1. Overview
Sometimes, when we compile our Java source, the compiler may print a warning message “unchecked conversion” or “The expression of type List needs unchecked conversion.”
In this tutorial, we're going to take a deeper look at the warning message. We'll discuss what this warning means, what problem it can lead to, and how to solve the potential problem.
2. Enabling the Unchecked Warning Option
Before we look into the “unchecked conversion” warning, let's make sure that the Java compiler option to print this warning has been enabled.
If we're using the Eclipse JDT Compiler, this warning is enabled by default.
When we're using the Oracle or OpenJDK javac compiler, we can enable this warning by adding the compiler option -Xlint:unchecked.
Usually, we write and build our Java program in an IDE. We can add this option in the IDE's compiler settings.
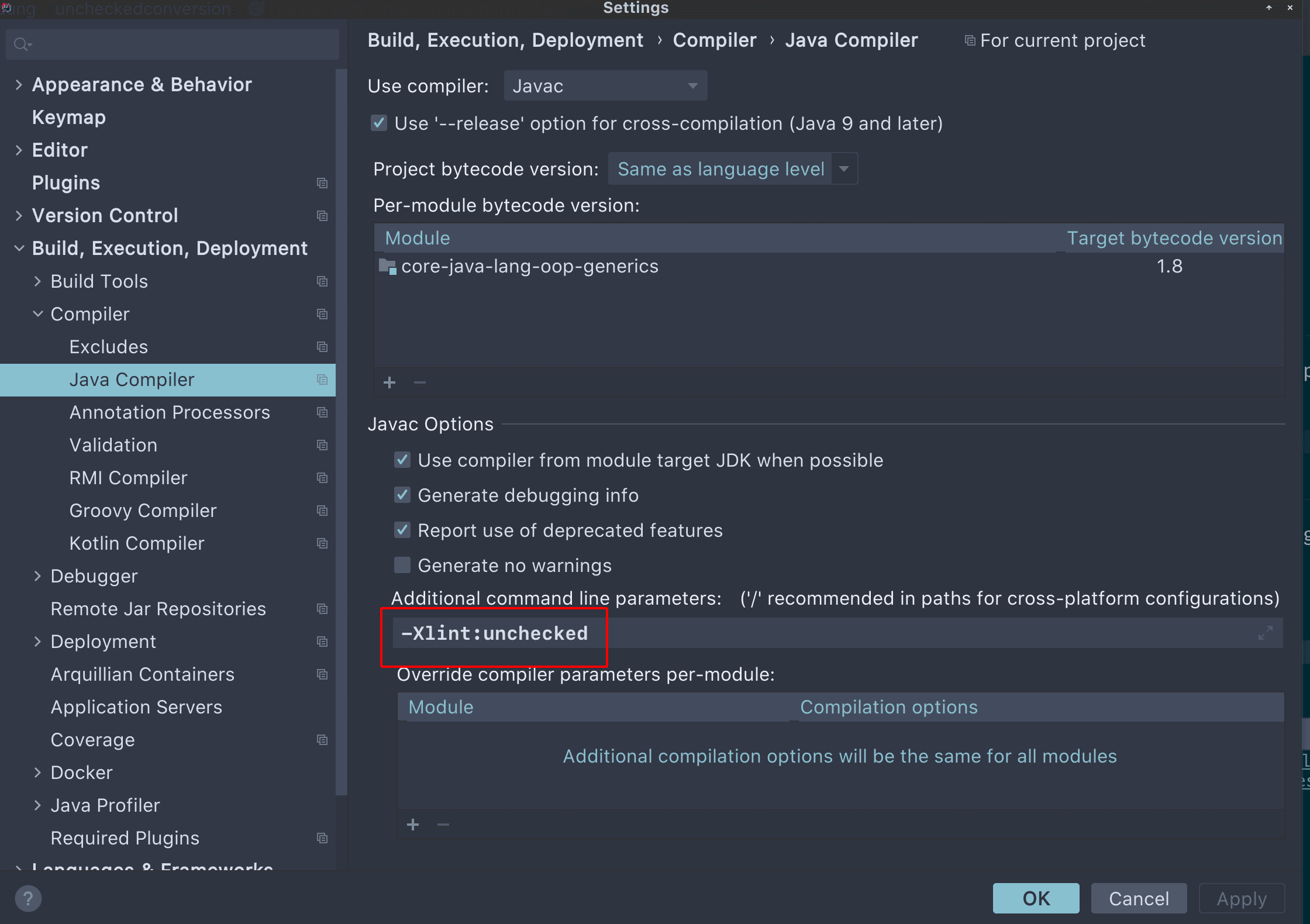
For example, the screenshot below shows how this warning is enabled in JetBrains IntelliJ:
Apache Maven is a widely used tool for building Java applications. We can configure maven-compiler-plugin‘s compilerArguments to enable this option:
<build>
...
<plugins>
...
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
...
<configuration>
...
<compilerArguments>
<Xlint:unchecked/>
</compilerArguments>
</configuration>
</plugin>
</plugins>
</build>
Now that we've confirmed that our Java compiler has this warning option enabled, let's take a closer look at this warning.
3. When Will the Compiler Warn Us: “unchecked conversion“?
In the previous section, we've learned how to enable the warning by setting the Java compiler option. Therefore, it's not hard to imagine that “unchecked conversion” is a compile-time warning. Usually, we'll see this warning when assigning a raw type to a parameterized type without type checking.
This assignment is allowed by the compiler because the compiler has to allow this assignment to preserve backward compatibility with older Java versions that do not support generics.
An example will explain it quickly. Let's say we have a simple method to return a raw type List:
public class UncheckedConversion {
public static List getRawList() {
List result = new ArrayList();
result.add("I am the 1st String.");
result.add("I am the 2nd String.");
result.add("I am the 3rd String.");
return result;
}
...
}
Next, let's create a test method that calls the method and assigns the result to a variable with type List<String>:
@Test
public void givenRawList_whenAssignToTypedList_shouldHaveCompilerWarning() {
List<String> fromRawList = UncheckedConversion.getRawList();
Assert.assertEquals(3, fromRawList.size());
Assert.assertEquals("I am the 1st String.", fromRawList.get(0));
}
Now, if we compile our test above, we'll see the warning from the Java compiler.
Let's build and test our program using Maven:
$ mvn clean test
...
[WARNING] .../UncheckedConversionDemoUnitTest.java:[12,66] unchecked conversion
required: java.util.List<java.lang.String>
found: java.util.List
...
[INFO] -------------------------------------------------------
[INFO] T E S T S
[INFO] -------------------------------------------------------
...
[INFO] Tests run: 13, Failures: 0, Errors: 0, Skipped: 0
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
...As the output above shows, we've reproduced the compiler warning.
A typical example in the real world is when we use Java Persistence API‘s Query.getResultList() method. The method returns a raw type List object.
However, when we try to assign the raw type list to a list with a parameterized type, we'll see this warning at compile-time:
List<MyEntity> results = entityManager.createNativeQuery("... SQL ...", MyEntity.class).getResultList();Moreover, we know that if the compiler warns us of something, it means there are potential risks. If we review the Maven output above, we'll see that although we get the “unchecked conversion” warning, our test method works without any problem.
Naturally, we may want to ask why the compiler warns us with this message and what potential problem we might have?
Next, let's figure it out.
4. Why Does the Java Compiler Warn Us?
Our test method works well in the previous section, even if we get the “unchecked conversion” warning. This is because the getRawList() method only adds Strings into the returned list.
Now, let's change the method a little bit:
public static List getRawListWithMixedTypes() {
List result = new ArrayList();
result.add("I am the 1st String.");
result.add("I am the 2nd String.");
result.add("I am the 3rd String.");
result.add(new Date());
return result;
}
In the new getRawListWithMixedTypes() method, we add a Date object to the returned list. It's allowed since we're returning a raw type list that can contain any types.
Next, let's create a new test method to call the getRawListWithMixedTypes() method and test the return value:
@Test(expected = ClassCastException.class)
public void givenRawList_whenListHasMixedType_shouldThrowClassCastException() {
List<String> fromRawList = UncheckedConversion.getRawListWithMixedTypes();
Assert.assertEquals(4, fromRawList.size());
Assert.assertFalse(fromRawList.get(3).endsWith("String."));
}
If we run the test method above, we'll see the “unchecked conversion” warning again, and the test will pass.
This means a ClassCastException has been thrown when we get the Date object by calling get(3) and attempt to cast its type to String.
In the real world, depending on the requirements, sometimes the exception is thrown too late.
For example, we assign List<String> strList = getRawListWithMixedTypes(). For each String object in strList, suppose that we use it in a pretty complex or expensive process such as external API calls or transactional database operations.
When we encounter the ClassCastException on an element in the strList, some elements have been processed. Thus, the ClassCastException comes too late and may lead to some extra restore or data cleanup processes.
So far, we've understood the potential risk behind the “unchecked conversion” warning. Next, let's see what we can do to avoid the risk.
5. What Shall We Do With the Warning?
If we're allowed to change the method that returns raw type collections, we should consider converting it into a generic method. In this way, type safety will be ensured.
However, it's likely that when we encounter the “unchecked conversion” warning, we're working with a method from an external library. Let's see what we can do in this case.
5.1. Suppressing the Warning
We can use the annotation SuppressWarnings(“unchecked”) to suppress the warning.
However, we should use the @SuppressWarnings(“unchecked”) annotation only if we're sure the typecast is safe because it merely suppresses the warning message without any type checking.
Let's see an example:
Query query = entityManager.createQuery("SELECT e.field1, e.field2, e.field3 FROM SomeEntity e");
@SuppressWarnings("unchecked")
List<Object[]> list = query.list();As we've mentioned earlier, JPA's Query.getResultList() method returns a raw typed List object. Based on our query, we're sure the raw type list can be cast to List<Object[]>. Therefore, we can add the @SuppressWarnings above the assignment statement to suppress the “unchecked conversion” warning.
5.2. Checking Type Conversion Before Using the Raw Type Collection
The warning message “unchecked conversion” implies that we should check the conversion before the assignment.
To check the type conversion, we can go through the raw type collection and cast every element to our parameterized type. In this way, if there are some elements with the wrong types, we can get ClassCastException before we really use the element.
We can build a generic method to do the type conversion. Depending on the specific requirement, we can handle ClassCastException in different ways.
First, let's say we'll filter out the elements that have the wrong types:
public static <T> List<T> castList(Class<? extends T> clazz, Collection<?> rawCollection) {
List<T> result = new ArrayList<>(rawCollection.size());
for (Object o : rawCollection) {
try {
result.add(clazz.cast(o));
} catch (ClassCastException e) {
// log the exception or other error handling
}
}
return result;
}
Let's test the castList() method above by a unit test method:
@Test
public void givenRawList_whenAssignToTypedListAfterCallingCastList_shouldOnlyHaveElementsWithExpectedType() {
List rawList = UncheckedConversion.getRawListWithMixedTypes();
List<String> strList = UncheckedConversion.castList(String.class, rawList);
Assert.assertEquals(4, rawList.size());
Assert.assertEquals("One element with the wrong type has been filtered out.", 3, strList.size());
Assert.assertTrue(strList.stream().allMatch(el -> el.endsWith("String.")));
}
When we build and execute the test method, the “unchecked conversion” warning is gone, and the test passes.
Of course, if it's required, we can change our castList() method to break out of the type conversion and throw ClassCastException immediately once a wrong type is detected:
public static <T> List<T> castList2(Class<? extends T> clazz, Collection<?> rawCollection)
throws ClassCastException {
List<T> result = new ArrayList<>(rawCollection.size());
for (Object o : rawCollection) {
result.add(clazz.cast(o));
}
return result;
}
As usual, let's create a unit test method to test the castList2() method:
@Test(expected = ClassCastException.class)
public void givenRawListWithWrongType_whenAssignToTypedListAfterCallingCastList2_shouldThrowException() {
List rawList = UncheckedConversion.getRawListWithMixedTypes();
UncheckedConversion.castList2(String.class, rawList);
}
The test method above will pass if we give it a run. It means that once there's an element with the wrong type in rawList, the castList2() method will stop the type conversion and throw ClassCastException.
6. Conclusion
In this article, we've learned what the “unchecked conversion” compiler warning is. Further, we've discussed the cause of this warning and how to avoid the potential risk.
As always, the code in this write-up is all available over on GitHub.
The post Java Warning “unchecked conversion” first appeared on Baeldung.