pod
metadata:
labels:
app: httpd
name: httpd-6976bbc66c-4lbdp
namespace: ns1
spec:
... fields omitted
status:
... fields omitted
phase: Running
The field status.phase contains the status of an existing Pod. The corresponding field selector expression is simply the field name followed by an operator and value. Now, let's code a query that returns all running pods in all namespaces:
String fs = "status.phase=Running";
V1PodList items = api.listPodForAllNamespaces(null, null, fs, null, null, null, null, null, 10, false);
// ... process itemsA field selector expression supports only the equality (‘=' or ‘==') and inequality (‘!=') operators. Also, we can pass multiple comma-separated expressions in the same call. In this case, the net effect is that they'll be ANDed together to produce the final result:
String fs = "metadata.namespace=ns1,status.phase=Running";
V1PodList items = api.listPodForAllNamespaces(null, null, fs, null, null, null, null, null, 10, false);
// ... process items
Be aware: field values are case-sensitive! In the previous query, using “running” instead of “Running” (capital “R”) would yield an empty result set.
An important limitation of field selectors is that they are resource-dependent. Only metadata.name and metadata.namespace fields are supported across all resource kinds.
Nevertheless, field selectors are especially useful when used with dynamic fields. An example is the status.phase in the previous example. Using a field selector together with a Watch, we can easily create a monitoring application that gets notified when pods terminate.
4. Using Label Selectors
Labels are special fields that contain arbitrary key/value pairs that we can add to any Kubernetes resource as part of its creation. Label selectors are similar to field selector, as they essentially allow filtering a resource list based on its values, but offers more flexibility:
- Support for additional operators: in/notin/exists/not exists
- Consistent usage across resource types when compared to field selectors
Going back to the Java API, we use label selectors by constructing a string with the desired criteria and passing it in as an argument to the desired resource API listXXX call. Filtering for a specific label value using equality and/or inequality uses the same syntax used by field selectors.
Let's see the code that looks for all pods that have a label “app” with the value “httpd”:
String ls = "app=httpd";
V1PodList items = api.listPodForAllNamespaces(null, null, null, ls, null, null, null, null, 10, false);
// ... process itemsThe in operator resembles its SQL counterpart and allows us to create some OR logic in queries:
String ls = "app in ( httpd, test )";
V1PodList items = api.listPodForAllNamespaces(null, null, null, ls, null, null, null, null, 10, false);Also, we can check for the presence or absence of a field using the labelname or !labelname syntax:
String ls = "app";
V1PodList items = api.listPodForAllNamespaces(null, null, null, ls, null, null, null, null, 10, false);Finally, we can chain multiple expressions in a single API call. The resulting items list contains only resources that satisfy all expressions:
String ls = "app in ( httpd, test ),version=1,foo";
V1PodList items = api.listPodForAllNamespaces(null, null, null, ls, null, null, null, null, 10, false);5. Conclusion
In this article, we've covered different ways to filter resources using the Java Kubernetes API client. As usual, the full source code of the examples can be found over on GitHub.
The post Using Namespaces and Selectors With the Kubernetes Java API first appeared on Baeldung. ↧
Mapping PostgreSQL Array With Hibernate
1. Overview
PostgreSQL supports arrays of any type (built-in or user-defined) to be defined as types of columns of a table. In this tutorial, we'll explore a few ways to map the PostgreSQL array with Hibernate.
2. Basic Setup
As a pre-requisite to connect with a PostgreSQL database, we should add the latest postgresql Maven dependency to our pom.xml along with the Hibernate configurations. Also, let's create an entity class called User with the String array roles:
@Entity
public class User {
@Id
private Long id;
private String name;
private String[] roles;
//getters and setters
}
3. Custom Hibernate Types
Hibernate supports custom types to map a user-defined type into SQL queries. Therefore, we can create custom types to map a PostgreSQL array with Hibernate for storing/fetching data. First, let's create the CustomStringArrayType class implementing Hibernate's UserType class to provide a custom type to map the String array:
public class CustomStringArrayType implements UserType {
@Override
public int[] sqlTypes() {
return new int[]{Types.ARRAY};
}
@Override
public Class returnedClass() {
return String[].class;
}
@Override
public Object nullSafeGet(ResultSet rs, String[] names, SharedSessionContractImplementor session, Object owner)
throws HibernateException, SQLException {
Array array = rs.getArray(names[0]);
return array != null ? array.getArray() : null;
}
@Override
public void nullSafeSet(PreparedStatement st, Object value, int index, SharedSessionContractImplementor session)
throws HibernateException, SQLException {
if (value != null && st != null) {
Array array = session.connection().createArrayOf("text", (String[])value);
st.setArray(index, array);
} else {
st.setNull(index, sqlTypes()[0]);
}
}
//implement equals, hashCode, and other methods
}
Here, we should note that the return type of the returnedClass method is the String array. Also, the nullSafeSet method creates an array of PostgreSQL type text.
4. Mapping Array With Custom Hibernate Types
4.1. User Entity
Then, we'll use the CustomStringArrayType class to map the String array roles to the PostgreSQL text array:
@Entity
public class User {
//...
@Column(columnDefinition = "text[]")
@Type(type = "com.baeldung.hibernate.arraymapping.CustomStringArrayType")
private String[] roles;
//getters and setters
}
That’s it! We’re ready with our custom type implementation and array mapping to perform CRUD operations on the User entity.
4.2. Unit Test
To test our custom type, let's first insert a User object along with the String array roles:
@Test
public void givenArrayMapping_whenArraysAreInserted_thenPersistInDB()
throws HibernateException, IOException {
transaction = session.beginTransaction();
User user = new User();
user.setId(2L);
user.setName("smith");
String[] roles = {"admin", "employee"};
user.setRoles(roles);
session.persist(user);
session.flush();
session.clear();
transaction.commit();
User userDBObj = session.find(User.class, 2L);
assertEquals("smith", userDBObj.getName());
}Also, we can fetch the User record that contains roles in the form of the PostgreSQL text array:
@Test
public void givenArrayMapping_whenQueried_thenReturnArraysFromDB()
throws HibernateException, IOException {
User user = session.find(User.class, 2L);
assertEquals("smith", user.getName());
assertEquals("admin", user.getRoles()[0]);
assertEquals("employee", user.getRoles()[1]);
}4.3. CustomIntegerArrayType
Similarly, we can create a custom type for various array types supported by PostgreSQL. For instance, let's create the CustomIntegerArrayType to map the PostgreSQL int array:
public class CustomIntegerArrayType implements UserType {
@Override
public int[] sqlTypes() {
return new int[]{Types.ARRAY};
}
@Override
public Class returnedClass() {
return Integer[].class;
}
@Override
public Object nullSafeGet(ResultSet rs, String[] names, SharedSessionContractImplementor session, Object owner)
throws HibernateException, SQLException {
Array array = rs.getArray(names[0]);
return array != null ? array.getArray() : null;
}
@Override
public void nullSafeSet(PreparedStatement st, Object value, int index, SharedSessionContractImplementor session)
throws HibernateException, SQLException {
if (value != null && st != null) {
Array array = session.connection().createArrayOf("int", (Integer[])value);
st.setArray(index, array);
} else {
st.setNull(index, sqlTypes()[0]);
}
}
//implement equals, hashCode, and other methods
}
Similar to what we noticed in the CustomStringArrayType class, the return type of the returnedClass method is the Integer array. Also, the implementation of the nullSafeSet method creates an array of PostgreSQL type int. Last, we can use the CustomIntegerArrayType class to map Integer array locations to the PostgreSQL int array:
@Entity
public class User {
//...
@Column(columnDefinition = "int[]")
@Type(type = "com.baeldung.hibernate.arraymapping.CustomIntegerArrayType")
private Integer[] locations;
//getters and setters
}
5. Mapping Array With hibernate-types
On the other hand, instead of implementing a custom type for each type like String, Integer, and Long, we can use the hibernate-types library developed by a renowned Hibernate expert, Vlad Mihalcea.
5.1. Setup
First, we'll add the latest hibernate-types-52 Maven dependency to our pom.xml:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-52</artifactId>
<version>2.10.4</version>
</dependency>5.2. User Entity
Next, we'll add the integration code in the User entity to map the String array phoneNumbers:
@TypeDefs({
@TypeDef(
name = "string-array",
typeClass = StringArrayType.class
)
})
@Entity
public class User {
//...
@Type(type = "string-array")
@Column(
name = "phone_numbers",
columnDefinition = "text[]"
)
private String[] phoneNumbers;
//getters and setters
}Here, similar to the custom type CustomStringArrayType, we've used the StringArrayType class, provided by the hibernate-types library, as a mapper for the String array. Similarly, we can find a few other handy mappers like DateArrayType, EnumArrayType, and DoubleArrayType in the library.
5.3. Unit Test
That's it! We're ready with the array mapping using the hibernate-types library. Let's update the already discussed unit test to verify the insert operation:
@Test
public void givenArrayMapping_whenArraysAreInserted_thenPersistInDB()
throws HibernateException, IOException {
transaction = session.beginTransaction();
User user = new User();
user.setId(2L);
user.setName("smith");
String[] roles = {"admin", "employee"};
user.setRoles(roles);
String[] phoneNumbers = {"7000000000", "8000000000"};
user.setPhoneNumbers(phoneNumbers);
session.persist(user);
session.flush();
session.clear();
transaction.commit();
}Similarly, we can verify the read operation:
@Test
public void givenArrayMapping_whenQueried_thenReturnArraysFromDB()
throws HibernateException, IOException {
User user = session.find(User.class, 2L);
assertEquals("smith", user.getName());
assertEquals("admin", user.getRoles()[0]);
assertEquals("employee", user.getRoles()[1]);
assertEquals("7000000000", user.getPhoneNumbers()[0]);
assertEquals("8000000000", user.getPhoneNumbers()[1]);
}6. Conclusion
In this article, we explored mapping the PostgreSQL array with Hibernate. First, we created a custom type to map the String array using Hibernate's UserType class. Then, we used the custom type to map the PostgreSQL text array with Hibernate. Last, we used the hibernate-types library to map the PostgreSQL array. As usual, the source code is available over on GitHub.
The post Mapping PostgreSQL Array With Hibernate first appeared on Baeldung. ↧
↧
Fixing the NoSuchMethodError JUnit Error
1. Overview
In this article, we're going to learn how to fix the NoSuchMethodError and NoClassDefFoundError JUnit errors. Such problems usually occur when we have two different JUnit versions in our classpath. This situation may occur, for example, when the project's JUnit version is different from the one that is used in a Maven or Gradle dependency.
2. JUnit's NoClassDefFoundError in a Spring Project
Let's say that we have a Maven project using Spring Boot 2.1.2 and the Spring Boot Starter Test dependency. With such dependency, we can write and run automated tests using JUnit 5.3.2, which is the JUnit version of the spring-boot-test dependency.
Now, suppose we'll continue using Spring Boot 2.1.2. However, we want to use JUnit 5.7.1. A possible approach would be the inclusion of the junit-jupiter-api, junit-jupiter-params, junit-jupiter-engine, and junit-platform-launcher dependencies in our pom.xml file:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.7.1</version>
<scope>test</scope>
</dependency>
...Nevertheless, in this case, we'll get a NoClassDefFoundError when we run our tests:
[ERROR] java.lang.NoClassDefFoundError: org/junit/platform/commons/util/ClassNamePatternFilterUtilsInstead of the NoClassDefFoundError, a NoSuchMethodError will occur if we migrate to JUnit 5.4.0.
3. Understanding and Fixing the Error
As illustrated in the previous section, we ended up with a NoClassDefFoundError when we tried to migrate our JUnit version from 5.3.2 to 5.7.1.
The error occurred because our classpath ended up having two different versions of JUnit. Therefore, our project was compiled with a newer version of JUnit (5.7.1) but found an older version (5.3.2) at runtime. As a result, the JUnit launcher tried to use a class that is not available in the older version of JUnit.
Next, we're going to learn different solutions for fixing this error.
3.1. Overriding the JUnit Version of Spring
An effective approach for fixing the error in our example is to override the JUnit version managed by Spring:
<properties>
<junit-jupiter.version>5.7.1</junit-jupiter.version>
</properties>Now, we can also replace our JUnit dependencies with the following one:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
</dependency>This single dependency will include junit-jupiter-api, junit-jupiter-params, and junit-jupiter-engine. The junit-platform-launcher dependency is usually necessary only when we need to run our JUnit tests programmatically.
Similarly, we can also override the managed version in a Gradle project:
ext['junit-jupiter.version'] = '5.7.1'3.2. Solution for Any Project
In the previous section, we learned how to fix the NoSuchMethodError and NoClassDefFoundError JUnit errors in a Spring project, which is the most common scenario. However, if these errors are happening and our project does not use Spring, we can try to fix the collision of dependencies in Maven.
Similar to what happened in our example with Spring, a project may have multiple versions of JUnit due to transitive dependencies. For such a scenario, we have a detailed tutorial on how to resolve the collisions in Maven.
4. Conclusion
In this tutorial, we reproduced and learned how to fix the NoSuchMethodError and NoClassDefFoundError JUnit errors. The code snippets, as always, can be found over on GitHub. Please notice that, in this source code example, we override the JUnit version in the pom.xml file of the parent project.
The post Fixing the NoSuchMethodError JUnit Error first appeared on Baeldung. ↧
Getting the Java Version at Runtime
1. Overview
Sometimes when programming in Java, it may be helpful to programmatically find the version of Java that we're using. In this tutorial, we'll look at a few ways to get the Java version.
2. Java Version Naming Convention
Up until Java 9, the Java version did not follow the Semantic Versioning. The format was 1.X.Y_Z. X and Y indicate major and minor versions, respectively. Z is used to indicate an update release and separated by underscore “_”. For example, 1.8.0_181. For Java 9 and beyond, the Java version follows the Semantic Versioning. The Semantic Versioning uses the X.Y.Z format. It refers to major, minor, and patch. For example, 11.0.7.
3. Getting Java Version
3.1. Using System.getProperty
A system property is a key-value pair that the Java runtime provides. The java.version is a system property that provides the Java version. Let's define a method for getting the version:
public void givenJava_whenUsingSystemProp_thenGetVersion() {
int expectedVersion = 8;
String[] versionElements = System.getProperty("java.version").split("\\.");
int discard = Integer.parseInt(versionElements[0]);
int version;
if (discard == 1) {
version = Integer.parseInt(versionElements[1]);
} else {
version = discard;
}
Assertions.assertThat(version).isEqualTo(expectedVersion);
}To support both Java version formats, we should check the first number until the dot.
3.2. Using Apache Commons Lang 3
A second approach for getting the Java version is via the Apache Commons Lang 3 library. We first need to add the commons-lang3 Maven dependency to our pom.xml file:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>We'll use the SystemUtils class to obtain information about the Java platform. Let's define a method for this purpose:
public void givenJava_whenUsingCommonsLang_thenGetVersion() {
int expectedVersion = 8;
String[] versionElements = SystemUtils.JAVA_SPECIFICATION_VERSION.split("\\.");
int discard = Integer.parseInt(versionElements[0]);
int version;
if (discard == 1) {
version = Integer.parseInt(versionElements[1]);
} else {
version = discard;
}
Assertions.assertThat(version).isEqualTo(expectedVersion);
}We are using the JAVA_SPECIFICATION_VERSION that is intended to mirror available values from the java.specification.version System property.
3.3. Using Runtime.version()
In Java 9 and above, we can use the Runtime.version() to get version information. Let's define a method for this purpose:
public void givenJava_whenUsingRuntime_thenGetVersion(){
String expectedVersion = "11";
Runtime.Version runtimeVersion = Runtime.version();
String version = String.valueOf(runtimeVersion.version().get(0));
Assertions.assertThat(version).isEqualTo(expectedVersion);
}4. Conclusion
In this article, we describe a few ways to obtain the Java version. As usual, all code samples used in this tutorial are available over on GitHub.
The post Getting the Java Version at Runtime first appeared on Baeldung. ↧
Using an Interface vs. Abstract Class in Java
1. Introduction
Abstraction is one of the Object-Oriented programming key features. It allows us to hide the implementation complexities just by providing functionalities via simpler interfaces. In Java, we achieve abstraction by using either an interface or abstract class.
In this article, we'll discuss when to use an interface and when to use an abstract class while designing applications. Also, the key differences between them and which one to choose based on what we're trying to achieve.
2. Class vs. Interface
First, let's look at the differences between a normal concrete class vs. an interface.
A class is a user-defined type that acts as a blueprint for object creation. It can have properties and methods that represent the states and behaviors of an object, respectively.
An interface is also a user-defined type that is syntactically similar to a class. It can have a collection of field constants and method signatures that will be overridden by interface implementing classes.
In addition to these, Java 8 new features support static and default methods in interfaces to support backward compatibility. Methods in an interface are implicitly abstract if they are not static or default and all are public.
3. Interface vs. Abstract Class
An abstract class is nothing but a class that is declared using the abstract keyword. It also allows us to declare method signatures using the abstract keyword (abstract method) and forces its subclasses to implement all the declared methods. Suppose if a class has a method that is abstract, then the class itself must be abstract.
Abstract classes have no restrictions on field and method modifiers, while in an interface, all are public by default. We can have instance and static initialization blocks in an abstract class, whereas we can never have them in the interface. Abstract classes may also have constructors which will get executed during the child object's instantiation.
Java 8 introduced functional interfaces, an interface with a restriction of no more than one declared abstract method. Any interface with a single abstract method other than static and default methods is considered a functional interface. We can use this feature to restrict the number of abstract methods to be declared. While in abstract classes, we can never have this restriction on the number of abstract methods declaration.
Abstract classes are analogous to interfaces in some ways:
- We can't instantiate either of them. i.e., we cannot use the statement new TypeName() directly to instantiate an object. If we used the aforementioned statement, we have to override all the methods using an anonymous class
- They both might contain a set of methods declared and defined with or without their implementation. i.e., static & default methods(defined) in an interface, instance methods(defined) in abstract class, abstract methods(declared) in both of them
4. When to Use An Interface
Let's look at some scenarios when one should go with an interface:
- If the problem needs to be solved using multiple inheritance and is composed of different class hierarchies
- When unrelated classes implement our interface. For example, Comparable provides the compareTo() method that can be overridden to compare two objects
- When application functionalities have to be defined as a contract, but not concerned about who implements the behavior. i.e., third-party vendors need to implement it fully
Consider using the interface when our problem makes the statement “A is capable of [doing this]”. For example, “Clonable is capable of cloning an object”, “Drawable is capable of drawing a shape”, etc.
Let us consider an example that makes use of an interface:
public interface Sender {
void send(File fileToBeSent);
}public class ImageSender implements Sender {
@Override
public void send(File fileToBeSent) {
// image sending implementation code.
}
}Here, Sender is an interface with a method send(). Hence, “Sender is capable of sending a file” we implemented it as an interface. ImageSender implements the interface for sending an image to the target. We can further use the above interface to implement VideoSender, DocumentSender to accomplish various jobs.
Consider a unit test case the makes use of the above interface and its implemented class:
@Test
void givenImageUploaded_whenButtonClicked_thenSendImage() {
File imageFile = new File(IMAGE_FILE_PATH);
Sender sender = new ImageSender();
sender.send(imageFile);
}5. When to Use an Abstract Class
Now, let's see some scenarios when one should use the abstract class:
- When trying to use the inheritance concept in code (share code among many related classes), by providing common base class methods that the subclasses override
- If we have specified requirements and only partial implementation details
- While classes that extend abstract classes have several common fields or methods (that require non-public modifiers)
- If one wants to have non-final or non-static methods to modify the states of an object
Consider using abstract classes and inheritance when our problem makes the evidence “A is a B”. For example, “Dog is an Animal”, “Lamborghini is a Car”, etc.
Let's look at an example that uses the abstract class:
public abstract class Vehicle {
protected abstract void start();
protected abstract void stop();
protected abstract void drive();
protected abstract void changeGear();
protected abstract void reverse();
// standard getters and setters
}
public class Car extends Vehicle {
@Override
protected void start() {
// code implementation details on starting a car.
}
@Override
protected void stop() {
// code implementation details on stopping a car.
}
@Override
protected void drive() {
// code implementation details on start driving a car.
}
@Override
protected void changeGear() {
// code implementation details on changing the car gear.
}
@Override
protected void reverse() {
// code implementation details on reverse driving a car.
}
}In the above code, the Vehicle class has been defined as abstract along with other abstract methods. It provides generic operations of any real-world vehicle and also has several common functionalities. The Car class, which extends the Vehicle class, overrides all the methods by providing the car's implementation details (“Car is a Vehicle”).
Hence, we defined the Vehicle class as abstract in which the functionalities can be implemented by any individual real vehicle like cars and buses. For example, in the real world, starting a car and bus is never going to be the same (each of them needs different implementation details).
Now, let's consider a simple unit test that makes use of the above code:
@Test
void givenVehicle_whenNeedToDrive_thenStart() {
Vehicle car = new Car("BMW");
car.start();
car.drive();
car.changeGear();
car.stop();
}6. Conclusion
This article discussed the overview of interfaces and abstract classes and the key differences between them. Also, we examined when to use each of them in our work to accomplish writing flexible and clean code.
The complete source code for the examples given in this article is available over on GitHub.
The post Using an Interface vs. Abstract Class in Java first appeared on Baeldung. ↧
Java Weekly, Issue 385
1. Spring and Java
>> Networking I/O with Virtual Threads – Under the hood [inside.java]
Scalability meets a good programming paradigm – taking advantage of non-blocking sockets and continuations in Project Loom!
>> Teeing, a hidden gem in the Java API [blog.frankel.ch]
Collector composition – using teeing collector to compose two downstream collectors in Stream API.
>> Working with AWS SQS and Spring Cloud [reflectoring.io]
A practical take on how to integrate Spring Cloud with Amazon SQS service.
Also worth reading:
- >> Top 10 Plugins for IntelliJ IDEA You Don’t Want to Miss [blog.jetbrains.com]
- >> Kotlin 1.5 Gets Support for Java 15 Features and a New JVM Compiler [infoq.com]
- >> Json Patch and Json Merge Patch in Java [java-allandsundry.com]
- >> Easily Debug Java Microservices Running on Kubernetes with IntelliJ IDEA [blog.jetbrains.com]
- >> Java 8 IntStream Examples – range, rangeClosed, sum and sorted [javarevisited.com]
Webinars and presentations:
- >> Inside Java Newscast #4 [inside.java]
- >> Upgrade to Java 16 or 17 [infoq.com]
- >> A Bootiful Podcast: Friend, fellow Spring Developer Advocate, Kotlin Google Developer Expert, and Java Champion, Mark Heckler [spring.io]
- >> Things I’ve automated on my development system (Video) [blog.sebastian-daschner.com]
Time to upgrade:
- >> Spring Framework 5.3.7 and 5.2.15 available now [spring.io]
- >> Spring HATEOAS 1.2.6 and 1.3.1 released [spring.io]
- >> Spring Authorization Server 0.1.1 available now [spring.io]
- >> Hibernate ORM 5.5.0.Beta1 released [in.relation.to]
- >> JReleaser 0.3.0 has been released! [andresalmiray.com]
2. Technical & Musings
>> Diving Deep on S3 Consistency [allthingsdistributed.com]
The road to implementing strong consistency in S3 while maintaining cache coherency, high availability, and correctness at the same time!
>>Book Notes: Measure What Matters [reflectoring.io]
An entertaining read on success stories that used OKRs to achieve objectives and goals!
Also worth reading:
- >> Achieving observability in async workflows [netflixtechblog.com]
- >> Securing Data in AWS [reflectoring.io]
- >> How to Get an RDBMS Server Version with SQL [blog.jooq.org]
- >> SQL Server Foreign Key Locking [vladmihalcea.com]
- >> The Syslog Hell [techblog.bozho.net]
- >> How to use CloudFront Trusted Key Groups parameter and the trusted_key_group Terraform resource [advancedweb.hu]
3. Comics
And my favorite Dilberts of the week:
>> Boss Isn't Fair [dilbert.com]
>> Work From Home Or Office [dilbert.com]
>> Ceo Missing [dilbert.com]
4. Pick of the Week
Using Continuous Integration in your development process is, simply put, a must.
IntelliJ IDEA has already basically given superpowers to Java developers. Now JetBrains is taking the next logical step and focusing on the whole team with TeamCity Cloud.
This is a new managed continuous integration service – you can read more about it here:
>> Introducing TeamCity Cloud – A Managed CI/CD Service by JetBrains
Or you can simply try it out with the free trial here.
The post Java Weekly, Issue 385 first appeared on Baeldung. ↧
↧
HTTP PUT vs. POST in REST API
1. Overview
In this tutorial, we're going to take a quick look at two important HTTP methods – PUT and POST – that are frequently used within the REST architecture. It's no secret that developers sometimes struggle to choose between these two methods while designing a RESTful web service. Therefore, we'll address this issue with a simple implementation of a RESTful application in Spring Boot.
2. PUT vs POST Dilemma
In a typical REST architecture, a client sends requests in the form of HTTP methods to the server to create, retrieve, modify, or destroy resources. While both PUT and POST can be used to create resources, there are significant differences between them in terms of their intended applications.
According to the RFC 2616 standard, the POST method should be used to request the server to accept the enclosed entity as a subordinate of the existing resource identified by the Request-URI. This means the POST method call will create a child resource under a collection of resources.
On the other hand, the PUT method should be used to request the server to store the enclosed entity under the provided Request-URI. If the Request-URI points to an existing resource on the server, the supplied entity will be considered a modified version of the existing resource. Therefore, the PUT method call will either create a new resource or update an existing one.
Another important difference between the methods is that PUT is an idempotent method while POST is not. For instance, calling the PUT method multiple times will either create or update the same resource. On the contrary, multiple POST requests will lead to the creation of the same resource multiple times.
3. Sample Application
To demonstrate the difference between PUT and POST, we're going to create a simple RESTful web application using Spring Boot. The application will store the names and addresses of people.
3.1. Maven Dependencies
To begin with, we need to include the dependencies for Spring Web, Spring Data JPA, and the in-memory H2 database in our pom.xml file:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>3.2. Domain Entity and Repository Interface
Let's start by creating the domain object first. For the address book, let's define an Entity class called Address that we'll use to store address information of individuals. For the sake of simplicity, we're going to use three fields – name, city, and postalCode – for our Address entity:
@Entity
public class Address {
private @Id @GeneratedValue Long id;
private String name;
private String city;
private String postalCode;
// constructors, getters, and setters
}The next step is to access the data from the database. For simplicity, we'll leverage Spring Data JPA's JpaRepository. This will allow us to perform CRUD functionalities on the data without writing any additional code:
public interface AddressRepository extends JpaRepository<Address, Long> {
}3.3. REST Controller
Finally, we need to define the API endpoints for our application. We'll create a RestController that will consume HTTP requests from the client and send back the appropriate response.
Here, we'll define a @PostMapping for creating new addresses and storing them in the database and a @PutMapping to update the content of the address book based on the request URI. If the URI is not found, it will create a new address and store it in the database:
@RestController
public class AddressController {
private final AddressRepository repository;
AddressController(AddressRepository repository) {
this.repository = repository;
}
@PostMapping("/addresses")
Address createNewAddress(@RequestBody Address newAddress) {
return repository.save(newAddress);
}
@PutMapping("/addresses/{id}")
Address replaceEmployee(@RequestBody Address newAddress, @PathVariable Long id) {
return repository.findById(id)
.map(address -> {
address.setCity(newAddress.getCity());
address.setPin(newAddress.getPostalCode());
return repository.save(address);
})
.orElseGet(() -> {
return repository.save(newAddress);
});
}
//additional methods omitted
}3.4. cURL Requests
Now we can test our developed application by using cURL to send sample HTTP requests to our server.
For creating a new address, we'll enclose the data in JSON format and send it through a POST request:
curl -X POST --header 'Content-Type: application/json' \
-d '{ "name": "John Doe", "city": "Berlin", "postalCode": "10585" }' \
http://localhost:8080/addressesNow, let's update the content of the address we created. We'll send a PUT request using the id of that address in the URL. In this example, we will update the city and the postalCode section of the address we just created — we'll suppose it was saved with id=1:
curl -X PUT --header 'Content-Type: application/json' \
-d '{ "name": "John Doe", "city": "Frankfurt", "postalCode": "60306" }' \
http://localhost:8080/addresses/14. Conclusion
In this tutorial, we learned about the conceptual differences between the HTTP methods PUT and POST. Additionally, we also learned how the methods can be implemented using the Spring Boot framework for developing RESTful applications.
In conclusion, we should use the POST method to create a new resource and the PUT method to update an existing resource. As always, the code for this tutorial is available over on GitHub.
The post HTTP PUT vs. POST in REST API first appeared on Baeldung. ↧
Java Objects.hash() vs Objects.hashCode()
1. Introduction
A hashcode is a numeric representation of the contents of an object.
In Java, there are a few different methods we can use to get a hashcode for an object:
- Object.hashCode()
- Objects.hashCode() – introduced in Java 7
- Objects.hash() – introduced in Java 7
In this tutorial, we're going to look at each of those methods. First, we'll start with definitions and basic examples. After we have the basic usage down, we'll dig into the differences between them and the ramifications those differences may have.
2. Basic Usage
2.1. Object.hashCode()
We can use the Object.hashCode() method to retrieve the hashcode of an object. It's very similar to Objects.hashCode() except that we can't use it if our object is null.
With that said, let's call Object.hashCode() on two identical Double objects:
Double valueOne = Double.valueOf(1.0012);
Double valueTwo = Double.valueOf(1.0012);
int hashCode1 = valueOne.hashCode();
int hashCode2 = valueTwo.hashCode();
assertEquals(hashCode1, hashCode2);As expected, we receive identical hashcodes.
In contrast, now let's call Object.hashCode() on a null object with the expectation that a NullPointerException is thrown:
Double value = null;
value.hashCode();2.2. Objects.hashCode()
Objects.hashCode() is a null-safe method we can use to get the hashcode of an object. Hashcodes are necessary for hash tables and the proper implementation of equals().
The general contract for a hashcode as specified in the JavaDoc is:
- That the returned integer be the same each time it's called for an unchanged object during the same execution of the application
- For two objects that are equal according to their equals() method, return the same hashcode
Although it's not a requirement, distinct objects return different hashcodes as much as possible.
First, let's call Objects.hashCode() on two identical strings:
String stringOne = "test";
String stringTwo = "test";
int hashCode1 = Objects.hashCode(stringOne);
int hashCode2 = Objects.hashCode(stringTwo);
assertEquals(hashCode1, hashCode2);Now, we expect the returned hashcodes to be identical.
On the other hand, if we provide a null to Objects.hashCode(), we'll get zero back:
String nullString = null;
int hashCode = Objects.hashCode(nullString);
assertEquals(0, hashCode);2.3. Objects.hash()
Unlike Objects.hashCode(), which takes only a single object, Objects.hash() can take one or more objects and provides a hashcode for them. Under the hood, the hash() method works by putting the supplied objects into an array and calling Arrays.hashCode() on them. If we provide only one object to the Objects.hash() method, we can't expect the same results as calling Objects.hashCode() on the object.
First, let's call Objects.hash() with two pairs of identical strings:
String strOne = "one";
String strTwo = "two";
String strOne2 = "one";
String strTwo2 = "two";
int hashCode1 = Objects.hash(strOne, strTwo);
int hashCode2 = Objects.hash(strOne2, strTwo2);
assertEquals(hashCode1, hashCode2);Next, let's call Objects.hash() and Objects.hashCode() with a single string:
String testString = "test string";
int hashCode1 = Objects.hash(testString);
int hashCode2 = Objects.hashCode(testString);
assertNotEquals(hashCode1, hashCode2);As expected, the two hashcodes returned do not match.
3. Key Differences
In the previous section, we hit on the key difference between Objects.hash() and Objects.hashCode(). Now, let's dig into it a little deeper so we can understand some of the ramifications.
If we need to override one of our class's equals() method, it's critical that we properly override hashCode() as well.
Let's start by creating a simple Player class for our example:
public class Player {
private String firstName;
private String lastName;
private String position;
// Standard getters/setters
}3.1. Multiple Field Hashcode Implementation
Let's imagine that our Player class is considered unique across all three fields: firstName, lastName, and position.
With that said, let's look at how we might have implemented Player.hashCode() prior to Java 7:
@Override
public int hashCode() {
int result = 17;
result = 31 * result + firstName != null ? firstName.hashCode() : 0;
result = 31 * result + lastName != null ? lastName.hashCode() : 0;
result = 31 * result + position != null ? position.hashCode() : 0;
return result;
}Because both Objects.hashCode() and Objects.hash() were introduced with Java 7, we have to explicitly check for null before calling Object.hashCode() on each field.
Let's confirm that we can both call hashCode() twice on the same object and get the same result and that we can call it on identical objects and get the same result:
Player player = new Player("Eduardo", "Rodriguez", "Pitcher");
Player indenticalPlayer = new Player("Eduardo", "Rodriguez", "Pitcher");
int hashCode1 = player.hashCode();
int hashCode2 = player.hashCode();
int hashCode3 = indenticalPlayer.hashCode();
assertEquals(hashCode1, hashCode2);
assertEquals(hashCode1, hashCode3);Next, let's look at how we can shorten that a bit by taking advantage of null-safety we get with Objects.hashCode():
int result = 17;
result = 31 * result + Objects.hashCode(firstName);
result = 31 * result + Objects.hashCode(lastName);
result = 31 * result + Objects.hashCode(position);
return result;If we run the same unit test, we should expect the same results.
Because our class relies on multiple fields to determine equality, let's go a step further and use Objects.hash() to make our hashCode() method very succinct:
return Objects.hash(firstName, lastName, position);After this update, we should be able to successfully run our unit test again.
3.2. Objects.hash() Details
Under the hood, when we call Objects.hash(), the values are placed in an array, and then Arrays.hashCode() is called on the array.
With that said, let's create a Player and compare its hashcode to Arrays.hashCode() with the values we use:
@Test
public void whenCallingHashCodeAndArraysHashCode_thenSameHashCodeReturned() {
Player player = new Player("Bobby", "Dalbec", "First Base");
int hashcode1 = player.hashCode();
String[] playerInfo = {"Bobby", "Dalbec", "First Base"};
int hashcode2 = Arrays.hashCode(playerInfo);
assertEquals(hashcode1, hashcode2);
}We created a Player and then created a String[]. Then we called hashCode() on the Player and used Arrays.hashCode() on the array and received the same hashcode.
4. Conclusion
In this article, we learned how and when to use the Object.hashCode(), Objects.hashCode() and Objects.hash(). Additionally, we looked into the differences between them.
As a review, let's quickly summarize their usage:
- Object.hashCode(): use to get the hashcode of a single, non-null object
- Objects.hashCode(): use to get the hashcode of a single object that might be null
- Objects.hash(): use to get a hashcode for multiple objects
As always, the example code is available over on GitHub.
The post Java Objects.hash() vs Objects.hashCode() first appeared on Baeldung. ↧
Copying Files With Maven
1. Introduction
Maven is a build automation tool that allows Java developers to manage a project's build, reporting, and documentation from a centralized location – the POM (Project Object Model).
When we build a Java project, we often require arbitrary project resources to be copied to a specific location in the output build – we can achieve this with Maven through the use of several different plugins.
In this tutorial, we'll build a Java project and copy a specific file to a destination in the build output, using:
2. Using the Maven Resources Plugin
The maven-resources-plugin handles the copying of project resources to an output directory.
Let's start by adding the plugin to our pom.xml:
<project>
...
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.2.0</version>
</plugin>
...
</plugins>
</pluginManagement>
<!-- To use the plugin goals in your POM or parent POM -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.2.0</version>
</plugin>
...
</plugins>
</build>
...
</project>Then, let's create a folder in the project root called source-files. It'll contain a text file that we want to copy: foo.txt. We'll then add a configuration element to the maven-resources-plugin to copy this file to target/destination-folder:
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
<executions>
<execution>
<id>copy-resource-one</id>
<phase>generate-sources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${basedir}/target/destination-folder</outputDirectory>
<resources>
<resource>
<directory>source-files</directory>
<includes>
<include>foo.txt</include>
</includes>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>After building the project, we can find the foo.txt in the target/destination-folder.
3. Using the Maven Antrun Plugin
The maven-antrun-plugin provides the ability to run Ant tasks from within Maven. We'll use it here to specify an Ant task that copies a source file to a destination.
The plugin is defined in the pom.xml as follows:
<project>
[...]
<build>
<plugins>
<plugin>
<artifactId>maven-antrun-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>
<phase>generate-sources</phase>
</phase>
<configuration>
<target>
<!-- Place any Ant task here. -->
</target>
</configuration>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>We'll perform the same example as above: copying source-files/foo.txt to target/destination-folder/foo.txt – we'll achieve this by defining an Ant task to perform the copy:
<configuration>
<target>
<mkdir dir="${basedir}/target/destination-folder" />
<copy todir="${basedir}/target/destination-folder">
<fileset dir="${basedir}/source-files" includes="foo.txt" />
</copy>
</target>
</configuration>After building the project we'll find foo.txt in target/destination-folder.
4. Using the Copy Rename Maven Plugin
The copy-rename-maven-plugin helps copying files or renaming files/directories during the Maven build lifecycle.
The plugin can be installed by adding the following entry to our pom.xml:
<project>
...
<build>
<plugins>
<plugin>
<groupId>com.coderplus.maven.plugins</groupId>
<artifactId>copy-rename-maven-plugin</artifactId>
<version>1.0</version>
<executions>
<execution>
<id>copy-file</id>
<phase>generate-sources</phase>
<goals>
<goal>copy</goal>
</goals>
<configuration>
<!-- Place config here -->
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
We'll now add some config to perform the copy: source-files/foo.txt to target/destination-folder/foo.txt:
<configuration>
<sourceFile>source-files/foo.txt</sourceFile>
<destinationFile>target/destination-folder/foo.txt</destinationFile>
</configuration>Upon building the project, we'll see foo.txt in the target/destination-folder.
5. Conclusion
We've successfully copied a source file to a destination using three different Maven plugins. Each one operates slightly differently, and while we've covered copying a single file here, the plugins are capable of copying multiple files and in some instances, entire directories.
Our other articles plus the official documentation for each of the plugins go into further detail about how to perform more complicated operations.
The source code for these examples can be found over on GitHub.
↧
Docker Guide




↧
↧
When to Use a Parallel Stream in Java
1. Overview
Java 8 introduced the Stream API that makes it easy to iterate over collections as streams of data. It's also very easy to create streams that execute in parallel and make use of multiple processor cores. One might think that it's always faster to divide the work on more cores. However, many times, that is not the case.
In this tutorial, we'll explore the differences between sequential and parallel streams. We'll look at the default fork-join pool used by the parallel streams. We'll consider the performance implications of using a parallel stream, including memory locality and splitting/merging costs. Finally, we'll recommend when it makes sense to covert a sequential stream into a parallel one.
2. Streams in Java
A stream in Java is simply a wrapper around a data source, allowing us to perform bulk operations on the data in a convenient way. It doesn't store data or make any changes to the underlying data source. Rather, it adds support for functional-style operations on data pipelines.
2.1. Sequential Streams
By default, any stream operation in Java is processed sequentially, unless explicitly specified as parallel. Sequential streams use a single thread to process the pipeline:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.stream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);The output of this sequential stream is predictable. The list elements will always be printed in an ordered sequence:
1 main
2 main
3 main
4 main2.2. Parallel Streams
Any stream in Java can easily be transformed from sequential to parallel. We can achieve this by adding the parallel method to a sequential stream or by creating a stream using the parallelStream method of a collection:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);Parallel streams enable us to execute code in parallel on separate cores. The final result is the combination of each individual outcome. However, the order of execution is out of our control. It may change every time we run the program:
4 ForkJoinPool.commonPool-worker-3
2 ForkJoinPool.commonPool-worker-5
1 ForkJoinPool.commonPool-worker-7
3 main3. Fork-Join Framework
Parallel streams make use of the fork-join framework and its common pool of worker threads. The fork-join framework was added to java.util.concurrent in Java 7 to handle task management between multiple threads.
3.1. Splitting Source
The fork-join framework is in charge of splitting the source data between worker threads and handling callback on task completion.
Let's take a look at an example of calculating a sum of integers in parallel. We'll make use of the reduce method and add five to the starting sum, instead of starting from zero:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(5, Integer::sum);
assertThat(sum).isNotEqualTo(15);In a sequential stream, the result of this operation would be 15. However, since the reduce operation is handled in parallel, the number five actually gets added up in every worker thread:
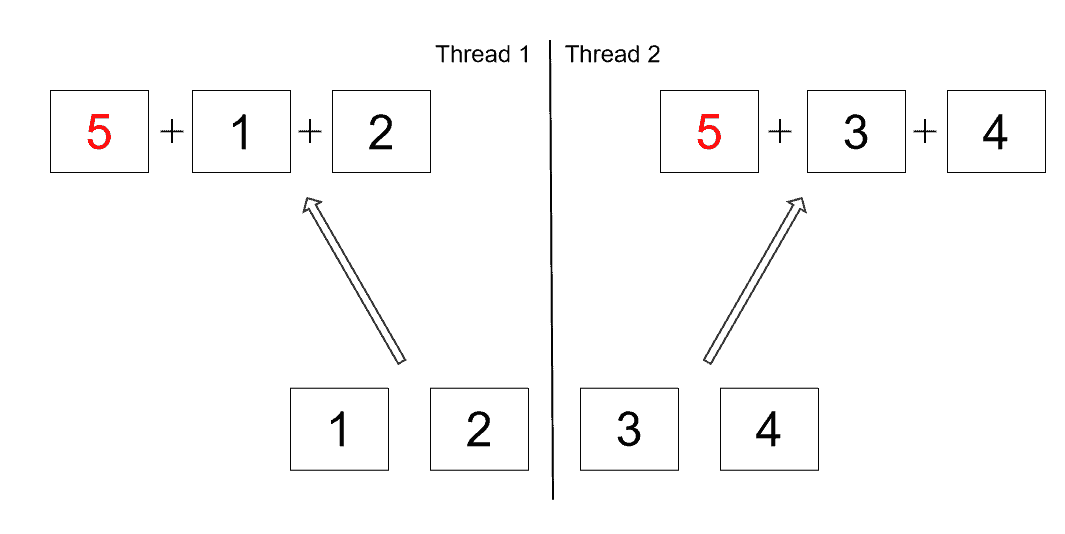
The actual result might differ depending on the number of threads used in the common fork-join pool. In order to fix this issue, the number five should be added outside of the parallel stream:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(0, Integer::sum) + 5;
assertThat(sum).isEqualTo(15);Therefore, we need to be careful about which operations can be run in parallel.
3.2. Common Thread Pool
The number of threads in the common pool is equal to the number of processor cores. However, the API allows us to specify the number of threads it will use by passing a JVM parameter:
-D java.util.concurrent.ForkJoinPool.common.parallelism=4However, this is a global setting and it will affect all parallel streams and any other fork-join tasks that use the common pool. We strongly suggest that this parameter is not modified unless we have a very good reason for doing so.
3.3. Custom Thread Pool
Besides in the default, common thread pool, it's also possible to run a parallel stream in a custom thread pool:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
ForkJoinPool customThreadPool = new ForkJoinPool(4);
int sum = customThreadPool.submit(
() -> listOfNumbers.parallelStream().reduce(0, Integer::sum)).get();
customThreadPool.shutdown();
assertThat(sum).isEqualTo(10);Then again, using the common thread pool is recommended by Oracle. We should have a very good reason for running parallel streams in custom thread pools.
4. Performance Implications
Parallel processing may be beneficial to fully utilize multiple cores. However, we also need to consider the overhead of managing multiple threads, memory locality, splitting the source, and merging the results.
4.1. The Overhead
Let's take a look at an example integer stream. We'll run a benchmark on a sequential and parallel reduction operation:
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum);
IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum);On this simple sum reduction, converting a sequential stream into a parallel one resulted in worse performance:
Benchmark Mode Cnt Score Error Units
SplittingCosts.sourceSplittingIntStreamParallel avgt 25 35476,283 ± 204,446 ns/op
SplittingCosts.sourceSplittingIntStreamSequential avgt 25 68,274 ± 0,963 ns/opThe reason behind this is that sometimes the overhead of managing threads, source, and results is a more expensive operation than doing the actual work.
4.2. Splitting Costs
Splitting the data source evenly is a necessary cost to enable parallel execution. However, some data sources split better than others. Let's demonstrate this on an example using an ArrayList and a LinkedList:
private static final List<Integer> arrayListOfNumbers = new ArrayList<>();
private static final List<Integer> linkedListOfNumbers = new LinkedList<>();
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
arrayListOfNumbers.add(i);
linkedListOfNumbers.add(i);
});
}We'll run a benchmark on a sequential and parallel reduction operation on the two types of lists:
arrayListOfNumbers.stream().reduce(0, Integer::sum)
arrayListOfNumbers.parallelStream().reduce(0, Integer::sum);
linkedListOfNumbers.stream().reduce(0, Integer::sum);
linkedListOfNumbers.parallelStream().reduce(0, Integer::sum);Our results show that converting a sequential stream into a parallel one brings performance benefits only for an ArrayList:
Benchmark Mode Cnt Score Error Units
DifferentSourceSplitting.differentSourceArrayListParallel avgt 25 2004849,711 ± 5289,437 ns/op
DifferentSourceSplitting.differentSourceArrayListSequential avgt 25 5437923,224 ± 37398,940 ns/op
DifferentSourceSplitting.differentSourceLinkedListParallel avgt 25 13561609,611 ± 275658,633 ns/op
DifferentSourceSplitting.differentSourceLinkedListSequential avgt 25 10664918,132 ± 254251,184 ns/opThe reason behind this is that arrays can split cheaply and evenly. On the other hand, LinkedList has none of these properties. TreeMap and HashSet split better than LinkedList, but not as well as arrays.
4.3. Merging Costs
Every time we split the source for parallel computation, we also need to make sure to combine the results in the end. Let's run a benchmark on a sequential and parallel stream, with sum and grouping as different merging operations:
arrayListOfNumbers.stream().reduce(0, Integer::sum);
arrayListOfNumbers.stream().parallel().reduce(0, Integer::sum);
arrayListOfNumbers.stream().collect(Collectors.toSet());
arrayListOfNumbers.stream().parallel().collect(Collectors.toSet())Our results show that converting a sequential stream into a parallel one brings performance benefits only for the sum operation:
Benchmark Mode Cnt Score Error Units
MergingCosts.mergingCostsGroupingParallel avgt 25 135093312,675 ± 4195024,803 ns/op
MergingCosts.mergingCostsGroupingSequential avgt 25 70631711,489 ± 1517217,320 ns/op
MergingCosts.mergingCostsSumParallel avgt 25 2074483,821 ± 7520,402 ns/op
MergingCosts.mergingCostsSumSequential avgt 25 5509573,621 ± 60249,942 ns/opFor some operations, such as reduction and addition, the merge operation is really cheap. On the other hand, merge operations like grouping to sets or maps can be quite expensive.
4.4. Memory Locality
Modern computers use a sophisticated multilevel cache to keep frequently used data close to the processor. When a linear memory access pattern is detected, the hardware prefetches the next line of data under the assumption that it will probably be needed soon.
Parallelism brings performance benefits when we can keep the processor cores busy doing useful work. Since waiting for cache misses is not useful work, we need to consider the memory bandwidth as a limiting factor.
Let's demonstrate this on an example using two arrays, one using a primitive type and the other using an object data type:
private static final int[] intArray = new int[1_000_000];
private static final Integer[] integerArray = new Integer[1_000_000];
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
intArray[i-1] = i;
integerArray[i-1] = i;
});
}We'll run a benchmark on a sequential and parallel reduction operation on the two arrays:
Arrays.stream(intArray).reduce(0, Integer::sum);
Arrays.stream(intArray).parallel().reduce(0, Integer::sum);
Arrays.stream(integerArray).reduce(0, Integer::sum);
Arrays.stream(integerArray).parallel().reduce(0, Integer::sum);Our results show that converting a sequential stream into a parallel one brings slightly more performance benefits when using an array of primitives:
Benchmark Mode Cnt Score Error Units
MemoryLocalityCosts.localityIntArrayParallel avgt 25 116247,787 ± 283,150 ns/op
MemoryLocalityCosts.localityIntArraySequential avgt 25 293142,385 ± 2526,892 ns/op
MemoryLocalityCosts.localityIntegerArrayParallel avgt 25 2153732,607 ± 16956,463 ns/op
MemoryLocalityCosts.localityIntegerArraySequential avgt 25 5134866,640 ± 148283,942 ns/opAn array of primitives brings the best locality possible in Java. In general, the more pointers we have in our data structure, the more pressure we put on the memory to fetch the reference objects. This can have a negative effect on parallelization, as multiple cores simultaneously fetch the data from memory.
4.5. The NQ Model
Oracle presented a simple model that can help us determine whether parallelism can offer us a performance boost. In the NQ model, N stands for the number of source data elements, while Q represents the amount of computation performed per data element.
The larger the product of N*Q, the more likely we are to get a performance boost from parallelization. For problems with a trivially small Q, such as summing up numbers, the rule of thumb is that N should greater than 10,000. As the number of computations increases, the data size required to get a performance boost from parallelism decreases.
5. When to Use Parallel Streams
As we've shown throughout the examples, we need to be very considerate when using parallel streams. Parallelism can bring performance benefits in certain use cases. However, parallel streams cannot be considered as a magical performance booster. Thus, sequential streams should still be used as default during development.
A sequential stream can be converted to a parallel one when we have actual performance requirements. Given those requirements, we should first run a performance measurement and consider parallelism as a possible optimization strategy.
A large amount of data and many computations done per element indicate that parallelism could be a good option. On the other hand, a small amount of data, unevenly splitting sources, expensive merge operations, and poor memory locality indicate a potential problem for parallel execution.
6. Conclusion
In this article, we explored the difference between sequential and parallel streams in Java. We saw that parallel streams make use of the default fork-join pool and its worker threads.
In the examples, we saw that parallel streams do not always bring performance benefits. We considered the overhead of managing multiple threads, memory locality, splitting the source, and merging the results. We saw that arrays are a great data source for parallel execution, as they bring the best possible locality and can split cheaply and evenly.
Finally, we looked at the NQ model and recommended using parallel streams only when we have actual performance requirements.
As always, the source code is available over on GitHub.
The post When to Use a Parallel Stream in Java first appeared on Baeldung. ↧
Returning an Auto-Generated Id with JPA
1. Introduction
In this tutorial, we'll discuss how we can handle auto-generated ids with JPA. There are two key concepts that we must understand before we take a look at a practical example. Those concepts are entity life cycle and id generation strategy.
2. Entity Life Cycle and Id Generation
Each entity has four possible states during its life cycle. Those states are new, managed, detached, and removed. Our focus will be on new and managed states. During object creation, an entity is in the new state. Consequently, EntityManager is unaware of this object. Calling the persist method on EntityManager, the object transitions from new to managed state. This method requires an active transaction.
JPA defines four strategies for id generation. We can group these four strategies into two categories:
- Ids are pre-allocated and available to EntityManager before commit
- Ids are allocated after transaction commit
For more details about each id generation strategy, refer to our article, When Does JPA Set the Primary Key.
3. Problem Statement
Returning an id of an object can become a cumbersome task. We need to understand the principles mentioned in the previous section to avoid issues. Depending on JPA configuration, services may return objects with id equal to zero (or null). The focus will be on service class implementation and how different modifications can provide us with a solution.
We'll create a Maven module with the JPA specification and Hibernate as its implementation. For simplicity, we'll use H2 in-memory database.
Let's start by creating a domain entity and mapping it to a database table. For this example, we'll create a User entity with a few basic properties:
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String username;
private String password;
//...
}After the domain class, we create a UserService class. This simple service will have a reference to EntityManager and a method to save User objects to the database:
public class UserService {
EntityManager entityManager;
public UserService(EntityManager entityManager) {
this.entityManager = entityManager;
}
@Transactional
public long saveUser(User user){
entityManager.persist(user);
return user.getId();
}
}This setup is a common pitfall that we mentioned previously. We can prove that the return value of the saveUser method is zero with a test:
@Test
public void whenNewUserIsPersisted_thenEntityHasNoId() {
User user = new User();
user.setUsername("test");
user.setPassword(UUID.randomUUID().toString());
long index = service.saveUser(user);
Assert.assertEquals(0L, index);
}Let's step back and understand why this happened and how we can solve it in the following sections.
4. Manual Transaction Control
After object creation, our User entity is in the new state. The entity state changes to managed after the persist method call in the saveUser method. We remember from the recap section that the managed object gets an id after the transaction commit. Since the saveUser method is still running, the transaction created by the @Transactional annotation is not yet committed. Our managed entity gets an id when saveUser finishes execution.
One possible solution is to call the flush method on EntityManager manually. On the other hand, we can manually control transactions and guarantee that our method returns the id correctly. We can do this with EntityManager:
@Test
public void whenTransactionIsControlled_thenEntityHasId() {
User user = new User();
user.setUsername("test");
user.setPassword(UUID.randomUUID().toString());
entityManager.getTransaction().begin();
long index = service.saveUser(user);
entityManager.getTransaction().commit();
Assert.assertEquals(2L, index);
}5. Using Id Generation Strategies
Up until now, we used the second category, where id allocation occurs after the transaction commit. Pre-allocating strategies can provide us with ids before the transaction commit since they keep a handful of ids in memory. This option is not always possible to implement because not all database engines support all generation strategies. Changing the strategy to GenerationType.SEQUENCE can resolve our problem. This strategy uses a database sequence instead of an auto-incrementing column as in GenerationType.IDENTITY.
To change the strategy, we edit our domain entity class:
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
//...
}6. Conclusion
In this article, we covered id generation techniques in JPA. First, we did a little recap of the most important key aspects of id generation. Further, we covered common configurations used in JPA, along with their advantages and disadvantages. All code referenced in the article can be found over on GitHub.
The post Returning an Auto-Generated Id with JPA first appeared on Baeldung. ↧
Code Coverage with SonarQube and JaCoCo
1. Overview
SonarQube is an open-source and standalone service that provides an overview of the overall health of our source code by measuring code quality and code coverage.
In this tutorial, we'll cover the process of measuring code coverage using SonarQube and JaCoCo.
2. Description
2.1. Code Coverage
Code coverage, also called test coverage, is a measure of how much of the application’s code has been executed in testing. Essentially, it's a metric that many teams use to check the quality of their tests, as it represents the percentage of the production code that has been tested and executed.
This gives development teams reassurance that their programs have been broadly tested for bugs and should be relatively error-free.
2.2. SonarQube and JaCoCo
SonarQube inspects and evaluates everything that affects our codebase, from minor styling details to critical design errors. This enables developers to access and track code analysis data ranging from styling errors, potential bugs, and code defects, to design inefficiencies, code duplication, lack of test coverage, and excess complexity.
It also defines a quality gate, which is a set of measure-based boolean conditions. Additionally, SonarQube helps us to know whether our code is production-ready or not.
SonarQube is used in integration with JaCoCo, a free code coverage library for Java.
3. Maven Configuration
3.1. Download SonarQube
We can download SonarQube from its official website. To start SonarQube, execute the file named StartSonar.bat for a Windows machine or the file sonar.sh for Linux or macOS. The file is present in the bin directory of the extracted download.
3.2. Set Properties for SonarQube and JaCoCo
Let's start by first adding the necessary properties that define the JaCoCo version, plugin name, report path, and sonar language:
<properties>
<!-- JaCoCo Properties -->
<jacoco.version>0.8.6</jacoco.version>
<sonar.java.coveragePlugin>jacoco</sonar.java.coveragePlugin>
<sonar.dynamicAnalysis>reuseReports</sonar.dynamicAnalysis>
<sonar.jacoco.reportPath>${project.basedir}/../target/jacoco.exec</sonar.jacoco.reportPath>
<sonar.language>java</sonar.language>
</properties>The property sonar.jacoco.reportPath specifies the location where the JaCoCo report will be generated.
3.3. Dependencies and Plugins for JaCoCo
The JaCoCo Maven plugin provides access to the JaCoCo runtime agent, which records execution coverage data and creates a code coverage report.
Now, let's have a look at the dependency we'll add to our pom.xml file:
<dependency>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.6</version>
</dependency>Next, let's configure the plugin that integrates our Maven project with JaCoCo:
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<executions>
<execution>
<id>jacoco-initialize</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>jacoco-site</id>
<phase>package</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>4. SonarQube in Action
Now that we've defined the required dependency and plugin in our pom.xml file, we'll execute mvn clean install to build our project.
Then, we'll start the SonarQube server before executing the command mvn sonar:sonar. Once this command executes successfully, it will give us a link to the dashboard of our project's code coverage report:
We'll also notice that it creates a file named jacoco.exec in the target folder of the project. This file is the result of the code coverage that will be further used by SonarQube:
It also creates a dashboard in the SonarQube portal. This dashboard shows the coverage report with all the issues, security vulnerabilities, maintainability metrics, and code duplication blocks that it has found in our code:
5. Conclusion
SonarQube and JaCoCo are two tools that we can use together to make it easy to measure code coverage. They also provide an overview of the overall health of the source code by finding code duplications, bugs, and other issues in the code. This helps us to know whether our code is production-ready or not.
The complete source code for the article is available over on GitHub.
The post Code Coverage with SonarQube and JaCoCo first appeared on Baeldung. ↧