In this article, we’ll look at ways to get the value of attributes of web elements on a web page using Selenium WebDriver with Java. We’ll also explore the differences between getText() and getAttribute() methods.
For testing, we’ll use JUnit and Selenium to open https://www.baeldung.com/contact. The page has a visible input field called “Your Name*”. We’ll use this field to show the difference between getText() and getAttribute().
2. Dependencies
First, we add the selenium-java and Junit dependencies to our project in the pom.xml:
Next, we need to configure WebDriver. In this example, we’ll use its Chrome implementation after downloading its latest version:
@BeforeEach
public void setUp() {
WebDriverManager.chromedriver().setup();
driver = new ChromeDriver();
}
We’re using a method annotated with @BeforeEach to do the initial setup before each test. Next, we use WebDriverManager to get the Chrome Driver without explicitly downloading and installing it. This allows us to use the Selenium Web Driver without the need to use the absolute path of the driver. We still need the Chrome browser installed on the target machine where we’ll run this code.
When the test finishes, we should close the browser window. We can do this by placing the driver.close() statement inside a method annotated with @AfterEach. This ensures that it’ll be executed even if the test fails:
@AfterEach
public void cleanUp() {
driver.close();
}
The contact page has a visible input field called “Your Name*”. We use the browser development tools (inspect element) to choose the HTML code relevant to this field:
We’re interested in the visible text on the label, i.e. “Your Name”. We can get hold of the visible text using the getText() method on a selenium Element. Now, as is evident from the HTML excerpt, this label element also contains a lot of other code apart from the visible text. However, getText() only gets the text that would be visible to us when we view the page on a browser.
To illustrate this, we write a test that confirms that the page contains a field with the visible text “Your Name”. First, we define some constants:
private static final String URL = "https://www.baeldung.com/contact";
private static final String LABEL_XPATH = "//label[contains(text(),'Your Name')]";
private static final String LABEL_TEXT = "Your Name*";
private static final String INPUT_XPATH = "//label[contains(text(),'Your Name')]//input";
Then we add a test method to confirm that the text that is returned by getText() exactly matches the visible text “Your Name*”:
Further, we also note that the input element has no visible text, and therefore, when we run the getText() method on this element, we expect an empty String. We add another test method to confirm this:
Now that we understand the workings of getText(), we review the use of getAttribute().
5. Find Attribute Value getAttribute()
We now examine the usage of getAttribute() on a web element. This time we focus on the input field with the name “your-name”. It has many attributes, such as size, maxlength, value, type, and name. The getAttribute() method on a web element is expected to return the value associated with an attribute passed as the method parameter provided such an attribute exists on the web element. If no such attribute exists, the method returns a null value.
e.g. If we review the HTML excerpt from the label element, we notice that the input element has an attribute name with the value “your-name” and another attribute maxlength with the value 400.
When writing tests that involve checking these attributes, we use the getAttribute method. We first define constants for values we want to check:
private static final String INPUT_NAME = "your-name";
private static final String INPUT_LENGTH = "400";
5.1. Test to Get Value of an Attribute
Let’s add a couple of tests to check the attribute values for the attributes called name and maxlength:
In this article, we’ve learned how to get the visible text and the value of attributes of web elements on a web page using Selenium WebDriver with Java. The getText() only shows the plain text as visible on an element when the web page is viewed on a browser whereas getAttribute() allows us to get the values against many different attributes on a web element.
The general flow is to use Selenium selectors to identify the web element of interest and then to use one of the methods getText() or getAttribute() to get more details about a web element.
We also added a few sample tests to demonstrate the usage of these methods in automated tests. As always, the source for the article is available over on GitHub.
Microservices architecture has transformed how we design and build applications by breaking down monolithic systems into smaller, loosely coupled services. These services communicate with each other primarily through REST APIs, making it essential to understand how to consume these APIs effectively.
Quarkus is a modern Java framework optimized for microservices.
In this tutorial, we’ll explore how to create a dummy REST API in Quarkus and demonstrate various methods to consume it using different clients. This knowledge is crucial for building robust and efficient microservice-based applications.
2. Creating the API
To get started, we need to set up a basic Quarkus application and create a dummy REST API that returns a list of posts.
2.1. Creating Post Entity
We’re going to create a Post entity that our API will return:
public class Post {
public Long id;
public String title;
public String description;
// getters, setters, constructors
}
2.2. Creating Post Resource
Also, for this example, we’ll create a resource that will return a list of posts in JSON format:
@Path("/posts")
public class PostResource {
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Post> getPosts() {
return Arrays.asList(
new Post(1L, "Post One", "This is the first post"),
new Post(2L, "Post Two", "This is the second post")
);
}
}
We’ll consume this API in our new application.
2.3. Testing the API
We can test our new API using curl:
curl -X GET http://localhost:8080/posts
By calling this, we’ll get a JSON list of posts:
[
{
"id": 1,
"title": "Post One",
"description": "This is the first post"
},
{
"id": 2,
"title": "Post Two",
"description": "This is the second post"
}
]
Now, having this API functional, we’ll see how to consume it inside another Quarkus application instead of curl.
3. Consuming API with Rest Client
Quarkus supports MicroProfile Rest Client, a powerful and type-safe HTTP client, which simplifies consuming RESTful APIs by providing an interface-driven approach.
The @RegisterRestClient annotation registers this interface as a REST client, and the configKey attribute is used to bind configuration properties. The @Path annotation specifies the base path of the API.
3.3. Configuration
The base URL for the REST client can be specified in the application.properties file using the configKey defined in the interface:
By doing that, we can easily modify the API’s base URL without changing the source code. Besides that, we can also change the default port of the application:
quarkus.http.port=9000
We do this because the first API runs on the default port 8080.
3.4. Using the Rest Client
Once the Rest Client interface is defined and configured, we can inject it into a Quarkus service or resource class using the @RestClient annotation. This annotation tells Quarkus to provide an instance of the specified interface configured with the base URL and other settings:
@Path("rest-client/consume-posts")
public class PostClientResource {
@Inject
@RestClient
PostRestClient postRestClient;
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Post> getPosts() {
return postRestClient.getAllPosts();
}
}
3.5. Testing the Application
Now, with everything set up, we can test our application. We can do that by running a curl command:
curl -X GET localhost:9000/rest-client/consume-posts
This should return our JSON list of posts.
4. Consuming API with JAX-RS Client API
The JAX-RS Client API is a part of the Java API for RESTful Web Services (JAX-RS) specification. It provides a standard, programmatic way to create HTTP requests and consume RESTful web services.
4.1. Maven Dependency
To start, we need to include RESTEasy Client dependency in our pom.xml:
This dependency brings in RESTEasy, the JAX-RS implementation used by Quarkus, and the client API necessary for making HTTP requests.
4.2. Implementing the JAX-RS Client
To consume a REST API, we’ll create a service class that sets up a JAX-RS client, configures the target URL, and processes the responses:
@ApplicationScoped
public class JaxRsPostService {
private final Client client;
private final WebTarget target;
public JaxRsPostService() {
this.client = ClientBuilder.newClient();
this.target = client.target("http://localhost:8080/posts");
}
public List<Post> getPosts() {
return target
.request()
.get(new GenericType<List<Post>>() {});
}
}
We initialize the client using the builder pattern and configure the target with the base URL for API requests.
4.3. Exposing the API through a Resource Class
Now, all we need to do is to inject our service into our resources:
@Path("jax-rs/consume-posts")
public class PostClientResource {
@Inject
JaxRsPostService jaxRsPostService;
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Post> getJaxRsPosts() {
return jaxRsPostService.getPosts();
}
}
4.4. Testing the Application
Now we can test again our API using curl:
curl -X GET localhost:9000/jax-rs/consume-posts
5. Consuming API with Java 11 HttpClient
Java 11 introduced a new HTTP client API that provides a modern, asynchronous, and feature-rich way to handle HTTP communications. The java.net.http.HttpClient class allows us to send HTTP requests and process responses easily, and in this section, we’ll learn how to do it.
5.1. Creating the HttpClient Service
No additional dependencies are required in this example, Java 11’s HttpClient being part of the standard library.
Now, we’ll create a service class that manages the HttpClient:
@ApplicationScoped
public class JavaHttpClientPostService {
private final HttpClient httpClient;
private final ObjectMapper objectMapper;
public JavaHttpClientPostService() {
this.httpClient = HttpClient.newHttpClient();
this.objectMapper = new ObjectMapper();
}
public List<Post> getPosts() {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://localhost:8080/posts"))
.GET()
.build();
try {
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
return objectMapper.readValue(response.body(), new TypeReference<ArrayList<Post>>() { });
}
catch (IOException | InterruptedException e) {
throw new RuntimeException("Failed to fetch posts", e);
}
}
}
In this class, we initialize the HttpClient instance and an ObjectMapper instance from Jackson that we’ll use to parse JSON responses into Java objects.
We create an HttpRequest object, specifying the URI of the API endpoint and the HTTP method. After that, we send the request using the send() method of the HttpClient instance. We handle the response using BodyHandlers.ofString(), which converts the body into a string. We’ll convert that string into our Post object using the ObjectMapper.
5.2. Creating the Resource
To make the fetched data available via our application, we’ll expose the JavaHttpClientPostService through a resource class:
@Path("/java-http-client/consume-posts")
public class JavaHttpClientPostResource {
@Inject
JavaHttpClientPostService postService;
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Post> getPosts() {
return postService.getPosts();
}
}
5.3. Testing the Application
Now we can test the app again using curl:
curl -X GET localhost:9000/java-http-client/consume-posts
6. Conclusion
In this article, we demonstrated how to consume REST APIs in Quarkus using the Quarkus RestClient, JAX-RS Client API, and Java 11 HttpClient.
Each method has advantages: the RestClient integrates seamlessly with Quarkus, the JAX-RS Client API offers flexibility, and Java 11’s HttpClient brings modern features from the JDK. Mastering these techniques enables effective communication between microservices, making building scalable and efficient architectures in Quarkus easier.
Well-defined, often machine-readable logging formats in Spring Boot 3.4: supporting common structured formats as well as being customizable. Really good stuff
From a product built using shared hard disk drives (HDDs), to one that is capable of delivering hundreds of thousands of IOPS. Always an interesting read
I know that makes a lot more sense sometimes than Yearly. There’s lots of new stuff coming in Pro, and I’m sure I’ll talk about it over the next couple of months.
In this tutorial, we’ll understand why Jakarta EE became the successor to Java EE and learn how to migrate to it.
2. The Genesis of Jakarta EE
Java EE (Java Platform, Enterprise Edition) is a set of specifications first introduced in December 1999 by Sun Microsystems to extend the Java language for traditional enterprise workloads. Oracle then bought Sun in 2009. In 2017, Oracle decided to move the development of Java EE to the Eclipse Foundation, a nonprofit organization known for fostering open-source projects. However, Oracle remains the owner of the Java trademark. Thus, a community vote led to renaming the project to Jakarta EE.
3. Why Migrate to Jakarta EE?
First of all, after the responsibility transfer to the Eclipse Foundation, the original Java EE technology doesn’t receive any new updates, features, or improvements. Thus, in a permanently evolving industry, we can leverage new development paradigms with Jakarta EE. For instance, better microservice support and cloud-native application development were the first focuses of the Eclipse Foundation.
Additionally, migrating grants us long-term support for our application. Furthermore, most vendors and application servers have already transitioned to support Jakarta EE.
Lastly, we might have to migrate during a framework version upgrade. In particular, if we develop a web application with Spring, we’ll need to migrate to Jakarta EE to benefit from version 3.
4. How to Migrate From Java EE to Jakarta EE
We’ll start by migrating our own code. We’ll take care of external dependencies afterward. Last but not least, we’ll make sure we run our application on a compatible tool.
4.1. Application Code
At first glance, migrating from Java EE to Jakarta EE is a refactor to use the jakarta namespace instead of the javax namespace. We need to change the references not only in our class imports but also in our pom files, configuration files, etc.
In reality, the change is a bit more complicated than just a find/replace action. Some javax packages remain outside Jakarta EE and are therefore unaffected by the change. An exhaustive list of unaffected packages is available on the Jakarta EE GitHub.
In a nutshell, this task is repetitive and can pose unexpected difficulties, making it a perfect target for automation. In particular, if we use IntelliJ IDEA, we can open the Refactor menu and then click Migrate Packages and Classes. After that, we can choose Java EE to Jakarta EE and then click Run to have all the relevant imports updated automatically.
Other automation options include using OpenRewrite, an automated code refactoring tool that helps perform large-scale code transformations. In particular, the Jakarta EE migration tool is available in their documentation.
Similarly, we can use the Eclipse Transformer tool for a smooth migration. Originally, this tool targeted our problem specifically. Later, it widened its horizons by addressing general shading issues. Both tools can be used via the command line or through Maven.
4.2. Dealing With External Libraries
The migration can become trickier when dealing with external libraries since we can’t modify the code we don’t own as we wish. The good news is that most Open Source libraries have already migrated toward Jakarta EE. In this case, we only need to use the new version of the library. Some upgraded to a new major version, whereas others moved their repository location.
The situation becomes more epic when such updated version doesn’t exist. In such a situation, evaluating if we want to get rid of the dependency in favor of a more up-to-date one is certainly a question we should ask ourselves. Nevertheless, sometimes, we don’t want this situation to stop us from upgrading to Jakarta EE.
If we get to the unfortunate point that we have a legacy dependency using Java EE libraries and can’t do anything about it but still want to migrate, there is a solution. We can transform the library source code to upgrade it to Jakarta EE. Once again, Eclipse Transformer and OpenRewrite tools are designed to rewrite byte code on the fly to cope with the migration.
Additionally, if we use Tomcat as an application server, the Apache Foundation offers a dedicated migration tool.
To conclude, it’s important to note that mixing jakarta and javax dependencies in the same application isn’t recommended, as it can lead to namespace collisions and other unexpected issues.
4.3. Using an Adequate Server
Servers provide an environment to run and manage our applications. In particular, they include the javax libraries. That’s why we generally mark them as provided in our pom files. Thus, we need an upgraded server version that can cope with Jakarta EE. The Jakarta EE team maintains a compatibility page for that purpose. This page lists all the tools certified to work with Jakarta EE.
5. Conclusion
In this article, we recalled that the responsibility transfer from Oracle to the Eclipse Foundation entailed the name change to Jakarta EE. We also learned it’s a good idea to migrate to keep our applications up-to-date. We saw that the migration isn’t as easy as it initially looks. Hence, we looked at a couple of tools to automate the migration.
Given that we can run those tools through the command line or via Maven, we have various options when addressing non-migrated dependencies, like publishing updated artifacts of external libraries on our repositories or running the migration tool automatically on every build.
Reflection in Java is a powerful feature that allows us to manipulate different members, such as classes, interfaces, fields, and methods. Moreover, using reflection, we can instantiate classes, call methods, and access fields at compile time without knowing the type.
In this tutorial, we’ll first explore the JVM access flags. Then, we’ll see how we can use them. Lastly, we’ll examine the differences between modifiers and access flags.
2. JVM Access Flags
Let’s start by understanding the JVM access flags.
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
The ClassFile, among other items, contains the access_flags item. Simply put, the access_flags is a mask that consists of various flags that define access permissions and other properties on a class.
Additionally, the ClassFile consists of the field_info and the method_info items, each containing its access_flags item.
Libraries like Javassist and ASM use the JVM access flags to manipulate Java bytecode.
Apart from Java, JVM supports other languages, such as Kotlin or Scala. Each language has defined its modifiers. For example, the Modifier class in Java contains all modifiers specific to the Java programming language. Moreover, we usually rely on the information retrieved from these classes when working with reflection.
Nevertheless, the problem arises when modifiers need to be transformed into the JVM access flags. Let’s further examine why.
3. AccessFlag for Modifiers
Modifiers such as varargs and transient or volatile and bridge use the same integer bit mask. To fix bit collisions between different modifiers, Java 20 introduced the AccessFlag enum, which includes all modifiers we can use within a class, field, or method.
The enumeration models the JVM access flags to ease mapping between modifiers and access flags. Without the AccessFlag enum, we’d need to consider the element’s context to determine which modifier is used, especially for those with the exact bit representation.
To see AccessFlag in action, let’s create the AccessFlagDemo class with several methods, each using different modifiers:
public class AccessFlagDemo {
public static final void staticFinalMethod() {
}
public void varArgsMethod(String... args) {
}
public strictfp void strictfpMethod() {
}
}
Next, let’s examine the access flags used in the staticFinalMethod() method:
Here, we called the accessFlags() method, which returned EnumSet wrapped into an unmodifiable set. Internally, the method uses the getModifiers() method and returns access flags depending on the location where flags can be applied. Our method contains three access flags: PUBLIC, STATIC, and FINAL.
Additionally, as of Java 17, the strictfp modifier is redundant and is no longer compiled into the bytecode:
As we can see, the strictfpMethod() contains a single access flag.
4. getModifiers() vs. accessFlags() Methods
When working with reflection in Java, we often use the getModifiers() method to retrieve all modifiers defined on classes, interfaces, methods, or fields:
The getModifiers() method returns an integer value representing encoded modifier flags.We called the isStatic() method defined inside the Modifier class to check whether the method contains a static modifier. Additionally, Java decodes flags inside the method to determine whether the method is static or not.
Furthermore, it’s worth noting that the access flags aren’t identical to modifiers defined in Java. Some access flags and modifiers have a one-to-one mapping, such as public. However, some modifiers, such as sealed, don’t have specified access flags. Likewise, we can’t map some access flags, like synthetic, to the corresponding modifier value.
Going further, since some modifiers share the exact bit representation, we may come to the wrong conclusions if we don’t consider the context in which modifiers are used.
Let’s call the Modifier.toString() on the varArgsMethod():
The method returns a publictransient as a result. Without considering the context, we might conclude that the varArgsMethod() is transient, which isn’t accurate.
On the other hand, access flags consider the context of where the bits come from. Therefore, it provides the correct information:
In this article, we learned what the JVM access flags are and how to use them.
To sum up, JVM access flags contain information about access permissions and other properties on the runtime members, such as classes, methods, and fields. We can utilize access flags to get accurate information about modifiers on specific elements.
As always, the entire code examples are available over on GitHub.
In Java programming, one frequently encountered task is distinguishing between odd and even numbers within an array. Mastering this technique can enhance the ability to handle data efficiently and implement more sophisticated algorithms.
In this tutorial, we’ll learn how to find the odd and even numbers in an Array using Java.
2. Odd and Even Numbers and the Modulus Operator
Understanding how to classify numbers as odd or even is fundamental before coding. In mathematical terms, even numbers are integers divisible by 2 without leaving a fraction, such as 10 or 22. Odd numbers, however, result in a remainder of 1 when divided by 2, with examples including 7 and 15.
In Java, the modulus operator (%) is commonly used to check whether a number is odd or even. For instance:
number % 2 == 0 indicates the number is even.
number % 2 != 0 indicates the number is odd.
3. Identifying Odd and Even Numbers Using Loops
To identify odd and even numbers in an array, we can use loops to iterate over each element and determine its parity. We’ll use in this approach two separate methods: findEvenNumbersWithLoop(int[] numbers) and findOddNumbersWithLoop(int[] numbers).
The findEvenNumbersWithLoop(int[] numbers) method iterates over the array and checks each number to see if it is even by using the modulus operator (%). If “number % 2 == 0″ evaluates to true, the number is added to a list of even numbers.
Conversely, the findOddNumbersWithLoop(int[] numbers) method performs a similar iteration but checks for odd numbers with the condition “number % 2 != 0“.
Let’s implement this approach:
public static List<Integer> findOddNumbersWithLoop(int[] numbers) {
List<Integer> oddNumbers = new ArrayList<>();
for (int number : numbers) {
if (number % 2 != 0) {
oddNumbers.add(number);
}
}
return oddNumbers;
}
public static List<Integer> findEvenNumbersWithLoop(int[] numbers) {
List<Integer> evenNumbers = new ArrayList<>();
for (int number : numbers) {
if (number % 2 == 0) {
evenNumbers.add(number);
}
}
return evenNumbers;
}
In this implementation, the findEvenNumbersWithLoop(int[] numbers) method initializes an ArrayList to store even numbers and iterates through the input array, adding each even number to this list. The findOddNumbersWithLoop(int[] numbers) method operates similarly but focuses on collecting odd numbers.
Both methods use a simple for loop to process the array elements, making the code easy to understand and maintain.
4. Identifying Odd and Even Numbers Using Streams
Building on the loop-based methods, we can use Java’s Stream API to achieve similar results in a more modern and efficient manner. The Stream API provides a more concise and readable way to process arrays and identify odd and even numbers.
To transition from the loop-based approach, we’ll create two new methods that leverage streams: findEvenNumbersWithStream(int[] numbers) and findOddNumbersWithStream(int[] numbers). These methods use the filtering capabilities of streams to simplify the code.
Let’s apply this technique to solve the problem of identifying odd and even numbers:
public static List<Integer> findEvenNumbersWithStream(int[] numbers) {
return Arrays.stream(numbers)
.filter(number -> number % 2 == 0)
.boxed()
.collect(Collectors.toList());
}
public static List<Integer> findOddNumbersWithStream(int[] numbers) {
return Arrays.stream(numbers)
.filter(number -> number % 2 != 0)
.boxed()
.collect(Collectors.toList());
}
In this above code, the findEvenNumbersWithStream(int[] numbers) and findOddNumbersWithStream(int[] numbers) methods leverage the Stream API to handle an array of primitive integers.
The findEvenNumbersWithStream(int[] numbers) method creates a stream from the array and applies a filter to select only the even numbers, where “number % 2 == 0“. It then collects these filtered results into a List<Integer> using the collect(Collectors.toList()) method.
Similarly, the findOddNumbersWithStream(int[] numbers) method filters the stream to include only odd numbers where “number % 2 != 0″. The results are then collected into a List<Integer> in the same manner.
5. Conclusion
Identifying odd and even numbers in an array is a straightforward task in Java, but it’s a fundamental operation with wide-ranging applications. By using the modulus operator along with simple loops or stream filtering, we can efficiently separate these numbers for various uses.
The concepts and code examples discussed in this article provide a solid foundation for handling similar tasks in your Java programming projects.
The @DynamicInsert annotation in Spring Data JPA optimizes insert operations by including only non-null fields in SQL statements. This process speeds up the resulting query, reducing unnecessary database interactions. While it improves efficiency for entities with many nullable fields, it introduces some runtime overhead. Therefore, we should use it selectively in cases where the benefits of excluding null columns outweigh the performance cost.
2. Default Insert Behavior in JPA
When persisting a JPA entity using the EntityManager or Spring Data JPA’s save() method, Hibernate generates an SQL insert statement. This statement includes every entity column, even if some contain null values. As a result, the insert operation can be inefficient when dealing with large entities containing many optional fields.
Let’s see this save in action now. We’ll start by considering a simple Account entity:
@Entity
public class Account {
@Id
private int id;
@Column
private String name;
@Column
private String type;
@Column
private boolean active;
@Column
private String description;
// getters, setters, constructors
}
We’ll also create a JPA repository for the Account entity:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {}
In this case, when we save a new Account object:
Account account = new Account();
account.setId(ACCOUNT_ID);
account.setName("account1");
account.setActive(true);
accountRepository.save(account);
Hibernate will generate an SQL insert statement that includes all columns, even though only a few columns have non-null values:
insert into Account (active,description,name,type,id) values (?,?,?,?,?)
This behavior is not always optimal, especially for large entities where certain fields might be null or only initialized later.
3. Using @DynamicInsert
We can use the @DynamicInsert annotation at the entity level to optimize this insert behavior. When applied, Hibernate will generate an SQL insert statement that only includes the columns with non-null values, avoiding unnecessary columns in the SQL query.
Let’s add the @DynamicInsert annotation to the Account entity:
Now, when we save a new Account entity with some columns set to null, Hibernate will generate an optimized SQL statement:
Account account = new Account();
account.setId(ACCOUNT_ID);
account.setName("account1");
account.setActive(true);
accountRepository.save(account);
The generated SQL will only include the non-null columns:
insert into Account (active,name,id) values (?,?,?)
4. How @DynamicInsert Works
At the Hibernate level, @DynamicInsert affects how the framework generates and executes SQL insert statements. By default, Hibernate pre-generates and caches static SQL insert statements that include every mapped column, even if some columns contain null values when it persists an entity. This is part of Hibernate’s performance optimization, as it reuses precompiled SQL statements without regenerating them each time.
However, when we apply the@DynamicInsert annotation to an entity, Hibernate alters this behavior and dynamically generates the insert SQL statement at runtime.
5. When to Use @DynamicInsert
The @DynamicInsert annotation is a powerful feature in Hibernate, but its usage should be applied selectively based on specific scenarios. One such scenario involves entities with many nullable fields. When an entity has fields that may not always be populated, @DynamicInsert optimizes the insert operation by excluding unset columns from the SQL query. This reduces the size of the generated query and improves performance.
This annotation is also beneficial when certain database columns have default values. Preventing Hibernate from inserting null values allows the database to handle those fields using its default settings. For example, a created_at column might automatically set the current timestamp when a record is inserted. By excluding this field in the insert statement, Hibernate preserves the database’s logic and prevents overriding default behavior.
Additionally, @DynamicInsert can be advantageous in scenarios where insert performance is critical. This annotation ensures only relevant data is sent to the database for entities with many fields that might not all be populated. This is particularly useful in high-performance systems, where minimizing the size of SQL statements can significantly impact efficiency.
6. When Not to Use @DynamicInsert
Although, as we have seen, this annotation has many benefits, there may be cases where it is not the best choice. The most concrete case in which we should not use @DynamicInsert would be the case in which our entity has mostly non-null values. In this case, the dynamic SQL generation can add unnecessary complexity without offering significant. In such cases, since most fields are populated during insert operations, the optimization provided by @DynamicInsert becomes redundant.
Also, not only tables with many non-null fields can be unsuitable for @DynamicInsert, but also tables with few properties. For simple entities or small tables with only a few fields, the advantages of using @DynamicInsert are minimal and the performance gains from excluding null values are unlikely to be noticeable.
In scenarios involving bulk insertions, the dynamic nature of @DynamicInsert can lead to inefficiencies. Since Hibernate regenerates the SQL for each entity rather than reusing a precompiled query, bulk inserts may not perform as efficiently as they would with a static SQL insert.
In some cases, @DynamicInsert may not align well with complex database configurations or schemas, particularly when intricate constraints or triggers are involved. For example, if a schema has constraints that require specific values for certain columns, @DynamicInsert might omit these columns if they are null, leading to constraint violations or errors.
Suppose we have our Account entity with a database trigger that inserts “UNKNOWN” if the article type is null:
CREATE TRIGGER `account_type` BEFORE INSERT ON `account` FOR EACH ROW BEGIN
IF NEW.type IS NULL THEN
SET NEW.type = 'UNKNOWN';
END IF;
END
If the type is not provided, Hibernate excludes the column entirely. As a result, the trigger may not activate.
7. Conclusion
In this article, we explored the @DynamicInsert annotation and saw its practical application through code examples. We examined how Hibernate dynamically generates SQL insert statements that include only non-null columns, optimizing performance by avoiding unnecessary data in the SQL query.
We also discussed the advantages, such as improved efficiency for entities with many nullable fields and better respect for database default values. However, we highlighted its limitations, including potential overhead and complications when inserting deliberate null values. By understanding these aspects, we can make an informed decision about when and how to use @DynamicInsert in our applications.
As always, the complete code examples used in this tutorial are available over on GitHub.
In this tutorial, we’ll learn how to execute synchronous requests using the WebClient.
While reactive programming continues to become more widespread, we’ll examine scenarios in which such blocking requests are still appropriate and necessary.
2. Overview of HTTP Client Libraries in Spring
Let’s first briefly review the client libraries that are currently available and see where our WebClient fits in.
When introduced in Spring Framework 3.0, RestTemplate became popular for its simple template method API for HTTP requests. However, its synchronous nature and many overloaded methods led to complexity and performance bottlenecks in high-traffic applications.
In Spring 5.0, WebClient was introduced as a more efficient, reactive alternative for non-blocking requests. Although it’s part of a reactive-stack web framework, it supports a fluent API for both synchronous and asynchronous communication.
With Spring Framework 6.1, RestClient offers another option for executing REST calls. It combines the fluent API of WebClient with the infrastructure of RestTemplate, including message converters, request factories, and interceptors.
While RestClient is optimized for synchronous requests, WebClient is better if our application also requires asynchronous or streaming capabilities. Using WebClient for blocking and non-blocking API calls, we maintain consistency in our codebase and avoid mixing different client libraries.
3. Blocking vs. Non-blocking API Calls
When discussing various HTTP clients, we’ve used terms like synchronous and asynchronous, blocking and non-blocking. The terms are context-sensitive and may sometimes represent different names for the same idea.
In the context of method calls, WebClient supports synchronous and asynchronous interactions based on how it sends and receives HTTP requests and responses. If it waits for the previous one to finish before proceeding to the subsequent requests, it’s doing this in a blocking manner, and the results are returned synchronously.
On the other hand, we can achieve asynchronous interactions by executing a non-blocking call that returns immediately. While waiting for the response from another system, other processing can continue, and the results are provided asynchronously once ready.
4. When to Use Synchronous Requests
As mentioned, WebClient is part of the Spring Webflux framework, in which everything is reactive by default. However, the library offers asynchronous and synchronous operations support, making it suitable for reactive and servlet-stack web applications.
Using WebClient in a blocking manner is appropriate when immediate feedback is needed, such as during testing or prototyping. This approach allows us to focus on functionality before considering performance optimizations.
Many existing applications still use blocking clients like RestTemplate. Since RestTemplate is in maintenance mode from Spring 5.0, refactoring legacy codebases would require a dependency update and potentially a transition to non-blocking architecture. In such cases, we could temporarily use WebClient in a blocking manner.
Even in new projects, some application parts could be designed as a synchronous workflow. This can include scenarios like sequential API calls towards various external systems where the result of one call is necessary to make the next. WebClient can handle blocking and non-blocking calls instead of using different clients.
As we’ll see later on, the switch between synchronous and asynchronous execution is relatively simple. Whenever possible, we should avoid using blocking calls, especially if we’re working on a reactive stack.
5. Synchronous API Calls With WebClient
When sending an HTTP request, WebClient returns one of two reactive data types from the Reactor Core library – Mono or Flux. These return types represent streams of data, where Mono corresponds to a single value or an empty result, and Flux refers to a stream of zero or multiple values. Having an asynchronous and non-blocking API lets the caller decide when and how to subscribe, keeping the code reactive.
However, if we want to simulate synchronous behavior, we can call the available block() method. It’ll block the current operation to obtain the result.
To be more precise, the block() method triggers a new subscription to the reactive stream, initiating the data flow from the source to the consumer. Internally, it waits for the stream to complete using a CountDownLatch, which pauses the current thread until the operation is finished, i.e., until the Mono or Flux emits a result. The block() method transforms a non-blocking operation into a traditional blocking one, causing the calling thread to wait for the outcome.
6. Practical Example
Let’s see this in action. Imagine a simple API Gateway application between client applications and two backend applications – Customer and Billing systems. The first holds customer information, while the second provides billing details. Different clients interact with our API Gateway through the northbound API, which is the interface exposed to the clients to retrieve customer information, including their billing details:
@GetMapping("/{id}")
CustomerInfo getCustomerInfo(@PathVariable("id") Long customerId) {
return customerInfoService.getCustomerInfo(customerId);
}
Here’s what the model class looks like:
public class CustomerInfo {
private Long customerId;
private String customerName;
private Double balance;
// standard getters and setters
}
The API Gateway simplifies the process by providing a single endpoint for internal communication with the Customer and Billing applications. It then aggregates the data from both systems.
Consider the scenario where we used the synchronous API within the entire system. However, we recently upgraded our Customer and Billing systems to handle asynchronous and non-blocking operations. Let’s see what those two southbound APIs look like now.
In a real-world scenario, these APIs would be part of separate components. However, we’ve organized them into different packages within our code for simplicity. Additionally, for testing, we’ve introduced a delay to simulate the network latency:
public static final Duration SLEEP_DURATION = Duration.ofSeconds(2);
Unlike the two backend systems, our API Gateway application must expose a synchronous, blocking API to avoid breaking the client contract. Therefore, nothing changes in there.
The business logic resides within the CustomerInfoService. First, we’ll use WebClient to retrieve data from the Customer system:
And finally, using the responses from both components, we’ll construct a response:
new CustomerInfo(customer.getId(), customer.getName(), billing.getBalance());
In case one of the API calls fails, error handling defined inside the onStatus() method will map the HTTP error status to an ApiGatewayException. Here, we’re using a traditional approach rather than a reactive alternative through the Mono.error() method. Since our clients expect a synchronous API, we’re throwing exceptions that would propagate to the caller.
Despite the asynchronous nature of the Customer and Billing systems, WebClient’s block() method enables us to aggregate data from both sources and return a combined result transparently to our clients.
6.1. Optimizing Multiple API Calls
Moreover, since we’re making two consecutive calls to different systems, we can optimize the process by avoiding blocking each response individually. We can perform the following:
zip() is a method that combines multiple Mono instances into a single Mono. A new Mono is completed when all of the given Monos have produced their values, which are then aggregated according to a specified function – in our case, creating a CustomerInfo object. This approach is more efficient as it allows us to wait for the combined result from both services simultaneously.
To verify that we’ve improved the performance, let’s run the test on both scenarios:
Initially, the test failed. However, after switching to waiting for the combined result, the test was completed within the combined duration of the Customer and Billing system calls. This indicates that we’ve improved the performance by aggregating responses from both services. Even though we’re using a blocking synchronous approach, we can still follow best practices to optimize performance. This helps ensure the system remains efficient and reliable.
7. Conclusion
In this tutorial, we demonstrated how to manage synchronous communication using WebClient, a tool designed for reactive programming but capable of making blocking calls.
To summarize, we discussed the advantages of using WebClient over other libraries like RestClient, especially in a reactive stack, to maintain consistency and avoid mixing different client libraries. Lastly, we explored optimizing performance by aggregating responses from multiple services without blocking each call.
As always, the complete source code is available over on GitHub.
In this tutorial, we’ll look at ways to deploy a simple Spring Boot Java app to the cloud using Heroku, a platform that simplifies app deployment, management, and scaling by handling infrastructure.
2. Installation
For the purpose of this article, we’ll be using a simple Hello World Spring Java app, with Maven as a build system. The app will have one mapping that returns Hello, Heroku! when accessed.
2.1. Project Setup
With the Hello World project open, let’s add a few configuration files.
To begin, we create a Procfile in the project’s root directory. This file defines process types and explicitly outlines the command to launch our application. Once created, we add the following command:
web: java -Dserver.port=$PORT -jar target/*.jar
Now, we create a system.properties file within the root folder. In this file, we’ll specify the Java Runtime Environment that Heroku should use. By default, Heroku uses Java 8:
java.runtime.version=17
We’ve finished setting up our project. Next, we’ll configure Heroku, which will prepare us for deployment.
2.2. Heroku Setup
A requirement of the Heroku CLI is Git, and as such, we need to have it installed before proceeding.
Let’s log into the Heroku website and download the CLI client for Windows or use brew tap heroku/brew && brew install heroku for Mac.
Once installed, we can now create a Heroku project via the website or the CLI. Let’s open a terminal window and navigate to our project.
In order to use Heroku, we’ll need to log in with the CLI by using the command heroku login.
We now need to create a Git repo with git init as well as a Heroku app with heroku create. The system assigns a random name to the default app and sets the region to United States. However, users can easily modify these settings through the platform website.
3. Deploy via Heroku CLI
Let’s stage and commit our code and push the changes to the Heroku repository with git push heroku main.
Heroku automatically detects our Java application and initiates the build process. Upon successful completion, we can access our application through a web browser by visiting the provided URL, which typically resembles https://our-app-name.herokuapp.com/.
As a result, we should see the Spring app started and the website should display Hello, Heroku!.
Alternatively, we can quickly verify the app’s startup by executing heroku open in the terminal.
4. Deploy via Heroku Maven Plugin
In addition to using the CLI, Heroku supports building and releasing apps via a Maven plugin named Heroku Maven Plugin.
To use the plugin, we’ll need to add it to pom.xml:
For the next part of the article, we’re going to explore deployment with GitHub and GitLab.
Heroku provides us with a direct connection to GitHub, making it easier to deploy our app. With GitLab, on the other hand, a pipeline needs to be configured.
To use these options, we’ll need to have the project pushed to a repository on these platforms.
5.1. GitHub
With the Heroku website open, we select the project we’ve been working on. Subsequently, we navigate to the Deploy tab and choose GitHub as the deployment method.
After a quick sign-in, we search for and select our repository. Then, we enable Automatic Deploys so that any push to the main branch will automatically trigger a deployment on Heroku.
5.2. GitLab
With GitLab, we’ll have to add a .gitlab-ci.yml file to our project:
Additionally, we’ll need to add the Heroku API key to the GitLab CI/CD variables found in project Settings. The API key can be retrieved from the Heroku website by visiting the user profile.
Since we’re utilizing the Heroku Maven Plugin in our script, we need to incorporate an additional configuration into the pom.xml file. Specifically, we must add the application name as it appears on the Heroku platform. To achieve this, we define the application name within the plugin’s configuration element:
<appName>our-app-name</appName>
Pushing our change initiates the pipeline, which subsequently deploys the app.
6. Deploy With Docker
Assuming Docker is installed locally, we begin by creating a Dockerfile within the project’s root directory. We then populate with the following:
FROM maven:3.8.4-openjdk-17 AS build
WORKDIR /app
COPY . .
RUN mvn clean package -DskipTests
FROM openjdk:17-jdk-slim
WORKDIR /app
COPY --from=build /app/target/*.jar app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]
With the above script, we use Maven to build the application, copy the built .jar file into a slimmer JDK image, and, expose port 8080 for the application to run.
Second, we need to add the application.properties file inside our resource folder to set the server port:
server.port=${PORT:8080}
By doing this, Docker can map the port to our Spring application port.
Third, we’ll build and execute the Docker image, ensuring its proper functionality:
docker build -t our-heroku-app .
docker run -p 8080:8080 our-heroku-app
Let’s curl localhost:8080 to check for the Hello, Heroku! string.
Finally, we must deploy and release our changes to Heroku. To achieve this, let’s execute a few commands in the terminal.
We start by running heroku container:login, to log us into the Heroku Container Registry. We then build and push the Docker image to Heroku with heroku container:push web –app our-heroku-app. Lastly, to release the image of our app, we use heroku container:release web –app our-heroku-app.
After release, our app should be live and we can verify by using the command heroku open –app our-heroku-app.
7. Conclusion
In this article, we’ve explored multiple approaches to deploying a Java app on Heroku.
We saw how to effortlessly set up and deploy a Heroku app using the provided CLI.
Furthermore, we leveraged the Heroku Maven Plugin’s commands to streamline deployments from both the terminal and CI/CD environments.
Finally, we understood the benefits of Docker for quick app deployment.
In this tutorial, we’ll explore how to check if two 2d arrays are equal in Java. First, we’re going to go over the problem and explore it to better understand it. This way, we’ll also understand the common pitfalls and what to look for when dealing with similar problems.
Then, we’ll go over a naive approach to better understand the concepts. Afterwards, we’ll develop a different algorithm. Further, we’ll understand how to solve this problem without using too many resources. Therefore, knowing how to properly compare 2D arrays is not only about solving programming problems.
2. Problem Definition
Comparing 2D arrays is very important in various domains of software development. Here are some domains that use 2D arrays:
image processing (computer vision and image manipulation)
game development (represent game boards, maps, or tile-based worlds)
security and cryptography (some encryption algorithms use 2d arrays of bytes or integers)
Comparing 2D arrays is more challenging than comparing 1D arrays. Unlike 1D arrays, 2D arrays need us to match both rows and columns. Consequently, this adds another layer of complexity.
Furthermore, we need to consider performance – naive methods are usually resource-intensive, especially with larger arrays.
Finally, 2D arrays being nested data structures means the code is more complex and the chances of errors are increased.
First, let’s assume we have two 2d arrays with m number of rows and n number of columns. As a side note, in algorithmics, we usually use m and n to refer to rows and columns, respectively. Now, to consider these two arrays equal, multiple conditions need to be met:
they must have the same number of rows m
they must have the same number of columns n
corresponding elements (arr1[i][j], arr2[i][j]) need to be equal for each i and j
special considerations: treating null values and objects
3. Naive Approach
Normally, we’d use the Arrays.deepEquals() method. This solution is great when we need an out of the box solution. In our case, its complexity is the same as the below approach, O(m*n).
Another way to approach this problem is, naturally, the first we can think of. Consequently, we’re going to go through each array and compare each element to its correspondent.
First, let’s see what this solution looks like and then, we’ll explore it in more detail:
public static boolean areArraysEqual(int[][] arr1, int[][] arr2) {
if (arr1 == null || arr2 == null || arr1.length != arr2.length) {
return false;
}
for (int i = 0; i < arr1.length; i++) {
// check if rows have different lengths
if (arr1[i] == null || arr2[i] == null || arr1[i].length != arr2[i].length) {
return false;
}
for (int j = 0; j < arr1[i].length; j++) {
if (arr1[i][j] != arr2[i][j]) {
return false;
}
}
}
return true;
}
As we can see, we’re using a loop within a loop. This means the time complexity (big O notation) will be O(m*n) where m and n represent the number of rows and columns, respectively. Additionally, the space complexity will be O(1) because the memory needed to solve this problem doesn’t increase with the input size.
The advantages of this approach are:
easy to understand and implement
works for various-sized arrays (jagged arrays)
stops immediately once the first discrepancy is identified
The disadvantages are:
poor time complexity
not optimized
One important aspect is that we need to change our approach when dealing with objects. First, the != comparison won’t work for objects. Second, we’ll need to use the equals() method and make sure the objects we’re comparing have overwritten this method. Finally, we’ll also need to take into consideration null values.
4. Efficient Solution
Now, let’s think of another solution. This solution is useful for large arrays where we can accept some differences between the two arrays.
First, we’ll need two double parameters, let’s name them similarityThreshold and samplingWeight. Setting the similarityThreshold with a higher value allows for fewer different elements, while a smaller value allows for more different elements. On the other hand, the samplingWeight gives us control over the number of comparisons to perform.
This solution has the same time complexity of O(m*n) as the naive one in its worst case when the samplingWeight is set to its maximum. The maximum is 1, representing 100%, and all elements are compared.
Now, let’s look at our algorithm. First, we do some basic checks to see if the references point to the same object, are null, or have different lengths:
Next, we’ll calculate the sampling step based on the sampling weight:
int step = Math.max(1, (int)(1 / samplingWeight));
// Iterate through the arrays using the calculated step
for (int i = 0; i < arr1.length; i += step) {
for (int j = 0; j < arr1[0].length; j += step) {
if (Math.abs(arr1[i][j] - arr2[i][j]) <= 1) {
similarElements++;
}
checkedElements++;
}
}
Using this, the algorithm knows how many elements to step over before performing the next comparison. This means that the smaller the samplingWeight, the faster the algorithm will be. However, the drawback here is the smaller the samplingWeight, the bigger the chance to skip over different elements.
Finally, we divide the similar elements identified by the checked elements to calculate the similarity ratio and compare it with the previously set threshold:
In this article, we looked at how to compare two 2d arrays in Java. Moreover, we learned the importance of this comparison and its use in various fields.
We saw that the simplest and safest way is to compare each element at each position or use the Arrays.deepEquals() method. These solutions have the highest accuracy but also perform the most steps when the arrays are identical.
Next, we’ve seen a different solution, suitable for larger data sets. This solution can be much faster but with poorer accuracy. It’s up to us to determine which solution fits our needs.
Quarkus is a Java-based framework for building Jakarta EE and MicroProfile-based applications, mostly around REST services. To make accessing these easier, Quarkus provides a REST client that allows us to access such REST services using a typesafe proxy object.
When REST resources are protected, we need to authenticate ourselves. In REST/HTTP this is typically done by sending HTTP headers containing our credentials. Unfortunately, the REST client API does not contain any methods to provide security details or even HTTP headers with a request.
In this tutorial, we’ll look at accessing a protected REST service via the Quarkus (MicroProfile) REST Client. Quarkus provides a simple way to provide credentials for basic authentication: the @ClientBasicAuth annotation.
2. Setup Protected Services
Let’s first go through the setup of a protected service using Quarkus.
Let’s consider the following REST service interface:
public class MyServiceImpl implements MyService {
@Override
@RolesAllowed("admin")
public String hello() {
return "Hello from Quarkus REST";
}
}
The @RolesAllowed annotation is on the implementation class and not on the interface. Surprisingly, this is required since the @RolesAllowed annotation isn’t inherited from an interface. However, this may not be so bad as the role name can be considered an internal detail that should not be exposed.
By default, when we enable security, Quarkus activates the basic authentication mechanism. However, we must provide an identity store (IdentityProvider in Quarkus). Basically, we can do this by providing it on the classpath. In this case, we’ll use a simple property file-based identity store by putting the following in pom.xml:
This activates security (via its transitive dependencyio.quarkus:quarkus-elytron-security) and puts the above-mentioned identity store on the classpath. We can add users with their passwords and roles to this store using properties in application.properties:
This creates a proxy for the REST service, which we can then invoke just as we’d invoke local classes.
One way to provide security credentials involves annotating the original Jakarta REST interface with @ClientHeaderParam. Another way is to extend from this original interface and put the annotation there. In both cases, we have to manually (via code) generate the correct header using a callback method specified by the annotation. Since we’re using basic authentication we can take advantage of the @ClientBasicAuth annotation.
To provide username/password credentials for basic authentication using @ClientBasicAuth, we create a new interface type specific to a given user. There is therefore no dynamic aspect to the username and password. Every type created this way corresponds to a specific user. This is useful when an application accesses a remote service using one or more statically defined system users.
Using the code above the Quarkus RestClientBuilder generates the right headers to access the REST service using basic authentication. Notably, we use constants here for simplicity. In practice, we can use expressions like ${john.password} to refer to config properties.
4. Conclusion
In this article, we saw how to set up a REST service protected by basic authentication, and how to subsequently access such a service using the @ClientBasicAuthentication annotation.
We saw that using this @ClientBasicAuthentication annotation we don’t have to modify the existing REST interface. However, we also observed that we set up static (pre-defined) users in this way; @ClientBasicAuthentication does not suit dynamic input.
As usual, all code samples used in this article are available over on GitHub.
In JPA, CAST and TREAT are two distinct keywords used to manipulate data types and entity relationships. In this tutorial, we’ll explore the differences between CAST and TREAT and look at examples to illustrate their usage.
2. CAST in JPA
The CAST operator in JPA is primarily used for type conversions within JPQL queries. It allows us to explicitly convert a value from one data type to another. For instance, we can use CAST to convert a String to an Integer or vice versa.
Here’s the syntax for CAST:
CAST(expression AS type)
expression is the value or field that we want to convert, and type is the target data type to which we want to convert the expression.
3. TREAT in JPA
In contrast, the TREAT operator is designed for type-safe downcasting of entities within JPQL queries. It’s particularly useful when dealing with inheritance hierarchies. When we use TREAT, we specify a subtype of the entity, and JPA checks if the actual entity is indeed of that type.
Unlike CAST, TREAT doesn’t change the underlying data type of the value. Instead, it allows us to access the value as if it were of the target type.
Here’s the syntax for TREAT:
TREAT(expression AS type)
expression is the value to be treated, and type is the target data type.
4. Purpose and Usage
In JPA queries, both CAST and TREAT are used to handle type conversions, but they serve different purposes.
4.1. CAST Operator
The CAST is used to convert one data type into another for operations or comparisons. It’s often employed when performing queries that require a data type different from what’s stored in the database.
Consider an example where an entity called Employee, and the salary field is stored as a String in the database. Here’s how our Employee entity is defined:
@Entity
public class Employee {
@Id
private Long id;
private String salary;
// getters and setters
}
In this example, the salary field is of type String, but we may need to perform numeric operations or comparisons based on this field. To achieve this, we can use CAST to convert the salary field to an Integer type:
Employee emp1 = new Employee();
emp1.setId(1L);
emp1.setSalary("5000");
em.persist(emp1);
Query query = em.createQuery("SELECT CAST(e.salary AS Integer) FROM Employee e");
List<Integer> salaries = query.getResultList();
assertEquals(5000, salaries.get(0));
In this query, we use CAST to convert the salary field from a String to an Integer. The result of this query is a list of integers representing the salaries of employees.
4.2. TREAT Operator
On the other hand, TREAT is used for type-safe downcasting in inheritance. It allows us to work with entities in a way that acknowledges their actual subclass type, even when referenced through a base class.
Suppose we have an entity Vehicle with subclasses Car and Bike, and we want to retrieve only Car entities from a query that selects from Vehicle. We can use TREAT to ensure type safety:
@Entity
public class Vehicle {
@Id
private Long id;
private String type;
// getters and setters
}
@Entity
public class Car extends Vehicle {
private Integer numberOfDoors;
// getters and setters
}
To achieve this, we use the TREAT operator in our JPQL query to cast Vehicle instances to Car instances:
Vehicle vehicle = new Vehicle();
vehicle.setId(1L);
vehicle.setType("Bike");
Car car = new Car();
car.setId(2L);
car.setType("Car");
car.setNumberOfDoors(4);
em.persist(vehicle);
em.persist(car);
Query query = em.createQuery("SELECT TREAT(v AS Car) FROM Vehicle v WHERE v.type = 'Car'");
List<Car> cars = query.getResultList();
assertEquals(4, cars.get(0).getNumberOfDoors());
In this query, TREAT allows us to treat each Vehicle as a Car where applicable. The result is a list of Car instances, even though the underlying entities in the database are of type Vehicle.
5. Exception Handling
When dealing with type conversions and entity casting. Both CAST and TREAT operators have specific behaviors regarding exception handling,
5.1. CAST Operator
When using the CAST operator, exceptions can occur if the data conversion isn’t possible. This usually happens when there’s an attempt to convert a value to a type that it can’t be transformed into due to incompatible formats or data types.
Suppose an Employee entity has a salary value of “5ooo” (which isn’t a valid integer). When we execute a query to cast this String to an Integer, the database attempts to convert this value, leading to a JdbcSQLDataException if the conversion fails:
Employee emp1 = new Employee();
emp1.setId(1L);
emp1.setSalary("5ooo");
em.merge(emp1);
try {
Query query = em.createQuery("SELECT CAST(e.salary AS Integer) FROM Employee e");
query.getResultList(); // This should throw an exception
fail("Expected a JdbcSQLDataException to be thrown");
} catch (PersistenceException e) {
assertTrue(e.getCause() instanceof JdbcSQLDataException,
"Expected a JdbcSQLDataException to be thrown");
}
In this test, we’re asserting that a JdbcSQLDataException is thrown when attempting to cast an invalid string value.
5.2. TREAT Operator
In contrast, the TREAT operator handles type-safe downcasting in inheritance hierarchies. Unlike CAST, TREAT typically doesn’t throw exceptions when it encounters an issue with type casting. Instead, it returns an empty result set if no entities of the specified subclass type are found.
Suppose we query for Car instances among Vehicle entities, but the only vehicles available are of type Bike. In this case, the query doesn’t throw an exception but returns an empty result set instead:
Query query = em.createQuery("SELECT TREAT(v AS Car) FROM Vehicle v WHERE v.type = 'Bike'");
List<Car> cars = query.getResultList();
assertEquals(0, cars.size());
In this example, we’re querying for Car entities, but since no matching Car instances exist (only Bike instances are present), TREAT returns an empty list. This approach avoids exceptions and provides a clean way to handle type-safe casting by gracefully handling cases where no entities match the desired subclass type.
6. Criteria API
In the Criteria API, CAST isn’t directly supported. However, we can perform type conversions implicitly using expressions and the as() method, provided the types are compatible. For example, we can convert a field from one type to another if the types are directly compatible.
Here’s how we can use the as() method to cast an expression from one type to another, provided the types are compatible:
In this example, we retrieve the salary as a String and use the as() method to cast it to an Integer. This approach works when types are compatible, but direct CAST operations aren’t natively supported in the Criteria API.
On the other hand, TREAT is supported in the Criteria API and provides built-in functionality for type-safe downcasting. We can use TREAT to handle entity inheritance hierarchies by specifying a subtype. This example shows how to use TREAT with CriteriaBuilder:
In this example, TREAT is used to cast Vehicle entities to Car instances, ensuring type safety and allowing us to work with the Car subclass directly.
7. Summary
Here’s a table that highlights the key differences between CAST and TREAT in JPA:
Feature
CAST
TREAT
Purpose
Converts a scalar value from one type to another
Downcasts an entity or collection of entities in an inheritance hierarchy to a more specific subtype
Common Usage
Primarily used for basic type conversions, such as converting a String to an Integer
Used for polymorphic queries where a base class (superclass) needs to be treated as a subclass
Supported by JPA
Not directly supported in JPA
Fully supported in JPA
Scope
Applies to basic data types
Applies to entity types within an inheritance hierarchy
8. Conclusion
In this article, we’ve explored the difference between CAST and TREAT. CAST and TREAT are two distinct keywords in JPA that serve different purposes. CAST is used to convert between primitive types, while TREAT is used to treat an instance as if it were of a different type.
As always, the code discussed here is available over on GitHub.
In this tutorial, we’ll learn how to check if an element exists using Selenium WebDriver.
For most checks, it’s better to use explicit waits to ensure that elements are presentor visible before interacting with them. However, there are times when we need to simply know if an element exists without making assertions, enabling us to implement special additional logic based on the presence or absence of an element.
By the end of this tutorial, we’ll know how to check the presence of elements.
2. Using the findElements() Method
The findElements() method returns a list of web elements that match the By conditions. If no matching elements are found, it returns an empty list. By checking if the list is empty, we can determine whether the desired element exists:
It’s a clean and effective solution for many scenarios.
3. Using the findElement() Method
The findElement() method is another commonly used approach to locate elements on a web page. It returns a single web element if it’s present. It throws a NoSuchElementException if the element isn’t present.
To handle scenarios where the element might not exist, we should use a try-catch block to catch the exception. If the exception is thrown, it means the element is not present, so we catch it and return false. This method is useful when we’re certain that the presence of a single element is critical for the next steps in our test and we want to handle its absence explicitly.
By catching the NoSuchElementException, we can log an appropriate message, take corrective actions, or gracefully exit the test without crashing our script:
In this article, we’ve explored two essential methods for checking the existence of elements using Selenium WebDriver: findElements() and findElement() with exception handling. These methods help us know if an element exists without failing a test.
However, if we need to assert the presence of an element, we should use explicit waits with ExpectedConditions. By exploring and understanding these various approaches, we can confidently select the most appropriate method.
As always, the source code for the examples is available over on GitHub.
Working with JSON in Java often requires accessing nested keys. Jackson, a popular JSON processing library, provides a convenient way to achieve this using the findValue() method.
In this tutorial, we’ll explore using the findValue() method to retrieve values for nested keys.
2. Understanding Nested Keys in JSON
JSON objects can have nested structures, making it challenging to access deeply nested values:
Here we’ve used asText() to convert the JsonNode containing the email into a string.
4. Handling Missing Keys Gracefully
When working with JSON, we may encounter scenarios where a key is missing. The findValue() method returns null when the key isn’t found in the JSON structure.
Consider the following JSON where the email key is missing:
In this example, findValue(“email”) returns null because the email key isn’t in the JSON. Furthermore, we can verify this by asserting that emailNode is null:
assertNull(emailNode);
5. Using the findValue() Method With Arrays
The findValue() method also works with arrays in JSON:
Here, the findValues() method returns a list of JsonNode objects containing an email address. Then we convert these nodes to strings and collect them into a list and check it has the expected email addresses in the correct order.
6. Handling Deeply-Nested Keys
Rather than find a key by name somewhere in the JSON structure, we can use the at() method to target fields in deeply nested JSON structures at a specific path.
Here, the path provided to the at() method is a JSON Pointer, which is a standardized way to navigate through a JSON document using string syntax.
7. Conclusion
Jackson’s findValue() method offers a powerful and flexible way to retrieve values for nested keys in JSON.
Whether dealing with deeply nested objects or arrays, findValue() simplifies the process and enhances code readability and maintainability. However, for the precise location of a field, we can use the at() function with a JSON path.
As usual, we can find the full source code and examples over on GitHub.
In this tutorial, we’ll learn how to use the Jmix Studio and Jmix Framework for IntelliJ IDEA. We’ll build a full-stack MVP for a Spring Boot application that tracks employee expenses. From quickly setting up our project environment to generating responsive UIs and implementing role-based access, we’ll see how this framework accelerates development while preserving flexibility.
2. Project Overview and Setup
Our MVP is a web application where employees register their expenses. Admins define a few basic types of expenses like lunch, taxi, and airfares, while employees pick from these and include details like the amount spent, a date, and any other necessary details. We’ll also include authorization roles to differentiate between admins and employees so employees can only register expenses for themselves, but admins have full access to any user’s expenses.
With a few clicks in Jmix Studio, we’ll include rich and responsive UIs for administering users and expenses. These will include advanced search filters and basic form validation out of the box:
2.1. Enrivonment Setup
Jmix requires an account. So, after starting one for free, we’ll install these tools to set up our environment:
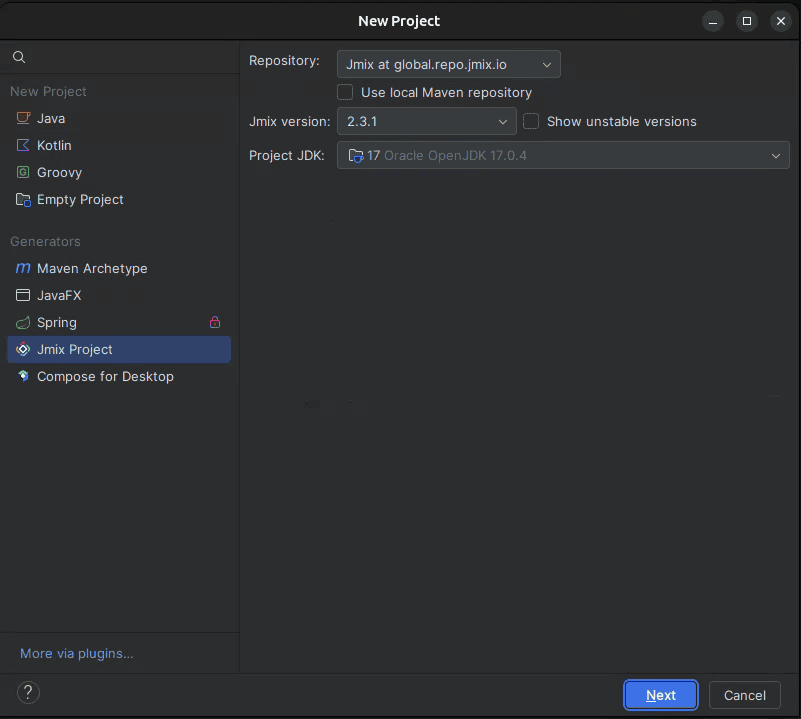
With our tools ready, we’ll open IntelliJ and see that a new “Jmix Project” option is now available:
We’ll choose “Full-Stack Application (Java)” and click next. Then, we’ll select a project name and a base package, and that’s it. We must wait until all dependencies are downloaded and the project is indexed.
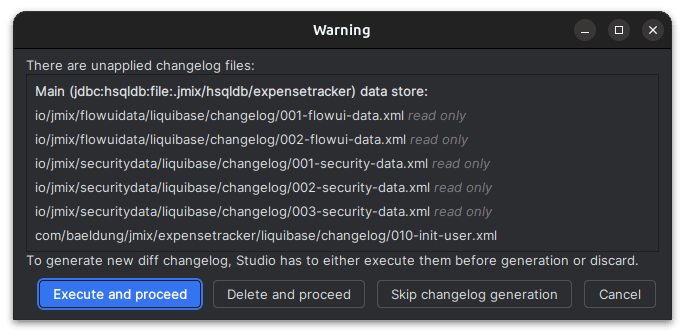
Most importantly, the first time we create a Jmix project, we’ll get a sign-in dialog. After signing in, let’s click on the Jmix button in IntelliJ’s sidebar to see what our project structure looks like:
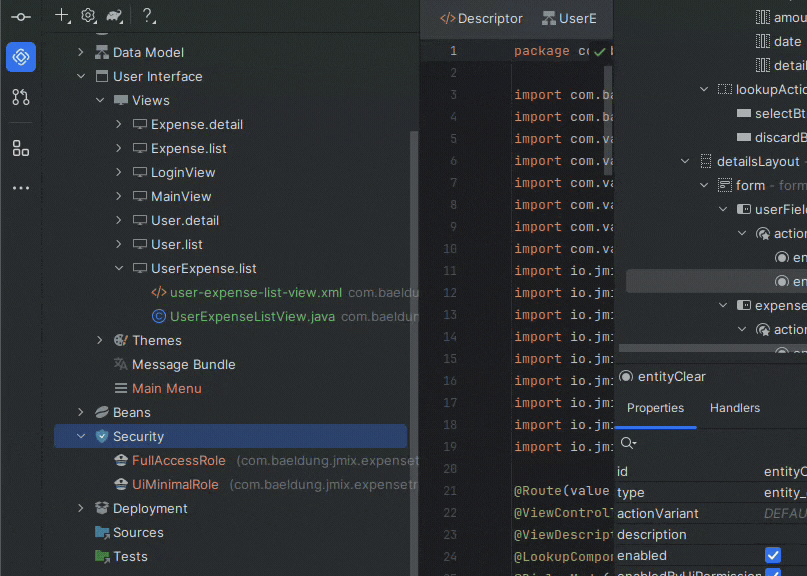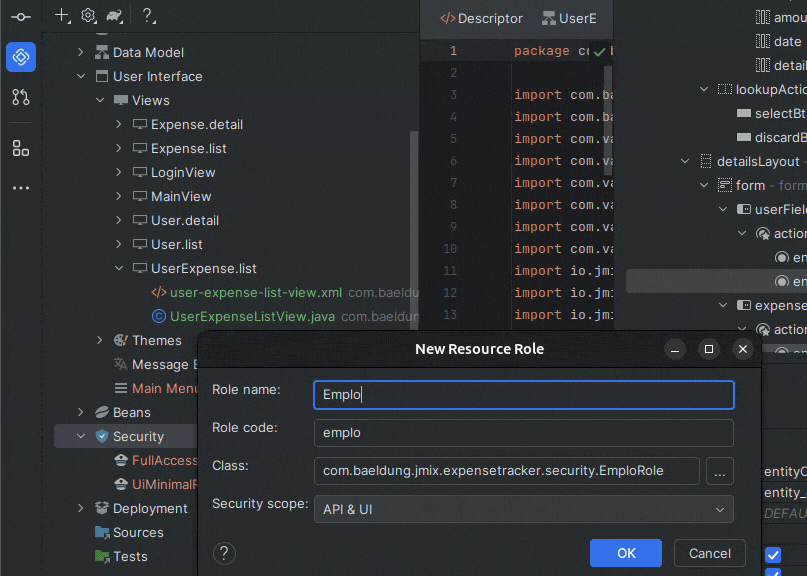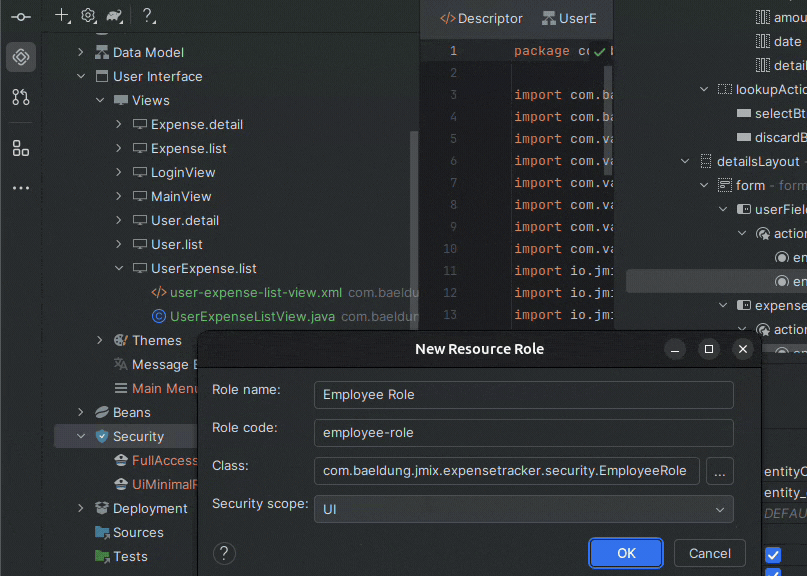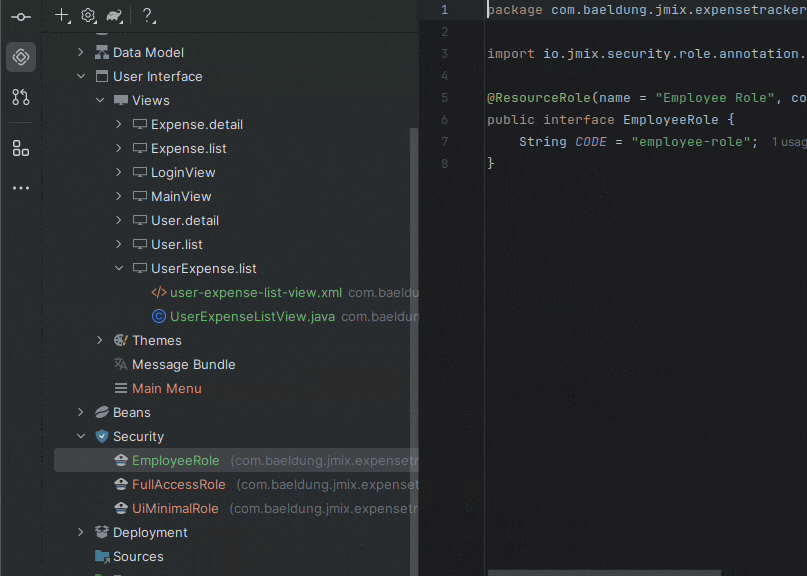
The structure includes basic functionalities like a User entity (which will represent employees), a few UI views, and basic authentication/authorization features. It also consists of a message bundle for internationalization and a basic CSS theme. Accessing the project structure via the Jmix plugin also allows shortcuts for various actions like new views or entities.
Also, it’s a regular Spring Boot app, so it’s familiar and easy to modify. Most importantly, it’s easy for those new to Spring Boot to navigate the project and see how things work.
3. Creating New Entities
Creating a new entity is as simple as focusing on the plugin’s panel, clicking the plus sign, and selecting “New JPA Entity…” We need to choose the class name and make sure “Entity” is selected for the entity type field. The plugin also lets us choose the ID type, which is UUID by default. Jmix also recommends checking the “versioned” option because it activates optimistic locking for entities.
Also, after creating our entity, we can add new attributes by clicking on the plus sign in the attributes section. Let’s start with an Expense entity to represent common types of expenses:
And since Jmix already adds the id and version attributes, we’ll only add the name attribute with type String for now. Most importantly, creating an entity via the Studio also generates Liquibase changelogs to create or modify database objects for us.
When adding new properties, most options are self-explanatory, but there are a few noteworthy mentions:
Read-only: doesn’t create a setter for the property, and it won’t be editable in the UI
Mandatory: creates a non-null constraint in the database and is checked in the UI
Transient: It doesn’t create a column in the database, and it’s not shown in the UI
With our Expense entity still open, we’ll switch to the “Text” tab to find the generated code, which mixes JPA annotations with Jmix-specific ones:
Changes to the code are reflected in the “Designer” tab, and vice-versa. Also, we can use the JPA dev tools via the code editor’s inline actions. Let’s see the options that appear when we alt+enter on any line:
These options also appear in the top panel.
3.1. Adding a CRUD UI for an Entity
While focusing on an entity in the Designer, let’s click on “Views,” “Create view,” then “Entity list and detail views,” which creates a page for listing and filtering existing items and a page for creating/viewing/editing items. We can develop UIs for entities with complete CRUD functionality without touching any code:
The wizard suggests good enough defaults and goes through a few key options:
Entity: any of the @JmixEntity annotated classes. Defaults to the currently selected one
Package name: defaults to the base package selected at project creation + view + the entity’s name
Parent menu item: defaults to the one created along with the project
Table actions: defaults to all CRUD actions
Create a generic filter: this allows us to perform basic search filtering in the list view
Fetch plan: defaults to fetching all columns from the row (excluding foreign keys)
Localizable messages: allows us to change the titles of the two pages we’re creating
3.2. Creating Enumerations
We’ll limit expenses to a few categories. To do this, we’ll create an enum named ExpenseCategory with a few options:
Education
Food
Health
Housing
Transportation
Let’s create this with the “New Enumeration” option:
We can then add the ExpenseCategory to our Expense entity as a new mandatory attribute, choosing “ENUM” as the attribute type:
Since we created this attribute after creating our view, we can add it with the “Add to Views” button and choose in which views we want to see this property. This generates a select tag added to the detail view:
After completing the wizard, let’s launch the application. Jmix Studio automatically analyzes the data model against the data schema and generates Liquibase scripts with the changes, so we’ll see a dialog presenting the scripts to apply, and we only need to execute them to proceed:
After that, let’s check out our “Expenses” UI in the “Application” menu:
Note that we can already manage Expense items and that the UI is responsive. Also, we get the credentials filled out when logging in. This behavior is helpful for testing and is added in the application.properties:
Creating a unique constraint for expense names is a good idea to avoid duplications. When adding it via the plugin, it’s added to our Java class with the @UniqueConstraint annotation, which also includes validation in the UI:
Again, the generated Liquibase changelog takes care of adding it to the database:
We can personalize the error message for when the constraint is violated by switching to the Jmix panel, navigating to “User Interface” in the project structure, and then opening “Message Bundle.” All the messages from the application are there. Let’s add a new one:
databaseUniqueConstraintViolation.IDX_EXPENSE_UNQ=An expense with the same name already exists
Jmix recognizes a few particular prefixes for localization messages. For unique constraint violations, we have to start our message key with “databaseUniqueConstraintViolation.”, followed by our constraint name in the database, IDX_EXPENSE_UNQ.
4. Adding an Entity With Reference Attributes
We’ll need a new entity to represent an employee’s Expense. The plugin supports adding reference attributes, so let’s create a UserExpense entity and associate it with a reference to an Expense, a User, and related attributes:
NAME
ATTRIBUTE TYPE
TYPE
CARDINALITY
MANDATORY
user
ASSOCIATION
User
Many to One
true
expense
ASSOCIATION
Expense
Many to One
true
amount
DATATYPE
Double
–
true
date
DATATYPE
LocalDate
–
true
details
DATATYPE
String
–
false
Our new entity also uses the “versioned” option:
Opening our newly created entity, we can see how Jmix uses familiar JPA annotations and indexes our foreign keys:
@JmixEntity
@Table(name = "USER_EXPENSE", indexes = {
@Index(name = "IDX_USER_EXPENSE_USER", columnList = "USER_ID"),
@Index(name = "IDX_USER_EXPENSE_EXPENSE", columnList = "EXPENSE_ID")
})
@Entity
public class UserExpense {
// standard ID and version fields...
}
Moreover, it uses FetchType.LAZY for the associations instead of the EAGER default so we don’t accidentally compromise performance. Let’s check the generated User association:
The association uses JPA annotations, so it’s easy to change later if necessary.
4.1. Adding Date Validation
When we head over to the “Attributes” section in the Designer and choose a date property, we notice a few validation options appear. Let’s click on “not set” to set it for PastOrPresent. We can include a localized message by clicking the globe icon instead of using a literal message:
This validation blocks users from creating expenses with a future date. Including this annotation also turns off the selection of future dates for the date picker component that Jmix creates in our views.
4.2. Creating a Master-Detail View
We’ve created a list view and a detail view for the Expense entity. Now, for the UserExpense entity, let’s try the Master-detail view, which combines both in a single UI. This time, in the entity list/detail fetch plan, we’ll add the expense property to include them in the initial query that lists all user expenses. And, only for the detail fetch plan, we’ll add the user property so we can query all the information necessary to open details for an expense:
As before, we’ll find our new view in the application menu, under “User expenses,” ready to include some items:
Inspecting the generated code for user-expense-list-view.xml, we’ll notice how the plugin already included complex components for us, like a date picker, so we don’t have to bother with frontend stuff:
<datePicker id="dateField" property="date"/>
However, this page gives full access to any user in the application. We’ll see how to control access later.
4.3. Adding Composition Attributes
Now, let’s go back to the User entity and include an expenses attribute to list user expenses in our details view for quick reference. We’ll do this by adding a new attribute with the “composition” type and choosing UserExpense with one-to-many cardinality:
To add it to the user detail view, select the expenses attribute in the Designer and click the “Add to Views” button, checking its box in the User.detail layout view:
If we check user-detail-view.xml, we’ll see that Jmix added a fetchPlan for the expenses attribute:
Fetch plans help avoid the N+1 problem by including any necessary joins in the initial query instead of making extra queries. We’ll also find a data container for binding to view objects:
<collection id="expensesDc" property="expenses"/>
And a data grid element that allows CRUD operations on expenses:
These are all defined with Jmix’s declarative layout tags and components.
4.4. Adding Fetched Columns to an Existing View
Let’s explore how this declarative layout definition works by adding properties from the Expense class to the expensesDataGrid component we’ve created. First, we’ll open user-detail-view.xml and select the data grid. Then, in the Jmix UI panel, we click on columns and select “Add” and “Column.” Finally, let’s choose the name and category properties from the expense object:
Besides the data grid receiving the new column elements, the fetch plan now includes the expense object:
As a result, we’ll now see a data grid of user expenses directly when accessing the User detail view.
4.5. Hot Deploy
With Jmix Studio, most simple changes – like the new columns we added – are hot deployed, so we don’t need to relaunch our application to see the changes; a page refresh is enough:
Updates are applied automatically when developing with Jmix locally.
5. Setting Up User Permissions
When accessing the application, we see the initial security roles created along with the project in the “Resource roles” menu under “Security.” These include a full-access role and a minimal role that only accepts logging in to the application.
We’ll create a role so employees can access the UserExpense menu and manage their expenses. Then, we’ll create a row-level access role to restrict users so they can only retrieve items that match their ID. This restriction guarantees that users can only see their own expenses.
5.1. Creating a New Resource Role
Resource roles control access to specific objects (like entities, entity attributes, and UI views) and operations in the project requested via the UI or the API. Since we’re only using views, let’s create one named EmployeeRole by right-clicking the “Security” node in Jmix, choosing “New,” and ensuring we mark the security scope as “UI”:
The role starts empty, containing only the code that’ll also appear in the UI:
So, on our EmployeeRole page, let’s click Entities to define what operations on entities this role will permit. We’ll need all actions on UserExpense, except for deletion, reading and updating on User, and reading on Expense, so that we can select one of the available expense types when registering our own:
ENTITY
CREATE
READ
UPDATE
Expense
X
User
X
X
UserExpense
X
X
X
Then, in the User Interface tab, we’ll select the views this role has access to. Since views can be interconnected, this page allows selecting between view access (via a component on the page) or menu access. Our UserExpense view is connected to the User view (for showing their details) and to the Expense view (for listing available expense types), so we’ll check “View” for User.list, Expense.list, and UserExpense.list. Finally, for the UserExpense.list, we’ll also check “Menu,” making it accessible via the UI:
5.2. Creating a New Row-Level Role With a JPQL Policy
To ensure employees can only see their own expenses when accessing the menu, we’ll create a row-level policy that’ll restrict every query only to fetch rows matching the ID of the logged-in User.
To do this, we’ll also need to add a JPQL policy. So, let’s create a row-level role named EmployeeRowLevelAccessRole by right-clicking the “Security” node in Jmix and choosing “New.” Then, in our newly created role, we’ll click “Add Policy” and then “Add JPQL Policy” to add policies for the entities that reference User:
Entity: UserExpense; where clause: {E}.user.id = :current_user_id
Entity: User; where clause: {E}.id = :current_user_id
When adding JPQL policies, {E} represents the current entity. We also get a few unique variables, like current_user_id, which resolves to the one currently logged in. Auto-complete is available in the plugin, so we can easily find our way around.
In the end, we can assign these roles to any users via the UI by accessing “Resource roles” and “Row-level roles” in the “Security” menu. Or, more conveniently, by using the “Role assignments” button in the list view, where we can add both roles to anyone in the list:
Users with these roles can now access the Expense list view and register their expenses. Most importantly, they won’t have access to expenses from others.
6. Conclusion
In this article, we demonstrated how to easily create a functional and secure web application, highlighting Jmix Studio’s potential to significantly accelerate our development cycle while maintaining high functionality and user experience standards. The comprehensive support for CRUD operations, role-based access control, and validation ensures security and usability.
In this article, we’ll focus on understanding the switchIfEmpty() operator in Spring Reactive and its behavior with and without the defer() operator. We’ll explore how these operators interact in different scenarios, providing practical examples to illustrate their impact on reactive streams.
2. Use of switchIfEmpty() and Defer()
The switchIfEmpty() is an operator in Mono and Flux that executes an alternate producer flow if the source producer is empty. If the primary source publisher emits no data, this operator switches to data emissions from an alternate source.
Let’s consider an endpoint that retrieves user details by ID from a large file. Each time someone requests user details from the file, iterating through the file consumes a lot of time. Thus, it makes more sense for frequently accessed IDs to have their details cached instead.
When the endpoint receives a request, we’ll first search the cache. If the user details are available, we’ll return the response. If not, we’ll fetch the data from the file and cache it for subsequent requests.
In this context, the primary data provider is the flow that checks for the key’s existence in the cache, while the alternative is the flow that checks the key in the file and updates the cache. The switchIfEmpty() operator can efficiently switch the source provider based on the availability of data in the cache.
It’s also important to understand the use of the defer() operator, which defers or delays the evaluation of a function until a subscription occurs. When we do not use the defer() operator with switchIfEmpty(), the expression evaluates immediately (eagerly), potentially causing unexpected side effects.
3. Setup
Let’s explore the example further to understand the behavior of the switchIfEmpty() operator under different circumstances.
We’ll implement the necessary code and analyze the system logs to determine whether we fetch the user from the cache or the file.
3.1. Data Model
First, let’s define a user model that contains a few details like id, name, email, roles:
public class User {
@JsonProperty("id")
private String id;
@JsonProperty("email")
private String email;
@JsonProperty("username")
private String username;
@JsonProperty("roles")
private String roles;
// standard getters and setters...
}
3.2. User Data Setup
Subsequently, let’s maintain a file in the classpath(users.json) that contains all the user details in a JSON format:
In the following step, let’s add a controller that retrieves user details by ID. It will accept an optional boolean parameter withDefer, and involve different implementations based on this query parameter:
Then, let’s define these two implementations in UserService, with and without defer(), to understand the behavior of switchIfEmpty():
public Mono<User> findByUserIdWithDefer(String id) {
return fetchFromCache(id).switchIfEmpty(Mono.defer(() -> fetchFromFile(id)));
}
public Mono<User> findByUserIdWithoutDefer(String id) {
return fetchFromCache(id).switchIfEmpty(fetchFromFile(id));
}
For simplicity, let’s implement an in-memory cache to retain user information as the primary data provider for requests. We’ll also log each access, which allows us to determine whether the cache retrieved the data:
private final Map<String, User> usersCache;
private Mono<User> fetchFromCache(String id) {
User user = usersCache.get(id);
if (user != null) {
LOG.info("Fetched user {} from cache", id);
return Mono.just(user);
}
return Mono.empty();
}
Following that, let’s fetch user details from the file when the ID is not in the cache and update the cache if the data is found:
private Mono<User> fetchFromFile(String id) {
try {
File file = new ClassPathResource("users.json").getFile();
String usersData = new String(Files.readAllBytes(file.toPath()));
List<User> users = objectMapper.readValue(usersData, new TypeReference<List<User>>() {
});
User user = users.stream()
.filter(u -> u.getId()
.equalsIgnoreCase(id))
.findFirst()
.get();
usersCache.put(user.getId(), user);
LOG.info("Fetched user {} from file", id);
return Mono.just(user);
} catch (IOException e) {
return Mono.error(e);
}
}
Note the logging details to assert if user data was retrieved from the file.
4. Testing
Let’s add a ListAppender in the @BeforeEach test method to track the logs. We’ll use it to determine whether the cache or the file executes the function for different requests:
We can add some tests to validate various conditions in the following sections.
4.1. switchIfEmpty() With defer() on Non-Empty Source
We’ll verify that the implementation retrieves user data from the cache only when the request has the withDefer parameter set to true and we’ll assert the logger output accordingly:
@Test
void givenUserDataIsAvailableInCache_whenUserByIdIsRequestedWithDeferParameter_thenCachedResponseShouldBeRetrieved() {
usersCache = new HashMap<>();
User cachedUser = new User("66b29672e6f99a7156cc4ada", "gwen_dodson@beadzza.bmw", "boyle94", "admin");
usersCache.put("66b29672e6f99a7156cc4ada", cachedUser);
userService.getUsers()
.putAll(usersCache);
webTestClient.get()
.uri("/api/v1/user/66b29672e6f99a7156cc4ada?withDefer=true")
.exchange()
.expectStatus()
.isOk()
.expectBody(String.class)
.isEqualTo("{\"id\":\"66b29672e6f99a7156cc4ada\"," +
"\"email\":\"gwen_dodson@beadzza.bmw\",\"username\":\"boyle94\",\"roles\":\"admin\"}");
assertTrue(listAppender.list.stream()
.anyMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from cache")));
assertTrue(listAppender.list.stream()
.noneMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from file")));
}
When we use switchIfEmpty() with the defer() operator, the alternative source provider doesn’t get evaluated eagerly.
4.2. switchIfEmpty() Without defer() on Non-Empty Source
Let’s add another test to check the behavior of using switchIfEmpty() without the defer() operator:
@Test
void givenUserDataIsAvailableInCache_whenUserByIdIsRequestedWithoutDeferParameter_thenUserIsFetchedFromFileInAdditionToCache() {
usersCache = new HashMap<>();
User cachedUser1 = new User("66b29672e6f99a7156cc4ada", "gwen_dodson@beadzza.bmw", "boyle94", "admin");
usersCache.put("66b29672e6f99a7156cc4ada", cachedUser1);
userService.getUsers().putAll(usersCache);
webTestClient.get()
.uri("/api/v1/user/66b29672e6f99a7156cc4ada?withDefer=false")
.exchange()
.expectStatus()
.isOk()
.expectBody(String.class)
.isEqualTo("{\"id\":\"66b29672e6f99a7156cc4ada\"," +
"\"email\":\"gwen_dodson@beadzza.bmw\",\"username\":\"boyle94\",\"roles\":\"admin\"}");
assertTrue(listAppender.list.stream()
.anyMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from file")));
assertTrue(listAppender.list.stream()
.anyMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from cache")));
}
As we can see, the implementation fetched the user details from both the cache and the file, but it ultimately served the response from the cache. The code block in the alternate source was triggered unnecessarily, despite emissions from the primary source (cache).
4.3. switchIfEmpty() With defer() on Empty Source
Following that, let’s add a test to verify that user details are retrieved from the file when there is no data in the cache, specifically when using the defer() operator:
@Test
void givenUserDataIsNotAvailableInCache_whenUserByIdIsRequestedWithDeferParameter_thenFileResponseShouldBeRetrieved() {
webTestClient.get()
.uri("/api/v1/user/66b29672e6f99a7156cc4ada?withDefer=true")
.exchange()
.expectStatus()
.isOk()
.expectBody(String.class)
.isEqualTo("{\"id\":\"66b29672e6f99a7156cc4ada\"
,\"email\":\"gwen_dodson@beadzza.bmw\",\"username\":\"boyle94\",\"roles\":\"admin\"}");
assertTrue(listAppender.list.stream()
.anyMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from file")));
assertTrue(listAppender.list.stream()
.noneMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from cache")));
}
The API fetches the user details from the file as intended, rather than attempting to retrieve them from the cache.
4.4. switchIfEmpty() Without defer() on Empty Source
Finally, let’s add a test to validate that the implementation retrieves user details from the file (i.e., no data in the cache) when used without defer():
@Test
void givenUserDataIsNotAvailableInCache_whenUserByIdIsRequestedWithoutDeferParameter_thenFileResponseShouldBeRetrieved() {
webTestClient.get()
.uri("/api/v1/user/66b29672e6f99a7156cc4ada?withDefer=false")
.exchange()
.expectStatus()
.isOk()
.expectBody(String.class)
.isEqualTo("{\"id\":\"66b29672e6f99a7156cc4ada\"," + "\"email\":\"gwen_dodson@beadzza.bmw\",\"username\":\"boyle94\",\"roles\":\"admin\"}");
assertTrue(listAppender.list.stream()
.anyMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from file")));
assertTrue(listAppender.list.stream()
.noneMatch(e -> e.toString()
.contains("Fetched user 66b29672e6f99a7156cc4ada from cache")));
}
As there is no data in the cache, the user details are not fetched from the cache but will be attempted as a side-effect but still the API fetches the user details from the file as intended.
5. Conclusion
In this article, we focussed on understanding the switchIfEmpty() operator in Spring Reactive and its various behaviors through tests.
Using switchIfEmpty() in conjunction with defer() ensures access to the alternative data source only when necessary. This prevents unnecessary computations and potential side effects.
As always, the source code for the examples is available over on GitHub.
In this tutorial, we’ll explore an interesting Java problem: mapping an Iterable to an object containing an Iterable using MapStruct.
MapStruct is a Java library that simplifies the process of mapping between different object models. However, it has limitations. This tutorial assumes that we already have a basic understanding of MapStruct. If not, we recommend starting with a quick guide to familiarize ourselves with its basic usage.
2. Understand the Use Case
Let’s begin with a simple example to explain the scenario. Consider a list of Employee objects and a Department object containing a list of employees. We’ll start by creating those classes:
public class Employee {
private String name;
private String phoneNumber;
// getters and setters
}
public class Department {
private List<Employee> employees;
// getters and setters
}
Now, let’s assume we want to map the list of Employee objects to a Department. We’ll create an interface, mark it as a mapper, and create a method annotated with the @Mapping annotation:
@Mapper
public interface DepartmentMapper {
@Mapping(target = "employees", source = "employees")
Department map(List<Employee> employees);
}
In the code above, we intuitively tried to define the source as our input list of employees and the target as the Employees of our Department class. Although this may seem like a straightforward approach, we’ll encounter an error that prevents our code from compiling. To resolve this issue, we’ll need to adjust our approach to ensure that the source type aligns with the target type.
3. Map Iterable to Non-Iterable Type
Let’s understand the root cause of this issue by looking at the error thrown by MapStruct:
java: Can't generate mapping method from iterable type from java stdlib to non-iterable type.
The error above indicates that we’re trying to map an iterable type (such as List, Set, or any Collection from the standard Java library) and a non-iterable type (a single object or primitive type). Such mapping is not natively supported and requires additional context or specific instructions.
There are a few practical reasons for this that the JVM and the MapStruct library are simply unable to solve independently:
How to match elements between source and target
Whether to remove or add unmatched elements
How to handle multiple matches
Additionally, we also need to consider how to maintain the correct sorting of elements.
4. Solution
When mapping an iterable to a non-iterable type using MapStruct, there isn’t a straightforward, one-size-fits-all solution. However, there are practical workarounds available that can help us achieve the desired outcome.
4.1. Default Interface Method
The first approach involves creating a default interface method within the mapper. This method will manually handle the conversion by taking our iterable and setting it as the field value within the target object. By doing this, we ensure that the mapping is handled as expected.
Let’s look at this approach in practice:
default Department map(List<Employee> employees) {
Department department = new Department();
department.setEmployees(employees);
return department;
}
4.2. Multiple Sources
Another method involves changing the mapping method by adding additional parameters. When we introduce another argument, MapStruct gains better context for what we’re trying to accomplish. Having multiple parameters, in other words, means we have multiple sources, so it will be easier to identify what needs to be mapped.
First, let’s introduce a new attribute to our Department class. That parameter will be of type Employee named manager:
public class Department {
private List<Employee> employees;
private Employee manager;
// omitted getters and setters
}
Next, let’s create a mapping method including this parameter as a source:
Since we’re no longer trying to map an iterable to a non-iterable type, the mapping works as expected. The MapStruct library now has sufficient context to generate a mapper implementation, which is why no errors are thrown during the code compilation step.
Note that even though this approach is clean and functional, it’s case-specific. We’re not always able to add new parameters in favor of mapping.
5. Conclusion
In this article, we discussed the challenges and solutions involved in using MapStruct to map an iterable to an object containing an iterable type. Although MapStruct is a powerful object mapping tool, it has limitations that require alternative approaches.
We explored several methods to handle these scenarios, including adding default interface methods that give us full control over the mapping process. Furthermore, we noticed that while multiple source mapping doesn’t encounter the issues mentioned in this article, it isn’t a helpful approach for every use case.
As always, full code examples are available over on GitHub.
Manipulating colors is fundamental to graphical programming, especially when designing user interfaces or graphical applications. The setColor() method, provided by Java’s Graphics class, is essential for setting the appearance of shapes, text, or other graphical elements.
To achieve the desired color, programmers often use RGB (Red, Green, Blue) values. In this article, we’ll learn how to add RGB values into setColor() in Java, including how to create custom shades.
2. Understanding RGB in Java
RGB, which stands for Red, Green, and Blue, represents the primary light components used in digital displays. By varying the intensity of each of these components, we can generate a wide range of colors perceivable by the human eye.
In Java, each channel (Red, Green, and Blue) is represented by an integer value ranging from 0 to 255, where:
0 represents no intensity (complete absence of that color)
255 represents full intensity
The combination of these three values determines the final color. For example:
Red: (255, 0, 0)
Green: (0, 255, 0)
Blue: (0, 0, 255)
Black: (0, 0, 0)
White: (255, 255, 255)
In Java, the Color class encapsulates these RGB values and provides a way to define colors programmatically. Additionally, Java supports transparency through an alpha channel, which allows defining colors with varying degrees of opacity.
3. Adding RGB Values into setColor()
In Java graphics programming, combining RGB values with the setColor() method allows control over the appearance of various graphical elements. To effectively manage colors in our graphics, we need to understand how to create and apply Color objects using RGB values. The following sections will guide us through these steps.
3.1. Creating a Color Object
The first step in using RGB values with the setColor() method is to create a Color object. The Color class in Java provides constructors that accept three parameters corresponding to the red, green, and blue components:
Color myWhite = new Color(255, 255, 255);
In this example, “myWhite” is a Color instance representing the color white. By adjusting the RGB values, we can create various colors to suit our application’s needs. For instance, to create a shade of purple, we can use:
Color myPurple = new Color(128, 0, 128);
3.2. Applying the Color with setColor()
Once we’ve created a Color object, the next step is to apply it to our graphical context using the setColor() method of the Graphics class. This method sets the color for all subsequent drawing operations:
graphic.setColor(myWhite);
In this example, “graphic” is an instance of the Graphics class. After calling setColor(myWhite), any shapes or text drawn will use the specified color. This allows us to manage and apply colors consistently throughout the graphical operations.
3.3. Example of Applying Multiple Colors
Let’s explore how to use multiple colors by creating and applying different Color objects as needed:
Color redColor = new Color(255, 0, 0);
graphic.setColor(redColor); // Sets the drawing color to red
graphic.fillRect(10, 10, 100, 100); // Draws a red rectangle
Color blueColor = new Color(0, 0, 255);
graphic.setColor(blueColor); // Sets the drawing color to blue
graphic.fillRect(120, 10, 100, 100); // Draws a blue rectangle
In this example, redColor and blueColor are Color objects representing red and blue colors, respectively. The setColor() method is used to switch between these colors for different drawing operations. The rectangles drawn by graphic.fillRect() will appear in red and blue according to the order in which the colors are set.
4. Conclusion
To effectively use RGB values with setColor(), we created a Color object with the desired RGB values. Then we applied this color using setColor() to control the appearance of subsequent graphical operations.
By mastering this technique, we can effectively control colors in our Java graphical applications, which helps us enhance our designs’ visual quality and functionality.
In Micronaut, similar to other Java frameworks, the Environment interface is an abstraction related to profiles. Profiles are a concept that we can think of as containers, that hold properties and beans specific to them.
Usually, the profiles are related to the execution environment, such as local-profile, docker-profile, k8s-profile, etc. We can use Micronaut environments to create different sets of properties, in .properties or .yaml files, depending on whether we execute our application locally, on the cloud, etc.
In this tutorial, we’ll go through the Environment abstraction in Micronaut and we’ll see different ways to set it properly. Last, we’ll learn how we can use the environment-specific properties and beans, and also how we can use environments to apply different implementations.
2. Micronaut Environments vs. Spring Profiles
If we’re familiar with Spring profiles, then understanding Micronaut environments is easy. There are many similarities, but also a few key differences.
Using Micronaut environments, we can set properties in similar ways as in Spring. This means we can have:
property files using the @ConfigurationProperties annotation
inject specific properties to a class using the @Value annotation
inject specific properties to a class by injecting the whole Environment instance and then use the getProperty() method
One confusing difference between Spring and Micronaut is that although both allow multiple active environments/profiles, in Micronaut it’s common to see many active environments, while in Spring profiles we rarely see more than one active profile. This leads to some confusion about properties or beans that are specified in many active environments. To overcome this, we can set environment priorities. More on that later.
Another difference worth noting is that Micronaut gives an option to disable environments completely. This isn’t relevant in Spring profiles, since when don’t set the active profile, the default is usually being used. In contrast, Micronaut might have different active environments set from different frameworks or tools used. For example:
JUnit adds in active environments the ‘test’ environment
Cucumber adds the ‘cucumber’ environment
OCI might add ‘cloud’ and/or ‘k8s’, etc.
In order to disable environments we can use java -Dmicronaut.env.deduction=false -jar myapp.jar.
3. Setting Micronaut Environments
There are different ways to set Micronaut environments. The most common ones are:
Using the micronaut.environments argument: java -Dmicronaut.environments=cloud,production -jar myapp.jar.
Using the defaultEnvironment() method in main(): Micronaut.build(args).defaultEnvironments(‘local’).mainClass(MicronautServiceApi.class).start();.
Setting the value in MICRONAUT_ENV, as an environmental variable.
As we noted earlier, environments sometimes are deducted, meaning set from frameworks in the background, like JUnit and Cucumber.
There are no best practices in the way we decide to set the environment. We can choose the one that best fits our needs.
4. Micronaut Environments Priority and Resolution
Since multiple active Micronaut environments are allowed, then there are cases in which a property or a bean might have been explicitly defined in more than one or none of them. This leads to conflicts and sometimes in runtime exceptions. The way properties and beans’ priority and resolution are handled is different.
4.1. Properties
When a property exists in multiple active property sources, the environment order determines which value it gets. The hierarchy, from lowest to highest order, is:
deduced environments from other tools/frameworks
environments set in the micronaut.environments argument
environments set in MICRONAUT_ENV environment variable
environments loaded in the Micronaut builder
Let’s assume we have a property service.test.property and we want to have different values for it, in different environments. We set the different values in application-dev.yml and application-test.yml files:
In the first test, we didn’t set any active environment, but there is the deducted test from JUnit. The property gets its value from application-test.yml in this case. But in the second example, we set in ApplicationContext, which has a higher order, the dev environment too. In this scenario, the property gets its value from application-dev.yml.
But if we try to inject a property that isn’t present in any of the active environments, we’ll get a runtime error, DependencyInjectionException, because of the missing property:
In this example, we try to retrieve a missing property, system.dummy.property, directly from the ApplicationContext. This returns an empty Optional. If the property was injected in some bean, it would have caused a runtime exception.
4.2. Beans
With environment-specific beans, things are a bit more complex. Let’s assume we have an interface EventSourcingService that has one method sendEvent() (it should have been void, but we return the String for demo purposes):
public interface EventSourcingService {
String sendEvent(String event);
}
There are only two implementations of this interface, one for environment dev and one for production:
@Singleton
@Requires(env = Environment.DEVELOPMENT)
public class VoidEventSourcingService implements EventSourcingService {
@Override
public String sendEvent(String event) {
return "void service. [" + event + "] was not sent";
}
}
@Singleton
@Requires(env = "production")
public class KafkaEventSourcingService implements EventSourcingService {
@Override
public String sendEvent(String event) {
return "using kafka to send message: [" + event + "]";
}
}
The @Requires annotation informs the framework that this implementation is only valid when one or more of the specified environment or environments are active. Or else, this bean is never created.
We can assume that the VoidEventSourcingService does nothing and only returns a String because maybe we don’t want to send events on dev environments. And KafkaEventSourcingService actually sends an event on a Kafka and then returns a String.
Now, what would happen if we forget to set in the active environments one or the other? In such a scenario, we’d be getting back a NoSuchBeanException exception:
public class InvalidEnvironmentEventSourcingUnitTest {
@Test
public void whenEnvironmentIsNotSet_thenEventSourcingServiceBeanIsNotCreated() {
ApplicationContext applicationContext = Micronaut.run(ServerApplication.class);
applicationContext.start();
assertThat(applicationContext.getEnvironment().getActiveNames()).containsExactly("test");
assertThatThrownBy(() -> applicationContext.getBean(EventSourcingService.class))
.isInstanceOf(NoSuchBeanException.class)
.hasMessageContaining("None of the required environments [production] are active: [test]");
}
}
In this test, we don’t set any active environments. First, we assert that the only active environment is test, which is deduced from using the JUnit framework. Then we assert that if we try to get the bean of the implementation of EventSourcingService, we actually get an exception back, with an error indicating that none of the required environments are active.
On the contrary, if we set both environments, we get an error again, because both implementations of the interface cannot be present at the same time:
public class MultipleEnvironmentsEventSourcingUnitTest {
@Test
public void whenEnvironmentIsSetToBothProductionAndDev_thenEventSourcingServiceBeanHasConflict() {
ApplicationContext applicationContext = ApplicationContext.builder("dev", "production").build();
applicationContext.start();
assertThat(applicationContext.getEnvironment()
.getActiveNames()).containsExactly("test", "dev", "production");
assertThatThrownBy(() -> applicationContext.getBean(EventSourcingService.class))
.isInstanceOf(NonUniqueBeanException.class)
.hasMessageContaining("Multiple possible bean candidates found: [VoidEventSourcingService, KafkaEventSourcingService]");
}
}
This is not a bug or bad coding. This can be a real-life scenario, in which we might want to have failures when we forget to set the proper environment. But if we want to make sure we never get runtime errors in such cases, we can set a default implementation, by not adding the @Requires annotation. For the environments that we want to override the default, we should add the @Requires and the @Replaces annotations:
public interface LoggingService {
// methods omitted
}
@Singleton
@Requires(env = { "production", "canary-production" })
@Replaces(LoggingService.class)
public class FileLoggingServiceImpl implements LoggingService {
// implementation of the methods omitted
}
@Singleton
public class ConsoleLoggingServiceImpl implements LoggingService {
// implementation of methods omitted
}
The LoggingService interface defines some methods. The default implementation is the ConsoleLoggingServiceImpl, which is applied to all environments. The FileLoggingServiceImpl class overrides the default implementation in production and canary-production environments.
5. Using the Micronaut Environments in Practice
Other than the environment-specific properties and beans, we can use the environments in some more cases. By injecting the Environment variable and using the getActiveNames() method, we can check in our code what the active environments are and alter some implementation details:
if (environment.getActiveNames().contains("production")
|| environment.getActiveNames().contains("canary-production")) {
sendAuditEvent();
}
This snippet of code checks if the environment is production or canary-production and invokes the sendAuditEvent() method only in those two. This is of course a bad practice. Instead, we should use the strategy design pattern or specific beans, as demonstrated earlier.
But we still have the option. Some scenario that would be more common is to use this code in tests since our test code is sometimes simpler rather than cleaner:
This is a snippet of a test that might receive a 500 status response on the local environment because the service isn’t handling some error requests. On the other hand, a 400 status response is given on deployed environments, because the API Gateway responds before the request makes it to the service.
6. Conclusion
In this article, we learned about the Micronaut environments. We went through the main concepts, and similarities to Spring profiles and listed the different ways we can set the active environments. Then, we saw how to resolve environment-specific beans and properties in cases of multiple environments set or none set. Last, we discussed how to use environments directly in our code, which is usually not a good practice.
As always, all the source code is available over on GitHub.