1. Overview
When building our persistence layer with Hibernate and working with timestamp fields, we often need to handle timezone details as well. Since Java 8, the most common approach to represent timestamps with timezone is by using the OffsetDateTime and ZonedDateTime classes. However, storing them in our database is a challenge since they’re not valid attribute types according to the JPA specification.
Hibernate 6 introduces the @TimeZoneStorage annotation to address the above challenge. This annotation provides flexible options for configuring how timezone information is stored and retrieved in our database.
In this tutorial, we’ll explore Hibernate’s @TimeZoneStorage annotation and its various storage strategies. We’ll walk through practical examples and look at the behavior of each strategy, enabling us to choose the best one for our specific needs.
2. Application Setup
Before we explore the @TimeZoneStorage annotation in Hibernate, let’s set up a simple application that we’ll use throughout this tutorial.
2.1. Dependencies
Let’s start by adding the Hibernate dependency to our project’s pom.xml file:
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.6.0.Final</version>
</dependency>This dependency provides us with the core Hibernate ORM functionality, including the @TimeZoneStorage annotation we’re discussing in this tutorial.
2.2. Defining the Entity Class and Repository Layer
Now, let’s define our entity class:
@Entity
@Table(name = "astronomical_observations")
class AstronomicalObservation {
@Id
private UUID id;
private String celestialObjectName;
private ZonedDateTime observationStartTime;
private OffsetDateTime peakVisibilityTime;
private ZonedDateTime nextExpectedAppearance;
private OffsetDateTime lastRecordedSighting;
// standard setters and getters
}For our demonstration, we’ll wear our astronomy geek hats. The AstronomicalObservation class is the central entity in our example, and we’ll be using it to learn how the @TimeZoneStorage annotation works in the upcoming sections.
With our entity class defined, let’s create its corresponding repository interface:
@Repository
interface AstronomicalObservationRepository extends JpaRepository<AstronomicalObservation, UUID> {
}Our AstronomicalObservationRepository interface extends JpaRepository and will allow us to interact with our database.
2.3. Enabling SQL Logging
To better understand how @TimeZoneStorage works under the hood, let’s enable SQL logging in our application by adding the corresponding configuration to our application.yml file:
logging:
level:
org:
hibernate:
SQL: DEBUG
orm:
results: DEBUG
jdbc:
bind: TRACE
type:
descriptor:
sql:
BasicBinder: TRACEWith this setup, we’ll be able to see the exact SQL that Hibernate generates for our AstronomicalObservation entity.
It’s important to note that the above configuration is for our practical demonstration and isn’t intended for production use.
3. @TimeZoneStorage Strategies
Now that we’ve set up our application, let’s take a look at the different storage strategies available when using the @TimeZoneStorage annotation.
3.1. NATIVE
Before we look at the NATIVE strategy, let’s talk about the TIMESTAMP WITH TIME ZONE data type. It’s a SQL standard data type that has the ability to store both the timestamp and the timezone information. However, not all database vendors support it. PostgreSQL and Oracle are popular databases that do support it.
Let’s annotate our observationStartTime field with @TimeZoneStorage and use the NATIVE strategy:
@TimeZoneStorage(TimeZoneStorageType.NATIVE)
private ZonedDateTime observationStartTime;When we use the NATIVE strategy, Hibernate stores our ZonedDateTime or OffsetDateTime value directly in a column of type TIMESTAMP WITH TIME ZONE. Let’s see this in action:
AstronomicalObservation observation = new AstronomicalObservation();
observation.setId(UUID.randomUUID());
observation.setCelestialObjectName("test-planet");
observation.setObservationStartTime(ZonedDateTime.now());
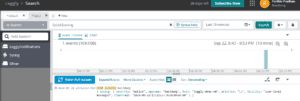
astronomicalObservationRepository.save(observation);Let’s take a look at the generated logs when we execute the above code to save a new AstronomicalObservation object:
org.hibernate.SQL : insert into astronomical_observations (id, celestial_object_name, observation_start_time) values (?, ?, ?)
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [ffc2f72d-bcfe-38bc-80af-288d9fcb9bb0]
org.hibernate.orm.jdbc.bind : binding parameter (2:VARCHAR) <- [test-planet]
org.hibernate.orm.jdbc.bind : binding parameter (3:TIMESTAMP_WITH_TIMEZONE) <- [2024-09-18T17:52:46.759673+05:30[Asia/Kolkata]]As is evident from the logs, our ZonedDateTime value is mapped directly to the TIMESTAMP_WITH_TIMEZONE column, preserving the timezone information.
If our database supports this data type, then the NATIVE strategy is recommended for storing timestamps with timezone.
3.2. COLUMN
The COLUMN strategy stores the timestamp and the timezone offset in separate table columns. The timezone offset is stored in a column with type INTEGER.
Let’s use this strategy on the peakVisibilityTime attribute of our AstronomicalObservation entity class:
@TimeZoneStorage(TimeZoneStorageType.COLUMN)
@TimeZoneColumn(name = "peak_visibility_time_offset")
private OffsetDateTime peakVisibilityTime;
@Column(name = "peak_visibility_time_offset", insertable = false, updatable = false)
private Integer peakVisibilityTimeOffset;We also declare a new peakVisibilityTimeOffset attribute and use the @TimeZoneColumn annotation to tell Hibernate to use it for storing the timezone offset. Then, we set the insertable and updatable attributes to false, which is necessary here to prevent a mapping conflict as Hibernate manages it through the @TimeZoneColumn annotation.
If we don’t use the @TimeZoneColumn annotation, Hibernate assumes the timezone offset column name is suffixed by _tz. In our example, it would be peak_visibility_time_tz.
Now, let’s see what happens when we save our AstronomicalObservation entity with the COLUMN strategy:
AstronomicalObservation observation = new AstronomicalObservation();
observation.setId(UUID.randomUUID());
observation.setCelestialObjectName("test-planet");
observation.setPeakVisibilityTime(OffsetDateTime.now());
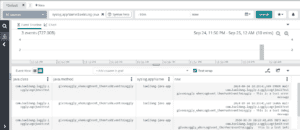
astronomicalObservationRepository.save(observation);Let’s analyse the logs that are generated when we execute the above:
org.hibernate.SQL : insert into astronomical_observations (id, celestial_object_name, peak_visibility_time, peak_visibility_time_offset) values (?, ?, ?, ?)
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [82d0a618-dd11-4354-8c99-ef2d2603cacf]
org.hibernate.orm.jdbc.bind : binding parameter (2:VARCHAR) <- [test-planet]
org.hibernate.orm.jdbc.bind : binding parameter (3:TIMESTAMP_UTC) <- [2024-09-18T12:37:43.441296Z]
org.hibernate.orm.jdbc.bind : binding parameter (4:INTEGER) <- [+05:30]We can see that Hibernate stores the timestamp without timezone in our peak_visibility_time column and the timezone offset in our peak_visibility_time_offset column.
If our database doesn’t support the TIMESTAMP WITH TIME ZONE data type, the COLUMN strategy is recommended to be used. Also, we need to ensure that the column for storing the timezone offset is present in our table schema.
3.3. NORMALIZE
Next, we’ll take a look at the NORMALIZE strategy. When we use this strategy, Hibernate normalizes the timestamp to our application’s local timezone and stores the timestamp value without the timezone information. When we fetch the record from the database, Hibernate adds our local timezone to the timestamp value.
Let’s take a closer look at this behavior. First, let’s annotate our nextExpectedAppearance attribute with @TimeZoneStorage and specify the NORMALIZE strategy:
@TimeZoneStorage(TimeZoneStorageType.NORMALIZE)
private ZonedDateTime nextExpectedAppearance;Now, let’s save an AstronomicalObservation entity and analyze the SQL logs to understand what’s happening:
TimeZone.setDefault(TimeZone.getTimeZone("Asia/Kolkata")); // UTC+05:30
AstronomicalObservation observation = new AstronomicalObservation();
observation.setId(UUID.randomUUID());
observation.setCelestialObjectName("test-planet");
observation.setNextExpectedAppearance(ZonedDateTime.of(1999, 12, 25, 18, 0, 0, 0, ZoneId.of("UTC+8")));
astronomicalObservationRepository.save(observation);We first set our application’s default timezone to Asia/Kolkata (UTC+05:30). Then, we create a new AstronomicalObservation entity and set its nextExpectedAppearance to a ZonedDateTime that has a timezone of UTC+8. Finally, we save the entity in our database.
Before we execute our above code and analyse the logs, we’ll need to add some extra logging for Hibernate’s ResourceRegistryStandardImpl class to our application.yaml file:
logging:
level:
org:
hibernate:
resource:
jdbc:
internal:
ResourceRegistryStandardImpl: TRACEOnce we’ve added the above configuration, we’ll execute our code and see the following logs:
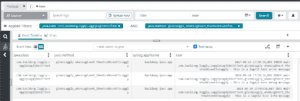
org.hibernate.SQL : insert into astronomical_observations (id, celestial_object_name, next_expected_appearance) values (?, ?, ?)
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [938bafb9-20a7-42f0-b865-dfaca7c088f5]
org.hibernate.orm.jdbc.bind : binding parameter (2:VARCHAR) <- [test-planet]
org.hibernate.orm.jdbc.bind : binding parameter (3:TIMESTAMP) <- [1999-12-25T18:00+08:00[UTC+08:00]]
o.h.r.j.i.ResourceRegistryStandardImpl : Releasing statement [HikariProxyPreparedStatement@971578330 wrapping prep1: insert into astronomical_observations (id, celestial_object_name, next_expected_appearance) values (?, ?, ?) {1: UUID '938bafb9-20a7-42f0-b865-dfaca7c088f5', 2: 'test-planet', 3: TIMESTAMP '1999-12-25 15:30:00'}]We can see that our timestamp 1999-12-25T18:00+08:00 got normalized to our application’s local timezone of Asia/Kolkata and stored as 1999-12-25 15:30:00. Hibernate removed the timezone information from the timestamp by subtracting 2.5 hours, which is the difference between the original timezone (UTC+8) and the application’s local timezone (UTC+5:30), resulting in the stored time of 15:30.
Now, let’s fetch our saved entity from the database:
astronomicalObservationRepository.findById(observation.getId()).orElseThrow();We’ll see the following logs when we execute the above fetch operation:
org.hibernate.SQL : select ao1_0.id, ao1_0.celestial_object_name, ao1_0.next_expected_appearance from astronomical_observations ao1_0 where ao1_0.id=?
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [938bafb9-20a7-42f0-b865-dfaca7c088f5]
org.hibernate.orm.results : Extracted JDBC value [1] - [test-planet]
org.hibernate.orm.results : Extracted JDBC value [2] - [1999-12-25T15:30+05:30[Asia/Kolkata]]Hibernate reconstructs the ZonedDateTime value and adds our application’s local timezone of +05:30. As we can see, this value is not in the UTC+8 timezone that we’d stored.
We need to be careful of using this strategy when our application runs in multiple timezones. For example, when running multiple instances of our application behind a load balancer, we need to ensure that our instances have the same default timezone to avoid inconsistencies.
3.4. NORMALIZE_UTC
The NORMALIZE_UTC strategy is similar to the NORMALIZE strategy we explored in the previous section. The only difference is that instead of using our application’s local timezone, it always normalizes the timestamps to UTC.
Let’s see how this strategy works. We’ll specify it on the lastRecordingSighting attribute of our AstronomicalObservation class:
@TimeZoneStorage(TimeZoneStorageType.NORMALIZE_UTC)
private OffsetDateTime lastRecordedSighting;Now, let’s save an AstronomicalObservation entity with its lastRecordedSighting attribute set to an OffsetDateTime with a UTC+8 offset:
AstronomicalObservation observation = new AstronomicalObservation();
observation.setId(UUID.randomUUID());
observation.setCelestialObjectName("test-planet");
observation.setLastRecordedSighting(OffsetDateTime.of(1999, 12, 25, 18, 0, 0, 0, ZoneOffset.ofHours(8)));
astronomicalObservationRepository.save(observation);Upon executing our code, let’s look at the generated logs:
org.hibernate.SQL : insert into astronomical_observations (id,celestial_object_name,last_recorded_sighting) values (?,?,?)
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [c843a9db-45c7-44c7-a2de-f5f0c8947449]
org.hibernate.orm.jdbc.bind : binding parameter (2:VARCHAR) <- [test-planet]
org.hibernate.orm.jdbc.bind : binding parameter (3:TIMESTAMP_UTC) <- [1999-12-25T18:00+08:00]
o.h.r.j.i.ResourceRegistryStandardImpl : Releasing statement [HikariProxyPreparedStatement@1938138927 wrapping prep1: insert into astronomical_observations (id,celestial_object_name,last_recorded_sighting) values (?,?,?) {1: UUID 'c843a9db-45c7-44c7-a2de-f5f0c8947449', 2: 'test-planet', 3: TIMESTAMP WITH TIME ZONE '1999-12-25 10:00:00+00'}]From the logs, we can see that Hibernate normalized our OffsetDateTime of 1999-12-25T18:00+08:00 to 1999-12-25 10:00:00+00 in UTC by subtracting eight hours before storing it in the database.
To ensure that the local timezone offset is not added to the timestamp value when we retrieve it from the database, let’s look at the logs generated when we fetch our earlier saved object:
org.hibernate.SQL : select ao1_0.id,ao1_0.celestial_object_name,ao1_0.last_recorded_sighting from astronomical_observations ao1_0 where ao1_0.id=?
org.hibernate.orm.jdbc.bind : binding parameter (1:UUID) <- [9fd6cc61-ab7e-490b-aeca-954505f52603]
org.hibernate.orm.results : Extracted JDBC value [1] - [test-planet]
org.hibernate.orm.results : Extracted JDBC value [2] - [1999-12-25T10:00Z]While we lose the original timezone information of UTC+8, the OffsetDateTime still represents the same instant in time.
3.5. AUTO
The AUTO strategy lets Hibernate choose the appropriate strategy based on our database.
If our database supports the TIMESTAMP WITH TIME ZONE data type, Hibernate will use the NATIVE strategy. Otherwise, it’ll use the COLUMN strategy.
In most cases, we’d be aware of the database we’re using, so it’s generally a good idea to explicitly use the appropriate strategy instead of relying on the AUTO strategy.
3.6. DEFAULT
The DEFAULT strategy is a lot like the AUTO strategy. It lets Hibernate choose the appropriate strategy based on the database we’re using.
If our database supports the TIMESTAMP WITH TIME ZONE data type, Hibernate will use the NATIVE strategy. Otherwise, it’ll use the NORMALIZE_UTC strategy.
Again, it’s usually a good idea to explicitly use the appropriate strategy when we know what database we’re using.
4. Conclusion
In this article, we’ve explored using Hibernate’s @TimeZoneStorage annotation to persist timestamps with timezone details in our database.
We looked at the various storage strategies available when using @TimeZoneStorage annotation on our OffsetDateTime and ZonedDateTime fields. We saw the behavior of each strategy by analyzing the SQL log statements it generates.
As always, all the code examples used in this article are available over on GitHub.