1. Overview
It is not very uncommon to come across a mysterious state while working on git. However, one day it is most likely to see “detached HEAD”.
In this tutorial, we'll discuss what is a detached HEAD is and how does it work. We’ll walk through how to navigate into and out of a detached HEAD in Git.
2. What is HEAD in Git
Git stores a record of the state of all the files in the repository when we create a commit. HEAD is another important type of reference. The purpose of HEAD is to keep track of the current point in a Git repo. In other words, HEAD answers the question, “Where am I right now?”:
$git log --oneline
a795255 (HEAD -> master) create 2nd file
5282c7c appending more info
b0e1887 creating first fileFor instance, when we use the log command, how does Git know which commit it should start displaying results from? HEAD provides the answer. When we create a new commit, its parent is indicated by where HEAD currently points to.
Because Git has such advanced version tracking features, we can go back to any point in time in our repository to view its contents.
Being able to review past commits also lets us see how a repository or a particular file or set of files has evolved over time. When we check out a commit that is not a branch, we’ll enter “detached HEAD state”. This refers to when we are viewing a commit that is not the most recent commit in a repository.
3. Example of Detached HEAD
For most of the time, HEAD points to a branch name. When we add a new commit, our branch reference is updated to point to it, but HEAD remains the same. When we change branches, HEAD is updated to point to the branch we've switched to. All of that means, in the above scenarios, HEAD is synonymous with “the last commit in the current branch.” This is the normal state in which HEAD is attached to a branch:
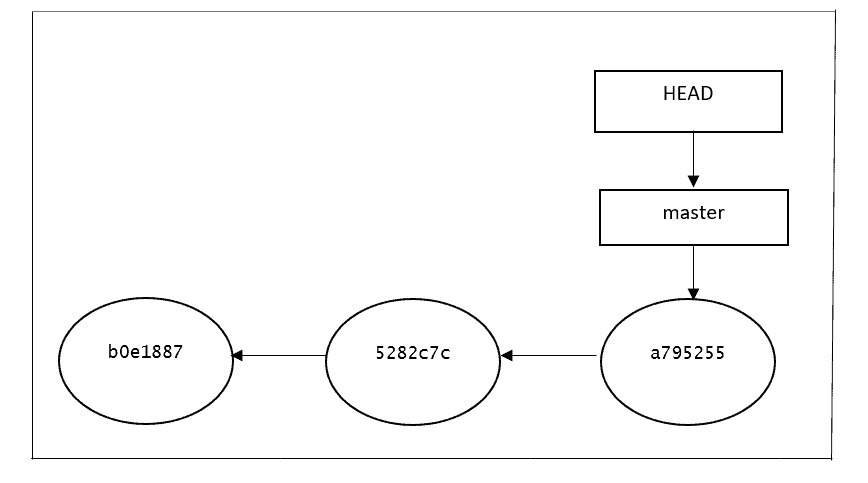
As we can see, HEAD points to the master branch, which points to the last commit. Everything looks perfect. However, after running the below command the repo is in a detached HEAD:
$ git checkout 5282c7c
Note: switching to '5282c7c'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
HEAD is now at 5282c7c appending more info
users@ubuntu01: MINGW64 ~/git/detached-head-demo ((5282c7c...))Below is the graphical representation of the current git HEAD. Since we've checkout to a previous commit, now the HEAD is pointing to 5282c7c commit, and the master branch is still referring to the same:
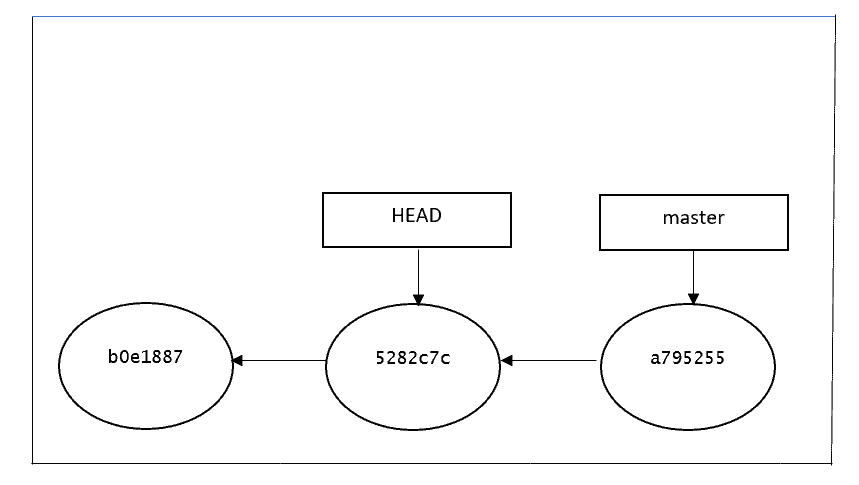
4. Benefits of a Git Detached HEAD
After detaching the HEAD by checking out a particular(5282c7c) commit, it is allowing us to go to the previous point in the project’s history.
Let’s say we want to check if a given bug already existed last Tuesday. We can use the log command, filtering by date, to start the relevant commit hash. Then we can check out the commit and test the application, either by hand or by running our automated test suite.
What if we could take not only a look at the past but also change it? That’s what a detached HEAD allows us to do. Let’s review how to do it using the below commands:
echo "understanding git detached head scenarios" > sample-file.txt
git add .
git commit -m "Create new sample file"
echo "Another line" >> sample-file.txt
git commit -a -m "Add a new line to the file"We now have two additional commits that descend from our second commit. Let’s run git log –oneline and see the result:
$ git log --oneline
7a367ef (HEAD) Add a new line to the file
d423c8c create new sample file
5282c7c appending more info
b0e1887 creating first fileBefore HEAD was pointing to the 5282c7c commit, then we added two more commits, d423c8c and 7a367ef. Below is the graphical representation of the commits done on top of HEAD. It shows that now HEAD is pointing to the latest commit 7a367ef:

What should we do if we want to keep these changes or go back to the previous one? We'll see in the next point.
5. Scenarios
5.1. By Accident
If we’ve reached the detached HEAD state by accident – that is to say, we didn’t mean to check out a commit – going back is easy. Just check out the branch we were in before using one the below command:
git switch <branch-name> git checkout <branch-name>5.2. Made Experimental Changes but Need to Discard Them
In some scenarios, if we made changes after detaching HEAD to test some functionality or identify the bugs but we don't want to merge these changes to the original branch, then we can simply discard it using the same commands as the previous scenario and go to back our original branch.
5.3. Made Experimental Changes but Need to Keep Them
If we want to keep changes made with a detached HEAD, we just create a new branch and switch to it. We can create it right after arriving at a detached HEAD or after creating one or more commits. The result is the same. The only restriction is that we should do it before returning to our normal branch. Let’s do it in our demo repo using the below commands after creating one or more commits:
git branch experimental
git checkout experimentalWe can notice how the result of git log –oneline is exactly the same as before, with the only difference being the name of the branch indicated in the last commit:
$ git log --oneline
7a367ef (HEAD -> experimental) Add a new line to the file
d423c8c create new sample file
5282c7c appending more info
b0e1887 creating first file6. Conclusion
As we’ve seen in this article, a detached HEAD doesn’t mean something is wrong with our repo. Detached HEAD is just a less usual state our repository can be in. Aside from not being an error, it can actually be quite useful, allowing us to run experiments that we can then choose to keep or discard.














