1. Introduction
In this tutorial, we're going to take an in-depth look at the Tomcat Manager Application. In a nutshell, the Tomcat Manager App is a web application that is packaged with the Tomcat server and provides us with the basic functionality we need to manage our deployed web applications.
As we're going to see, the application has many features and services. Besides allowing us to manage deployed applications, we can also see the status and configuration of the server and its applications.
2. Installing Tomcat
Before we delve into the Tomcat Manager App, we first need to install a Tomcat server.
Fortunately, installing Tomcat is an easy process. Please refer to our Introduction to Apache Tomcat guide for help installing Tomcat. In this tutorial, we'll be using the latest Tomcat 9 version.
3. Accessing the Tomcat Manager App
Now, let's take a look at how to use the Tomcat Manager App. We have two options here — we can choose to use the web-based (HTML) application or the text-based web service.
The text-based service is ideal for scripting, whereas the HTML application is designed for humans.
The web-based application is available at:
- http[s]://<server>:<port>/manager/html/
While the corresponding text service is available at:
- http[s]://<server>:<port>/manager/text/
However, before we can access these services, we need to configure Tomcat. By default, it can only be accessed by users with the correct permissions.
Let's go ahead and add such users by editing the conf/tomcat-users file:
<tomcat-users>
<role rolename="manager-gui"/>
<role rolename="manager-script"/>
<user username="tomcatgui" password="s3cret" roles="manager-gui"/>
<user username="tomcattext" password="baeldung" roles="manager-script"/>
</tomcat-users>
As we can see, we added two new users:
- tomcatgui – has the manager-gui role and can use the web-based application
- tomcattext – has the manager-script role and can use the text-based web service
In the next section, we'll see how we can use these two users to demonstrate the capabilities of the Tomcat Manager App.
4. Listing Currently Deployed Applications
In this section, we'll learn how to see a list of the currently deployed applications.
4.1. Using the Web
Let's open http://localhost:8080/manager/html/ to view the Tomcat Manager App webpage. We need to authenticate as the tomcatgui user to do so.
Once logged in, the web page lists all the deployed applications at the top of the page. For each application, we can see if it is running or not, the context path, and the number of active sessions. There are also several buttons we can use to manage the applications:
![Tomcat Manager app list applications]()
4.2. Using the Text Service
Alternatively, we can list all the deployed applications using the text web service. This time we make a curl request using the tomcattext user to authenticate:
curl -u tomcattext:baeldung http://localhost:8080/manager/text/list
Just like the web page, the response shows all the deployed applications with their current state and number of active sessions. For example, we can see the manager application is running and has one active session:
OK - Listed applications for virtual host [localhost]
/:running:0:ROOT
/examples:running:0:examples
/host-manager:running:0:host-manager
/manager:running:1:manager
/docs:running:0:docs
5. Managing Applications
One of the key pieces of functionality that the Tomcat Manager App allows us to do is stop, start, and reload applications.
5.1. Using the Web
In the case of the web application, stopping and starting the applications is just a matter of clicking the buttons on the web page. The outcome and any problems are reported in the message field at the top of the page.
5.2. Using the Text Service
Likewise, we can stop and start applications using the text service. Let's stop and then start the examples application using a curl request:
curl -u tomcattext:baeldung http://localhost:8080/manager/text/stop?path=/examples
OK - Stopped application at context path [/examples]
curl -u tomcattext:baeldung http://localhost:8080/manager/text/start?path=/examples
OK - Started application at context path [/examples]
The path query parameter indicates which application to manage and must match the context path of the application.
We can also reload applications to pick up changes to classes or resources. However, this only works for applications that are unpacked into a directory and not deployed as WAR files.
Here is an example of how we can reload the docs application using the text service:
curl -u tomcattext:baeldung http://localhost:8080/manager/text/reload?path=/docs
OK - Reloaded application at context path [/docs]
Remember, though, we only need to click the reload button to achieve the same in the web application.
6. Expiring Sessions
In addition to managing applications, we can manage user sessions. The Tomcat Manager App shows details on current user sessions and allows us to expire sessions manually.
6.1. Via the Web Interface
We can view current user sessions by following the link in the Sessions column for all listed applications.
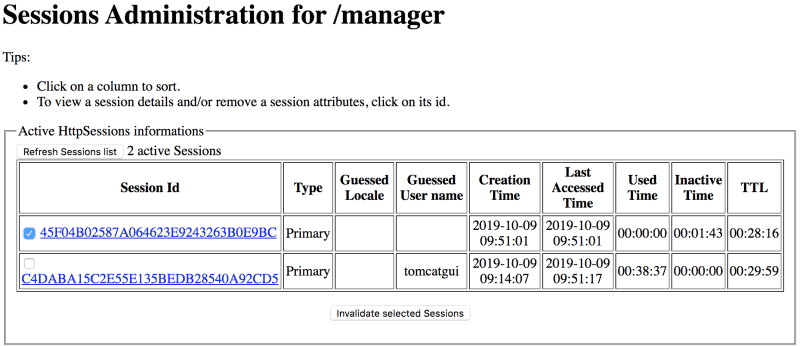
In the example below, we can see there are two user sessions for the manager application. It shows the duration of the session, how long it has been inactive, and how long until it expires (30 minutes by default).
We can also manually destroy sessions by selecting them and choosing Invalidate selected sessions:
![Tomcat Manager app user sessions]()
On the home page, there is a button to Expire sessions. This also destroys sessions that have been idle for the specified period of minutes.
6.2. Via the Text Web Service
Again, the text service equivalents are straightforward.
To view details on current user sessions, we call the session endpoint with the context path of the application we are interested in. In this example, we can see there are currently two sessions for the manager application:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/sessions?path=/manager"
OK - Session information for application at context path [/manager]
Default maximum session inactive interval is [30] minutes
Inactive for [2 - <3] minutes: [1] sessions
Inactive for [13 - <14] minutes: [1] sessions
If we want to destroy inactive user sessions, then we use the expire endpoint. In this example, we expire sessions that have been inactive for more than 10 minutes for the manager application:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/expire?path=/manager&idle=10"
OK - Session information for application at context path [/manager]
Default maximum session inactive interval is [30] minutes
Inactive for [5 - <6] minutes: [1] sessions
Inactive for [15 - <16] minutes: [1] sessions
Inactive for [>10] minutes: [1] sessions were expired
7. Deploying Applications
Now that we have seen how we can manage our applications, let's see how we can deploy new applications.
To get started, download the Tomcat sample WAR so we have a new application to deploy.
7.1. Using the Web
Now, we have a few options to deploy our new sample WAR using the web page. The easiest method is to upload the sample WAR file and deploy it:
![Tomcat Manager app war deploy]()
The WAR is deployed with a context path matching the name of the WAR. If successful, the sample application is deployed, started, and displayed in the list of applications. If we follow the /sample link in the context path, we can view our running sample application:
![Tomcat Manager app sample application]()
So that we can deploy the same application again, let's click on the Undeploy button. As the name suggests, this will undeploy the application. Note that this also deletes all files and directories for the deployed application.
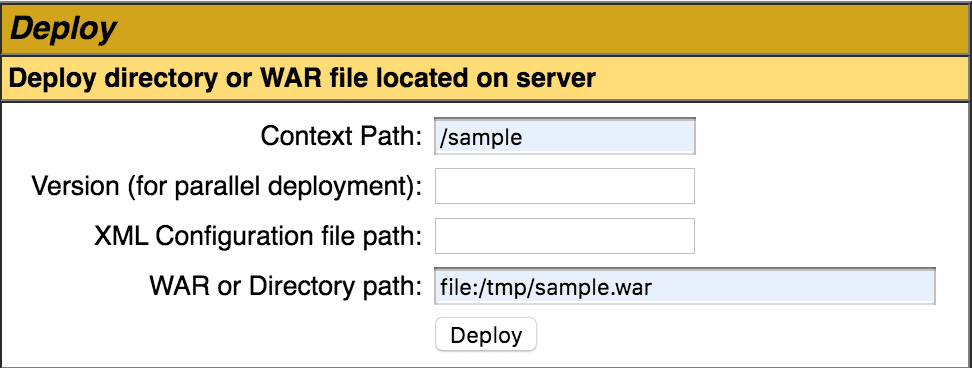
Next, we can deploy the sample WAR file by specifying the file path. We specify the file path URI to the WAR file or the unpacked directory plus the context path. In our case, the sample WAR is in the /tmp directory, and we are setting the context path to /sample:
![Tomcat Manager app path to war]()
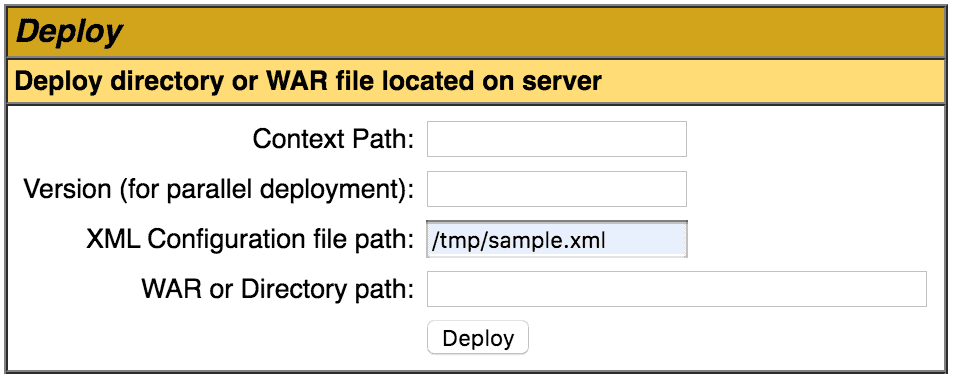
Alternatively, we can specify the file path to an XML deployment descriptor. This approach allows us to specify additional attributes affecting how the application is deployed and run. In the example below, we are deploying the sample WAR application and making it reloadable.
Note that any path specified in the deployment descriptor is ignored. The context path is taken from the file name of the deployment descriptor. Take a look at the Common Attributes to understand why, as well as a description of all the other possible attributes:
<Context docBase="/tmp/sample.war" reloadable="true" />
![Tomcat Manager app xml deployment descriptor]()
7.2. Using the Text Service
Now let's have a look at deploying applications using the text service.
Firstly, let's undeploy our sample application:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/undeploy?path=/sample"
OK - Undeployed application at context path [/sample]
To deploy it again, we specify the context path and the location URI of the sample WAR file:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/deploy?path=/sample&war=file:/tmp/sample.war"
OK - Deployed application at context path [/sample]
Furthermore, we can also deploy an application using the XML deployment descriptor:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/deploy?config=file:/tmp/sample.xml"
OK - Deployed application at context path [/sample]
8. Viewing SSL Configuration
We need to enable SSL in Tomcat before we can see any SSL configuration. First, let's create a new certificate keystore with a self-signed certificate in our Tomcat's conf directory:
keytool -genkey -alias tomcat -keyalg RSA -keystore conf/localhost-rsa.jks
Next, we change the conf/tomcat-server.xml file to enable the SSL connector in Tomcat:
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
maxThreads="150" SSLEnabled="true">
<SSLHostConfig>
<Certificate certificateKeystoreFile="conf/localhost-rsa.jks" type="RSA" />
</SSLHostConfig>
</Connector>
Once we restart Tomcat, we find it runs securely on port 8443!
8.1. Using the Web
Let's open https://localhost:8443/manager/html to see the Tomcat Manager App again. It should look exactly the same.
We can now view our SSL configuration using the buttons under Diagnostics:
![Tomcat Manager app TLS buttons]()
- The Ciphers button shows all the SSL ciphers understood by Tomcat
- Next, the Certificates button shows details of our self-signed certificate
- Finally, the Trusted Certificates button shows trusted CA certificate details; in our example, it does not display anything of interest as we have not added any trusted CA certificates
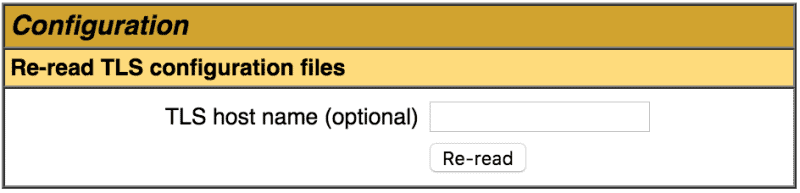
Also, the SSL configuration files can be dynamically re-loaded at any time. We can re-load per virtual host by entering the hostname. Otherwise, all configuration is re-read:
![Tomcat manager app re-load SSL]()
8.2. Using the Text Service
Likewise, we can get the same information using the text service. We can view all:
- SSL ciphers using the sslConnectorCiphers resource:
curl -ku tomcattext:baeldung "https://localhost:8443/manager/text/sslConnectorCiphers"
- Certificates using the sslConnectorCerts resource:
curl -ku tomcattext:baeldung "https://localhost:8443/manager/text/sslConnectorCerts"
- Trusted certificates using the sslConnectorTrustedCerts resource:
curl -ku tomcattext:baeldung "https://localhost:8443/manager/text/sslConnectorTrustedCerts"
The SSL configuration can be re-loaded using:
curl -ku tomcattext:baeldung "https://localhost:8443/manager/text/sslReload"
OK - Reloaded TLS configuration for all TLS virtual hosts
Note the -k option in the curl command as we are using a self-signed certificate.
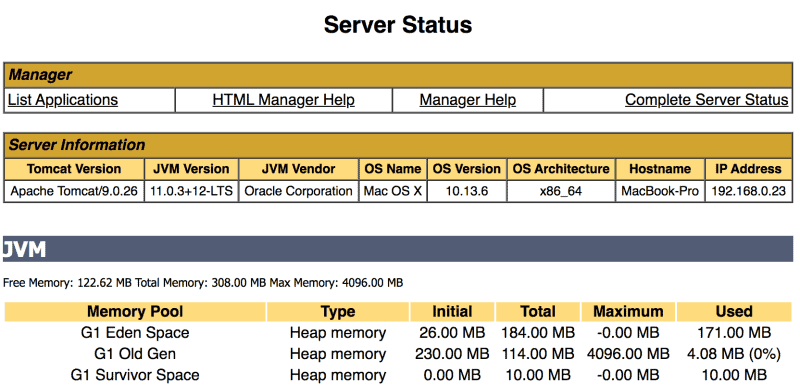
9. Viewing the Server Status
The Tomcat Manager App also shows us the status of the server and the deployed applications. These pages are particularly handy when we want to view overall usage statistics.
If we follow the Server Status link, displayed in the top right, we see details on the server. The Complete Server Status link shows additional details on the applications:
![Tomcat Manager app server status]()
There is no corresponding text service. However, we can modify the Server Status link to view the server status in XML. Unfortunately, doing the same for the Complete Server Status link may or may not work, depending on which Tomcat version we are using.
10. Saving Configuration
The text service allows us to save the current configuration to the Tomcat conf/server.xml. This is very useful if we have changed the configuration and want to save it for later use.
Thankfully, this also backs up the previous conf/server.xml, although any previous comments may be removed in the new conf/server.xml configuration file.
However, before we can do this, we need to add a new listener. Edit the conf/server.xml and add the following to the end of the list of the existing listeners:
<Listener className="org.apache.catalina.storeconfig.StoreConfigLifecycleListener" />
Once we've restarted Tomcat, we can save our configuration using:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/save"
OK - Server configuration saved
11. Diagnostics
Lastly, let's look at additional diagnostic features provided by the Tomcat Manager App.
11.1. Thread Dump
We can use the text service to get a thread dump of the running Tomcat server:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/threaddump"
OK - JVM thread dump
2019-10-06 23:19:10.066
Full thread dump Java HotSpot(TM) 64-Bit Server VM (11.0.3+12-LTS mixed mode):
...
This is particularly useful when we need to analyze or find threads that are causing performance issues, such as long-running or deadlocked threads.
11.2. Finding Memory Leaks
Tomcat generally does a good job of preventing memory leaks. But when we do suspect a memory leak, the Tomcat Manager App has a memory leak detection service to help us. It performs a full garbage collection and detects any classes still resident in memory since the last time the application was reloaded.
We only need to run the Find Leaks button on the web page to detect leaks.
Similarly, the text service can run memory leak detection:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/findleaks?statusLine=true"
OK - No memory leaks found
11.3. Displaying Available Resources
The text service provides a list of available resources. In this example, we see we have one in-memory database available:
curl -u tomcattext:baeldung "http://localhost:8080/manager/text/resources"
OK - Listed global resources of all types
UserDatabase:org.apache.catalina.users.MemoryUserDatabase
12. Conclusion
In this article, we’ve taken a detailed look at the Tomcat Manager App. We started by installing the application and seeing how to give access by configuring permissions for two distinct users.
Then we explored several examples using the web-based application and text-based web service. We saw how we could view, manage, and deploy applications using a variety of methods. Then we took a look at how to view the server's configuration and status.
To learn more about The Tomcat Manager App, check out the online documentation.
![]()




 – Boot 2.2 is out:
– Boot 2.2 is out: